Mysql數據庫機能優化二。本站提示廣大學習愛好者:(Mysql數據庫機能優化二)文章只能為提供參考,不一定能成為您想要的結果。以下是Mysql數據庫機能優化二正文
在上篇文章給年夜家引見了mysql數據庫機能優化一,明天持續接著上篇文章給年夜家引見數據庫機能優化相干常識。詳細內容以下所示:
樹立恰當的索引
說起進步數據庫機能,索引是最物美價廉的器械了。不消加內存,不消改法式,不消調sql,只需履行個准確的'create index',查詢速度便可能進步百倍千倍,這可真有引誘力。可是世界沒有收費的午飯,查詢速度的進步是以拔出、更新、刪除的速度為價值的,這些寫操作,增長了年夜量的I/O。
是否是樹立一個索引就可以處理一切的成績?ename上沒有樹立索引會如何?
select * from emp where ename='研發部';
---測試案例敕令以下 (最好以 select * from emp e,dept d where e.empno=123451 )
*添加主鍵
ALTER TABLE emp ADD PRIMARY KEY(empno);
*刪除主鍵
alter table emp drop primary key;
索引的道理解釋
沒有索引為何會慢?
應用索引為何會快?
索引的價值
1、磁盤占用
2、對dml(update delete insert)語句的效力影響
btree 方法檢索,算法龐雜度: log2N 次數
哪些列上合適添加索引
1、較頻仍的作為查詢前提字段應當創立索引
select * from emp where empno = 1;
2、獨一性太差的字段不合適零丁創立索引,即便頻仍作為查詢前提
select * from emp where sex = '男'
3、更新異常頻仍的字段不合適創立索引
select * from emp where logincount = 1
4、不會湧現在WHERE子句中的字段不應創立索引
索引的類型
•主鍵索引,主鍵主動的為主索引 (類型Primary)
•獨一索引 (UNIQUE)
•通俗索引 (INDEX)
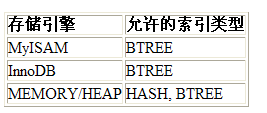
•全文索引 (FULLTEXT) [實用於MyISAM] ——》sphinx + 中文分詞 coreseek [sphinx 的中文版 ]
•綜合應用=>復合索引
簡述mysql四種索引的差別
lPRIMARY 索引 =》在主鍵上主動創立
lUNIQUE 索引=> 只需是UNiQUE 就是Unique索引.(只能在字段內容不反復的情形下,能力創立獨一索引)
lINDEX 索引=>就是通俗索引
lFULLTEXT => 只在MYISAM 存儲引擎支撐, 目標是全文索引,在內容體系頂用的多, 在全英文網站用多(英文詞自力). 中文數據不經常使用,意義不年夜,國際全文索引平日應用 sphinx來完成,全文索引只能在 char varchar text字段創立.
全文索引案例
1.創立表
create table news(id int , title varchar(32),con varchar(1024)) engine=MyISAM;
2.樹立全文索引
create fulltext index ful_inx on news (con);
3.拔出數據
這裡要留意,關於罕見的英文 fulltext 不會婚配,並且拔出的語句自己是准確的.
'but it often happens that they are not above supporting themselves by dishonest means.which should be more disreputable.Cultivate poverty like a garden herb'
4.看看婚配度
mysql> select match(con) against('poverty') from news;
+-------------------------------+
| match(con) against('poverty') |
+-------------------------------+
| 0 |
| 0 |
| 0 |
| 0.9853024482727051 |
+------------------------------+
0表現沒有婚配到,或許你的詞是停滯詞,是不會樹立索引的.
應用全文索引,不克不及應用like語句,如許就不會應用到全文索引了.
復合索引
create index 索引名 on 表名(列1,列2);
索引的應用
樹立索引
create [UNIQUE|FULLTEXT] index index_name on tbl_name (col_name [(length)] [ASC | DESC] , …..); alter table table_name ADD INDEX [index_name] (index_col_name,...) 添加主鍵(索引) ALTER TABLE 表名 ADD PRIMARY KEY(列名,..); 結合主鍵
刪除索引
DROP INDEX index_name ON tbl_name; alter table table_name drop index index_name; 刪除主鍵(索引)比擬特殊: alter table t_b drop primary key;
查詢索引(都可)
show index(es) from table_name; show keys from table_name; desc table_Name;
修正索引,我們普通是先刪除在從新創立.
查詢要應用索引最主要的前提是查詢前提中須要應用索引。
以下幾種情形下有能夠應用到索引:
1,關於創立的多列索引,只需查詢前提應用了最右邊的列,索引普通就會被應用。
2,關於應用like的查詢,查詢假如是 '%aaa' 不會應用到索引, 'aaa%' 會應用到索引。
以下的表將不應用索引:
1,假如前提中有or,即便個中有前提帶索引也不會應用。
2,關於多列索引,不是應用的第一部門,則不會應用索引。
3,like查詢是以%開首
4,假如列類型是字符串,那必定要在前提中將數據應用引號援用起來。不然不應用索引。(添加時,字符串必需'')
5,假如mysql估量應用全表掃描要比應用索引快,則不應用索引。
測試案例(就在後面的dept表上做演示.)
CREATE TABLE dept( deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, dname VARCHAR(20) NOT NULL DEFAULT "", loc VARCHAR(13) NOT NULL DEFAULT "" ) ENGINE=MyISAM DEFAULT CHARSET=utf8 ; --放入數據,後面應當曾經添加了,假如沒有則須要從新添加 --測試開端.
