MySQL內存及虛擬內存優化設置參數。本站提示廣大學習愛好者:(MySQL內存及虛擬內存優化設置參數)文章只能為提供參考,不一定能成為您想要的結果。以下是MySQL內存及虛擬內存優化設置參數正文
MySql優化的普通步調:
1.經由過程show status 敕令懂得各類sql的履行效力
SHOW STATUS供給msyql辦事器的狀況信息
普通情形下,我們只須要懂得以”Com”開首的指令
show session status like ‘Com%':顯示以後的銜接的統計成果
show global status like ‘Com%' :顯示自數據庫前次啟動至今的統計成果
注:默許是session級其余
個中Com_XXX表現XXX語句所履行的次數。
重點留意:Com_select,Com_insert,Com_update,Com_delete經由過程這幾個參數,可以輕易地懂得到以後數據庫的運用是以插
入更新為主照樣以查詢操作為主,和各類的SQL年夜致的履行比例是若干。
別的,還有幾個參數須要留意下:
show status like ‘Connections'// 試圖銜接MySQL辦事器的次數
show status like ‘Uptime'//辦事器任務的時光(單元秒)
show status like ‘Slow_queries'//慢查詢的次數 (默許是10秒中就當作是慢查詢,以下圖所示)

a) 若何查詢mysql的慢查詢時光
Show variables like 'long_query_time';
b) 修正mysql 慢查詢時光
set long_query_time=2//假如查詢時光跨越2秒就算作是慢查詢
2. 定位履行效力較低的SQL語句(dql湧現成績的幾率較dml的年夜)
成績是:若何在一個項目中,找到慢查詢的select語句?
謎底:mysql支撐把慢查詢語句記載到日記文件中。法式員須要修正php.ini的設置裝備擺設文件,默許情形下,慢查詢記載是不開啟的。
開啟慢查詢記載的步調:
翻開 my.ini ,找到 [mysqld] 在其上面添加
long_query_time = 2
log-slow-queries = D:/mysql/logs/slow.log #設置把日記寫在那邊,可認為空,體系會給一個缺省的文件
例子:我們數據表中有1萬萬條的數據量
DQL語句:SELECT * FROM order_copy WHERE id=12345;

查詢耗時:19s>2s,所以mysql會將該條select語句記載到慢查詢日記中
SELECT * FROM order_copy WHERE id=12345的履行時光:
添加索引前:19s
添加索引後:0.08s
3.經由過程explain剖析低效力的SQL語句的履行情形
應用explain剖析該dql語句:
EXPLAIN SELECT * FROM order_copy WHERE id=12345
會發生以下信息:
select_type:表現查詢的類型。
table:輸入成果集的表
type:表現表的銜接類型(system和const為佳)
possible_keys:表現查詢時,能夠應用的索引
key:表現現實應用的索引
key_len:索引字段的長度
rows:掃描的行數
Extra:履行情形的描寫和解釋
留意:要盡可能防止讓type的成果為all,extra的成果為:using filesort

4.肯定成績並采用響應的優化辦法
經常使用的優化辦法是添加索引。添加索引,我們不消加內存,不消改法式,不消調sql,只需履行個准確的'create index',查詢速度便可能進步百倍千倍。然則世界沒有收費的午飯,查詢速度的進步是以拔出、更新、刪除的速度為價值的,這些寫操作,增長了年夜量的I/O。
例如:給字段id添加索引:
ALTER TABLE order_copy ADD PRIMARY KEY(id)
給1萬萬的數據添加primary key 須要耗時: 428秒(7分鐘)
EXPLAIN SELECT * FROM order_copy WHERE id=12345

恰是由於給id添加了索引,才使得rows的成果為1
然則索引其實不是可以隨意添加的,以下幾種情形需切記在心:
較頻仍的作為查詢前提字段應當創立索引
select * from order_copy where id = $id
獨一性太差的字段不合適零丁創立索引,即便頻仍作為查詢前提
select * from order_copy where sex='女'
更新異常頻仍的字段不合適創立索引
select * from order_copy where order_state='未付款'
不會湧現在WHERE子句中字段不應創立索引
索引的類型:
PRIMARY 索引 => 在主鍵上主動創立INDEX 索引 => 就是通俗索引UNIQUE 索引 => 相當於INDEX + UniqueFULLTEXT => 只在MYISAM 存儲引擎支撐, 目標是全文索引,在內容體系頂用的多, 在全英文網站用多(英文詞自力). 中文數據不經常使用,意義不年夜 國際全文索引平日 應用 sphinx 來完成.
索引的應用
樹立索引 create [UNIQUE|FULLTEXT] index index_name on tbl_name (col_name [(length)] [ASC | DESC] , …..);
alter table table_name ADD INDEX [index_name] (index_col_name,...)
