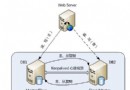
1.每個客戶端連接都會從服務器進程中分到一個屬於它的線程。而該連接的相應查詢都都會通過該線程處理。
2.服務器會緩存線程。因此並不會為每個新連接創建或者銷毀線程。
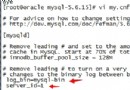
3.當發起對MySQL服務器的連接時,服務器會對 username,host,password進行驗證。而一旦連接上,服務器就會檢測其權限。
4.MySQL查詢緩存只會保存 SELECT 語句和相應的結果。在解析查詢之前會詢問查詢緩存,如果查詢緩存中能找到相應的結果就直接返回結果。
5.MySQL的 data 文件夾下會根據每個數據庫建立一個相應名稱的文件夾。而每一張表對應的有三個不同後綴的文件:.frm,.MYD,.MYI。其中 .frm 後綴的文件用來存儲表的定義。.MYD(mysql data)存儲的是數據,而.MYI(mysql index)存儲的是索引。
6.關於IP的存儲類型選擇。別再使用 varchar(15) 了,應該使用 INT UNSIGNED。而且最好是使用PHP的內置函數ip2long()和 long2ip() 來處理,而不是使用 MySQL 的函數 INET_ATON() 和 INET_NTOA()。盡可能地將計算和轉換之類的東西交給程序來完成。存儲為 INT 不僅節省了空間,而且利於查詢。比如我想要查詢出某個IP段的所有IP,varchar 是沒辦法進行的。
7. B+Tree 索引保存數據的順序和建表時的字段順序一致。InnoDB會自動在內存中為一些被頻繁訪問的索引值建立內存索引以加快速度。
8.以下查詢會引起索引失效:
復制代碼 代碼如下:
SELECT name FROM user WHERE id+1=4; // mysql不會從計算中去分析出id是有索引的
SELECT name FROM user WHERE TO_DAYS(birth) > 20; // mysql索引的是birth本身,而不是TO_DAYS()轉化之後的數據
1.復制表結構
CREATE TABLE b LIKE a;
2.更改存儲引擎
ALTER TABLE a ENGINE=InnoDB;
3.復制表數據
INSERT INTO b SELECT * FROM a;
4.獲取表信息
SHOW TABLE STATUS LIKE '%XXX%'; // 獲取表名符合LIKE的表信息。
SHOW TABLE STATUS FROM `數據庫名`; // 獲取該數據庫下所有表的信息
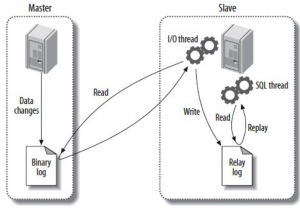
5.清空二進制日志
RESET MASTER;
6.返回某字段前X個字符
SELECT LEFT(name, 3) AS pre_name FROM user;
7.為某字段添加前綴索引
ALERT TABLE xxx ADD KEY (name(3));
8.避免讀取不必要的行,使用索引覆蓋查詢
SELECT * FROM JOIN (SELECT prod_id FROM products WHERE actor='SEAN CARREY' AND
title LIKE '%APOLLO%') AS t ON (t.prod_id=products.prod_id); // 其中actor有索引