添加一個主鍵索引
alter table dept add primary key (deptno)
--測試語句
explain select * from dept where deptno=1;
成果是:
mysql> explain select * from dept where deptno=1; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: dept type: const possible_keys: PRIMARY key: PRIMARY key_len: 3 ref: const rows: 1 Extra: 1 row in set (0.00 sec)
--創立多列索引
alter table dept add index myind (dname,loc);
--證實關於創立的多列索引,只需查詢前提應用了最右邊的列,索引普通就會被應用
explain select * from dept where dname='研發部'; 會顯示應用到了索引myind explain select * from dept where loc='MsBDpMRX'; 不會顯示應用到了索引myind
--關於應用like的查詢
explain select * from dept where dname like '%研發部'; 不會顯示應用到了索引myind explain select * from dept where dname like '研發部%'; 會顯示應用到了索引myind
--假如前提中有or,即便個中有前提帶索引也不會應用
--為了演示,我們把復合索引刪除,然後只在dname上參加索引.
alter table dept drop index myind alter table dept add index myind (dname) explain select * from dept where dname='研發部' or loc='aa';-- 就不會應用到dname列上的
--假如列類型是字符串,那必定要在前提中將數據應用引號援用起來。不然不應用索引
select * from dept from dname=1234; //不會應用到索引 select * from dept from dname='1234'; //會應用到索引
檢查索引的應用情形
show status like 'Handler_read%';
年夜家可以留意:
handler_read_key:這個值越高越好,越高表現應用索引查詢到的次數。
handler_read_rnd_next:這個值越高,解釋查詢低效。
* 這時候我們會看到handler_read_rnd_next值很高,為何,這是由於我們後面沒有加索引的時刻,做過量次查詢的緣由.
經常使用SQL優化
年夜批量拔出數據(MySql治理員) 懂得
關於MyISAM:
alter table table_name disable keys; loading data//insert語句; alter table table_name enable keys;
關於Innodb:
1,將要導入的數據依照主鍵排序
2,set unique_checks=0,封閉獨一性校驗。
3,set autocommit=0,封閉主動提交。
優化group by 語句
默許情形,MySQL對一切的group by col1,col2停止排序。這與在查詢中指定order by col1, col2相似。假如查詢中包含group by但用戶想要防止排序成果的消費,則可使用order by
null制止排序
有些情形下,可使用銜接來替換子查詢。
由於應用join,MySQL不須要在內存中創立暫時表。(講授)
假如想要在含有or的查詢語句中應用索引,則or之間的每一個前提列都必需用到索引,假如沒有索引,則應當斟酌增長索引(與情況相干 講授)
select * from 表名 where 前提1='' or 前提2='tt' explaine select * from dept group by dname; =>這時候顯示 extra: using filesort 解釋會停止排序 explaine select * from dept group by dname order by null =>這時候不含有顯示 extra: using filesort 解釋不會停止排序
***有些情形下,可使用銜接來替換子查詢。由於應用join,MySQL不須要在內存中創立暫時表
explain select * from emp , dept where emp.deptno=dept.deptno;
和上面比擬便可以解釋成績!!
explain select * from emp left join dept on emp.deptno=dept.deptno;
選擇適合的存儲引擎
MyISAM:默許的MySQL存儲引擎。假如運用是以讀操作和拔出操作為主,只要很少的更新和刪除操作,而且對事務的完全性請求不是很高。其優勢是拜訪的速度快。
InnoDB:供給了具有提交、回滾和瓦解恢復才能的事務平安。然則比較MyISAM,寫的處置效力差一些而且會占用更多的磁盤空間。
Memory:數據存在內存中,辦事重啟時,數據喪失
MyISAM: 在拔出數據時,默許放在最初. ,刪除數據後,空間不收受接管.(不支撐事務和外鍵)
InnoDB 支撐事務和外鍵
對應我們法式員說,經常使用的存儲引擎重要是 myisam / innodb / memory,heap 表
假如選用小准繩:
1.假如尋求速度,不在意數據能否一向把保留,也不斟酌事務,請選擇 memory 好比寄存用戶在線狀況.
2.假如表的數據要耐久保留,運用是以讀操作和拔出操作為主,只要很少的更新和刪除操作,而且對事務的完全性請求不是很高。選用MyISAM
3.假如須要數據耐久保留,並供給了具有提交、回滾和瓦解恢復才能的事務平安,請選用Innodb
選擇適合的數據類型
在精度請求高的運用中,建議應用定點數來存儲數值,以包管成果的精確性。deciaml 不要用float
關於存儲引擎是MyISAM的數據庫,假如常常做刪除和修正記載的操作,要准時履行optimize table table_name;功效對表停止碎片整頓。
日期類型要依據現實須要選擇可以或許知足運用的最小存儲的晚期類型
create table bbs(id int ,con varchar(1024) , pub_time int);
date('Ymd',時光-3*24*60*60); 2038年-1-19
關於應用浮點數和定點數的案例解釋
create table temp1( t1 float(10,2), t2 decimal(10,2)); insert into temp1 values(1000000.32,1000000,32); 發明 t1 成了 1000000.31 所以有成績.
關於optimize table 表名 演示
create table temp2( id int) engine=MyISAM; insert into temp2 values(1); insert into temp2 values(2); insert into temp2 values(3); insert into temp2 select * from temp2;--復制 delete from temp2 where id=1; 發明 該表關於的數據文件沒有變小
按期履行 optimize table temp2 發明表年夜小變更,碎片整頓終了
&&關於InnoDB它的數據會存在data/ibdata1目次下,在data/數據庫/只要一個 *.frm表構造文件.
關於mysql數據庫機能優化二小編就給年夜家引見到這裡,願望對年夜家有所贊助!