添加主鍵(索引) ALTER TABLE 表名 ADD PRIMARY KEY(列名,..); 結合主鍵
刪除索引 DROP INDEX index_name ON tbl_name;
alter table table_name drop index index_name;刪除主鍵(索引)比擬特殊: alter table t_b drop primary key;查詢索引(都可) show index from table_name;
show keys from table_name;
desc table_Name;
以上就是小編為年夜家帶來的MySql的優化步調引見(推舉)全體內容了,願望年夜家多多支撐~
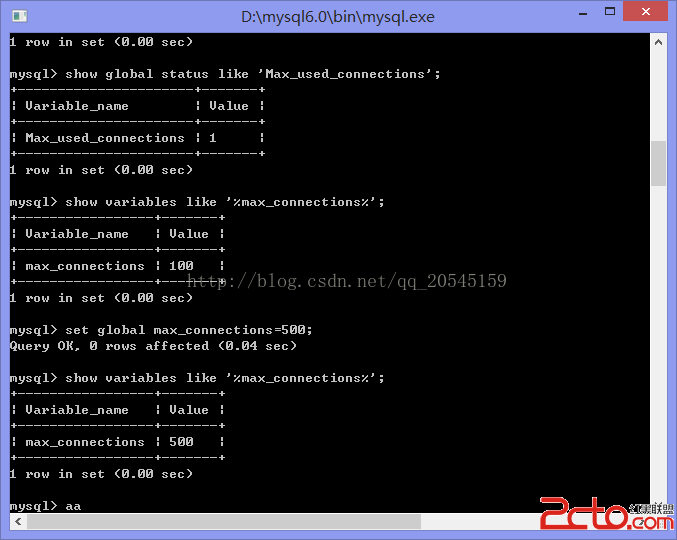
/> Query OK, 0 rows affected (0.00 sec)4)、back_log:
請求 mysql 能有的銜接數目。當重要mysql線程在一個很短時光內獲得異常多的銜接要求,這就起感化,然後主線程花些時光(雖然很短)檢討銜接而且啟動一個新線程。
back_log 值指出在mysql臨時停滯答復新要求之前的短時光內若干個要求可以被存在客棧中。只要假如希冀在一個短時光內有許多銜接,你須要增長它,換句話說,這值對到來的tcp/ip銜接的偵聽隊列的年夜小。你的操作體系在這個隊列年夜小上有它本身的限制。試圖設定back_log高於你的操作體系的限制將是有效的。
當你不雅察你的主機過程列表,發明年夜量 264084 | unauthenticated user | xxx.xxx.xxx.xxx | null | connect | null | login | null 的待銜接過程時,就要加年夜 back_log 的值了。默許數值是50,我把它改成500。
(5)、interactive_timeout:
辦事器在封閉它前在一個交互銜接上期待行為的秒數。一個交互的客戶被界說為對 mysql_real_connect()應用 client_interactive 選項的客戶。 默許數值是28800,我把它改成7200。
(6)、sort_buffer:
每一個須要停止排序的線程分派該年夜小的一個緩沖區。增長這值加快order by或group by操作。默許數值是2097144(2m),我把它改成 16777208 (16m)。
(7)、table_cache:
為一切線程翻開表的數目。增長該值能增長mysqld請求的文件描寫符的數目。mysql對每一個獨一翻開的表須要2個文件描寫符。默許數值是64,我把它改成512。
(8)、thread_cache_size:
可以復用的保留在中的線程的數目。假如有,新的線程從緩存中獲得,當斷開銜接的時刻假如有空間,客戶的線置在緩存中。假如有許多新的線程,為了進步機能可以這個變量值。經由過程比擬 connections 和 threads_created 狀況的變量,可以看到這個變量的感化。我把它設置為 80。
(9)mysql的搜刮功效
用mysql停止搜刮,目標是能不分年夜小寫,又能用中文停止搜刮
只需起動mysqld時指定 --default-character-set=gb2312
(10)、wait_timeout:
辦事器在封閉它之前在一個銜接上期待行為的秒數。 默許數值是28800,我把它改成7200。
(11)、innodb_thread_concurrency:
你的辦事器CPU有幾個就設置為幾,默許為8。
(12)、query_cache_size 與 query_cache_limit
QueryCache 以後所帶來的負面影響:
a) Query 語句的hash 運算和hash 查找資本消費。當我們應用Query Cache 以後,每條SELECT
類型的Query 在達到MySQL 以後,都須要停止一個hash 運算然後查找能否存在該Query 的
Cache,固然這個hash 運算的算法能夠曾經異常高效了,hash 查找的進程也曾經足夠的優化
了,關於一條Query 來講消費的資本確切長短常異常的少,然則當我們每秒都有上千乃至幾千
條Query 的時刻,我們就不克不及對發生的CPU 的消費完整疏忽了。
b) Query Cache 的掉效成績。假如我們的表變革比擬頻仍,則會形成Query Cache 的掉效力異常
高。這裡的表變革不只僅指表中數據的變革,還包含構造或許索引等的任何變革。也就是說我
們每次緩存到Query Cache 中的Cache 數據能夠在剛存入後很快就會由於表中的數據被轉變而被
消除,然後新的雷同Query 出去以後沒法應用到之前的Cache。
c) Query Cache 中緩存的是Result Set ,而不是數據頁,也就是說,存在統一筆記錄被Cache 多
次的能夠性存在。從而形成內存資本的過渡消費。固然,能夠有人會說我們可以限制Query
Cache 的年夜小啊。是的,我們確切可以限制Query Cache 的年夜小,然則如許,Query Cache 就很
