1. 大批量亂序數據導入InnoDB很慢如何解決?
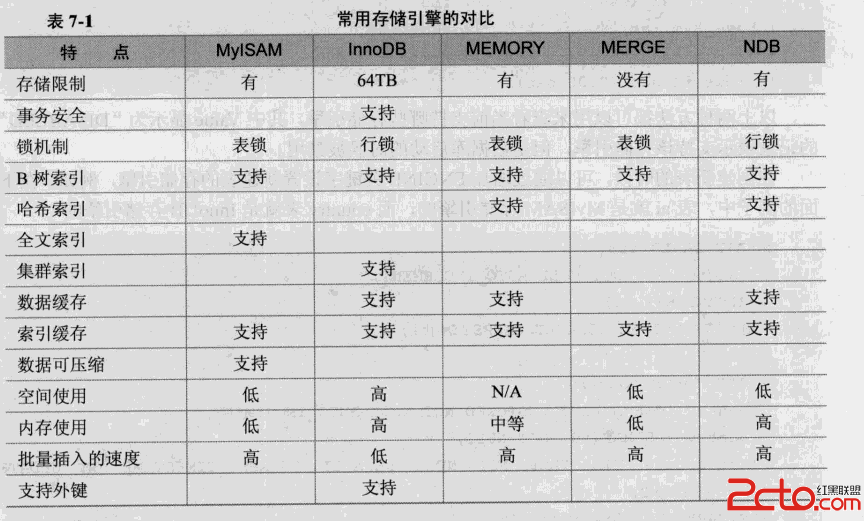
InnoDB因為主鍵聚集索引的關系,如果沒有主鍵或者主鍵非序列的情況下,導入會越來越慢,如何快速的遷移數據到InnoDB?借助MyISAM的力量 是很靠譜的,先關閉InnoDB的Buffer Pool,把內存空出來,建一張沒有任何索引的MyISAM表,然後只管插入吧,concurrent_insert=2,在文件末尾並發插入,速度剛剛 的,插入完成後,ALTER TABLE把索引加上,記得還有ENGINE=InnoDB,就把MyISAM轉到InnoDB了,這樣的速度遠比直接往InnoDB裡插亂序數據來得快。
2. 在基於ROW的雙Master復制下,如何快速大批量訂正?
在A<->B的雙Master結構下,假設只有一台提供服務,這是我們常用的架構,需要大批量訂正數據,如何做最快?用存儲過程一批批提交?這有很多的限制,有時候並不可以把一條或多條SQL拆成幾段,怎麼辦呢?binlog不是很好的工具嘛?! ROW格式的binlog,Slave在應用時是直接使用Handler API,並沒有走SQL解析,速度非常快,基本上是IO操作了,那麼我們可以在備庫上直接執行訂正SQL,產生的ROW binlog傳到主機,就會很快訂正完,基本上都比寫存儲過程快。
3. ROW格式Replication如何實現不帶庫名的replicate-do-db?
雖然MySQL有replicate-do-db這個參數,但是在ROW格式的binlog下必須使用”db.table”的方式才能生效,USE對ROW格式是無效的。現在我有一個Instance,只需要復制Master的某幾個庫,但是是ROW格式,SQL都 沒有使用db前綴,怎麼辦?可以這麼做,把主庫需要的庫導出來,不需要的庫導出結構即可,在Slave導入這些數據及結構,配置skip-slave- errors=all,這樣Master復制過來的binlog,只要發現有庫有表結構,就不會報找不到表,就不會阻塞復制,但是 UPDATE/DELETE過來沒有數據也會被跳過錯誤,間接的實現了replicate-do-db。
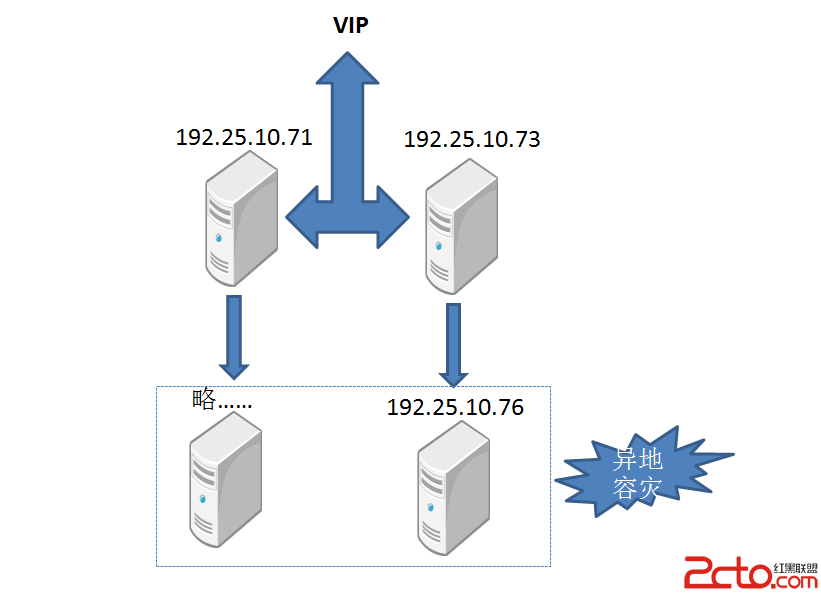
4. A<–>B–>C–>D結構切換到A<–>B, C<–>D結構出現Slave_lag一直增常如何避免?
這種情況常見與一個雙Master集群分離出一套雙Master集群,例如從原集群分離一部分庫。過快的切換B–>C到C<–>D容易導致主備出現slave_lag,並且一直增長,原因在於A<–>B集群產生的SQL,隨同server_id帶到了C–>D這個M-S中,當A,B產生的SQL在C,D還沒消化完成就CHANGE MASTER為C<–>D時,會導致這寫SQL在C,D之間來回傳輸,因為C,D都認為這個SQL不是自己產生的,因而不銷毀,自己執行後寫入binlog,於是Slave_Lag就一直增長。
避免的方法很簡單,部分寫切到C後,先斷開B–>C的復制,等一會,看D上已經沒有Slave_Lag了,再CHANGE MASTER為C<–>D,這樣A,B傳過來的SQL都消化完了。
5. 表中存在很多重復數據時,如何刪除這些重復數據最快?
在需要給表中某些字段加唯一索引時,而字段中又存在需要重復清理數據的問題,不少DBA都應該遇到過。一般在處理時總是想在數據庫中只保留一條,其他的刪除,但是這樣的SQL寫出來總是效率不高,怎麼辦?其實可以轉換思路,把重復的都選出一條出來,存到一張臨時表,然後刪除原表中所有存在重復的,再把臨時表的數據庫全部插入原庫,這是比較通用並且高效的做法。