輕易形成由於內存缺乏而被換出,形成射中率的降低。
QueryCache 的准確應用:
固然Query Cache 的應用會存在一些負面影響,然則我們也應當信任其存在是一定有必定價值。我
們完整不消由於Query Cache 的下面三個負面影響就完整掉去對Query Cache 的信念。只需我們懂得了
Query Cache 的完成道理,那末我們就完整可以經由過程必定的手腕在應用Query Cache 的時刻取長補短,重
發施展其優勢,並有用的避開其優勢。
起首,我們須要依據Query Cache 掉效機制來斷定哪些表合適應用Query 哪些表不合適。因為Query
Cache 的掉效重要是由於Query 所依附的Table 的數據產生了變更,形成Query 的Result Set 能夠曾經
有所轉變而形成相干的Query Cache 全體掉效,那末我們就應當防止在查詢變更頻仍的Table 的Query 上
應用,而應當在那些查詢變更頻率較小的Table 的Query 下面應用。MySQL 中針對Query Cache 有兩個專
用的SQL Hint(提醒):SQL_NO_CACHE 和SQL_CACHE,分離代表強迫不應用Query Cache 和強迫應用
Query Cache。我們完整可以應用這兩個SQL Hint,讓MySQL 曉得我們願望哪些SQL 應用Query Cache 而
哪些SQL 就不要應用了。如許不只可讓變更頻仍Table 的Query 糟蹋Query Cache 的內存,同時還可以
削減Query Cache 的檢丈量。
其次,關於那些變更異常小,年夜部門時刻都是靜態的數據,我們可以添加SQL_CACHE 的SQL Hint,
強迫MySQL 應用Query Cache,從而進步該表的查詢機能。
最初,有些SQL 的Result Set 很年夜,假如應用Query Cache 很輕易形成Cache 內存的缺乏,或許將
之前一些老的Cache 沖洗出去。關於這一類Query 我們有兩種辦法可以處理,一是應用SQL_NO_CACHE 參
數來強迫他不應用Query Cache 而每次都直接從現實數據中去查找, 另外一種辦法是經由過程設定
“query_cache_limit”參數值來掌握Query Cache 中所Cache 的最年夜Result Set ,體系默許為
1M(1048576)。當某個Query 的Result Set 年夜於“query_cache_limit”所設定的值的時刻,Query
Cache 是不會Cache 這個Query 的。
(13)、innodb_buffer_pool_size
innodb_buffer_pool_size 界說了 InnoDB 存儲引擎的表數據和索引數據的最年夜內存緩沖區年夜小。和 MyISAM 存儲引擎分歧, MyISAM 的 key_buffer_size 只能緩存索引鍵,而 innodb_buffer_pool_size 卻可以緩存數據塊和索引鍵。恰當的增長這個參數的年夜小,可以有用的削減 InnoDB 類型的表的磁盤 I/O 。在一個以 InnoDB 為主的公用數據庫辦事器上,可以斟酌把該參數設置為物理內存年夜小的 60%-80%
InnoDB占用的內存,除innodb_buffer_pool_size用於存儲頁面緩存數據外,別的正常情形下還有年夜約8%的開支,重要用在每一個緩存頁幀的描寫、adaptive hash等數據構造,假如不是平安封閉,啟動時還要恢復的話,還要另開年夜約12%的內存用於恢復,二者相加就有差不多21%的開支。
如許,12G的innodb_buffer_pool_size,最多的時刻InnoDB便可能占用到14.5G(12G X 21%)的內存,再加上操作體系用的幾百M,近千個線程客棧,就差不多16G了。
MAX_QUERIES_PER_HOUR 用來限制用戶每小時運轉的查詢數目:
mysql> grant all on dbname。* to db@localhost identified by “123456” with max_connections_per_hour 5;
(db用戶在dbname的數據庫上掌握用戶每小時翻開新銜接的數目為5個)
MAX_USER_CONNECTIONS 限制有若干用戶銜接MYSQL辦事器:
mysql> grant all on dbname。* to db@localhost identified by “123456” with max_user_connections 2;
(db用戶在dbname的數據庫賬戶一次可以同時銜接的最年夜銜接數為2個)
MAX_UPDATES_PER_HOUR 用來限制用戶每小時的修正數據庫數據的數目:
mysql> grant all on dbname。* to db@localhost identified by “123456” with max_updates_per_hour 5;
(db用戶在dbname的數據庫上掌握用戶每小時修正更新數據庫的次數為5次)
MAX_USER_CONNECTIONS 用來限制用戶每小時的修正數據庫數據的數目:
mysql> grant all on dbname。* to db@localhost identified by “123456”
With MAX_QUERIES_PER_HOUR 20 ;指mysql單個用戶的最年夜銜接數
(db用戶在dbname的數據庫上掌握用戶每小時的銜接數為20個)
調優舉例
針對my.cnf文件停止優化:
[mysqld]
skip-locking(撤消文件體系的內部鎖)
skip-name-resolve(不停止域名反解析,留意由此帶來的權限/受權成績)
key_buffer_size = 256M(分派給MyISAM索引緩存的內存總數)關於內存在4GB閣下的辦事器該參數可設置為256M或384M。
留意:該參數值設置的過年夜反而會是辦事器全體效力下降!
max_allowed_packet = 4M(許可最年夜的包年夜小)
thread_stack = 256K(每一個線程的年夜小)
table_cache = 128K(緩存可重用的線程數)
back_log = 384(暫時停滯呼應新要求前在短時光內可以堆起若干要求,假如你須要在短時光內許可年夜量銜接,可以增長該數值)
sort_buffer_size = 2M(分派給每一個線程中處置排序)
read_buffer_size = 2M(讀取的索引緩沖區年夜小)
join_buffer_size = 2M(分派給每一個線程中處置掃描表銜接及索引的內存)
myisam_sort_buffer_size = 64M(myisam引擎排序緩沖區的年夜小)
table_cache = 512(緩存數據表的數目,防止反復翻開表的開支)
thread_cache_size = 64(緩存可重用線程數,見笑創立新線程的開支)
query_cache_size = 64M(掌握分派給查詢緩存的內存總量)
tmp_table_size = 256M(指定mysql緩存的內存年夜小)
max_connections = 768(最年夜銜接數)指mysql全部的最年夜銜接數
max_connect_errors = 10000(最年夜銜接毛病數據)
wait_timeout = 10(超不時間,可以免進擊)
thread_concurrency = 8(依據cpu數目來設置)
skip-bdb 禁用不用要的引擎
skip-networking(封閉mysql tcp/ip銜接方法)
Log-slow-queries = /var/log/mysqlslowqueries.log
long_query_time = 4(設定慢查詢的時光)
skip-host-cache(進步mysql速度的)
open_files_limit = 4096(翻開文件數)
interactive_timeout = 10(辦事器在封閉它前在一個交互銜接上期待行為的秒數)
max_user_connections = 500(最年夜用戶銜接數)
key_buffer_size 默許為218 調到128最好
query_cache_size
tmp_table_size 默許為16M 調到64-256最掛
innodb_thread_concurrency=8 你的辦事器CPU有幾個就設置為幾,默許為8
table_cache=1024 物理內存越年夜,設置就越年夜.默許為2402,調到512-1024最好
innodb_additional_mem_pool_size=8M 默許為2M
innodb_flush_log_at_trx_commit=0 比及innodb_log_buffer_size排隊滿後再同一貯存,默許為1
innodb_log_buffer_size=4M 默許為1M
read_buffer_size=4M 默許為64K
read_rnd_buffer_size 隨機讀 緩存區 默許為256K
sort_buffer_size=32M 默許為256K
max_connections=1024 默許為1210
thread_cache_size=120 默許為60
機能測試
1、mysql 自帶測試對象
shell> perl -MCPAN -e shell
cpan> install DBI
cpan> install DBD::mysql
shell> cd sql-bench
shell> perl run-all-tests --server=server_name
server_name是一個支撐的辦事器。要取得一切選項和支撐的辦事器,挪用敕令:
shell> perl run-all-tests --help
2、mysqlreport
http://hackmysql.com/mysqlreport
參考文檔
http://dev.mysql.com/doc/refman/5.1/zh/optimization.html
http://hackmysql.com/tools
http://www.imysql.cn/