MySQL中由load data語句惹起逝世鎖的處理案例。本站提示廣大學習愛好者:(MySQL中由load data語句惹起逝世鎖的處理案例)文章只能為提供參考,不一定能成為您想要的結果。以下是MySQL中由load data語句惹起逝世鎖的處理案例正文
一個線上項目報的逝世鎖,扼要解釋一下發生緣由、處置計劃和相干的一些點.
1、配景
這是一個相似數據剖析的項目,數據完整經由過程LOAD DATA語句導入一個InnoDB表中。為便利描寫,表構造簡化為以下:
Create table tb(id int primary key auto_increment, c int not null) engine=innodb;
導入數據的語句對應為
Load data infile ‘data1.csv' into table tb;
Load data infile ‘data2.csv' into table tb;
cat Data1.csv
1 100
2 100
3 100
Cat data2.csv
10 100
11 100
12 100
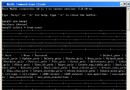
發生逝世鎖的證據是在show engine innodb status的LATEST DETECTED DEADLOCK段中看到逝世鎖信息,簡化為以下:

解釋
從下面表格中看出,事務1在期待某一行的鎖。而事務2持有這行的鎖,但期待表的自增鎖(AUTO_INC),斷定為逝世鎖,事務回滾。
這裡事務1沒有寫出來,然則可以揣摸,事務1持有這個表的自增鎖(不然就不是逝世鎖了)。
2、配景常識1:AUTO_INC lock 及其選項
在InnoDB表中,若存在自增字段,則會保護一個表級其余鎖,這裡稱為自增鎖。每次拔出新數據,或許update語句修正了此字段,都邑須要獲得這個鎖
因為一個事務能夠包括多個語句,而並不是一切的語句都與自增字段有關,是以InnoDB作了一個特別的處置,自增鎖在一個語句停止後立時被釋放。之所以說是特別處置,是由於通俗的鎖,都是在事務停止後釋放。
若一個表有自增字段,一個insert語句不指定該字段的值,或指定為NULL時,InnoDB會給它賦值為以後的AUTO_INCREMENT的值,然後AUTO_INCREMENT加1。
與這個自增鎖相干的一個參數是innodb_autoinc_lock_mode. 默許值為1,可選為0,1,2。
我們先來看當這個值設置為0時,一個有自增字段的表,拔出一行數據時的行動:
1) 請求AUTO_INC鎖
2) 獲得以後AUTO_INCREMNT值n,給AUTO_INCREMENT 加1
3) 履行拔出操作,並將n填入新增的行對應字段中
4) 釋放AUTO_INC鎖
我們看到這個進程中,固然InnoDB為了削減鎖粒度,在語句履行完造詣立時釋放,但這鎖照樣太年夜了――它包含了拔出操作的時光。這就招致了兩個insert語句,現實上沒方法並行。
沒有這個參數之前,行動就是與設置為0雷同,0這個選項就是留著兼容的。
很輕易想到設置為1的時刻,應當是將3) 和 4)對換。然則本文照樣要評論辯論為0的情形,由於我們的條件是LOAD語句,而LOAD語句這類拔出多行的語句中(包含insert …select …),即便設置為1也沒用,會退步為0的形式。
3、配景常識2:LOAD DATA語句的主從行動
為何拔出多行的語句要即便將innodb_autoinc_lock_mode設置為1,也會用0的形式呢?
重要緣由照樣為了主從分歧性。假想binlog_format='statement',一個LOAD DATA語句在主庫的binlog直接記載為語句自己,那從庫若何重放:
1) 將load data用到的文件發給slave,slave將文件保留在暫時目次。
2) 在slave也履行一次LOAD DATA語句。
其間有一個成績:slave怎樣包管load data語句的自增id字段與master雷同?
為懂得決這個成績,主庫的binlog中還有一個set SET INSERT_ID敕令,注解這個LOAD DATA語句拔出的第一行的自增ID值。如許slave在履行load data之前,先履行了這個set SET INSERT_ID語句,用於包管履行成果與主庫如出一轍。
上述的機制能包管主從數據分歧的條件是:主從庫上LOAD DATA語句生成的自增ID值必需是持續的。
4、配景常識1+2:剖析
回到後面說的形式0和1的差別,我們看到,假如AUTO_INC鎖在全部語句開端之前就獲得,在語句停止以後才釋放,如許就可以包管全部語句生成的id持續――形式0的包管。
關於1,每次拿到下一個值就釋放,拔出數據後,若須要再請求,則不持續。
這就是為何,即便設置為1,關於多行操作,會退步成0。
至此我們曉得這個逝世鎖湧現的緣由,是這兩個LOAD DATA語句不只會拜訪雷同的記載,還會拜訪統一個AUTO_INC鎖,形成相互期待。
到此沒完,由於我們曉得固然兩個線程拜訪兩個鎖能夠形成逝世鎖,然則逝世鎖還有別的一個前提,與請求次序有關。既然AUTO_INC是一個表鎖,豈論誰先拿到,會壅塞其他同表的LOAD DATA的履行,又為何會在某個記載上湧現鎖期待?
5、配景常識3:AUTO_INC的加鎖機會
後面我們說到每次觸及到拔出新數據,就會請求對AUTO_INC加鎖,並列出了流程。但這個流程是關於須要從InnoDB中獲得自增值來設置列值的情形。另外一種情形是在語句中曾經指定了該列的值。
好比關於這個表,履行 insert into tb values(9,100). 此時id的值曾經明白是9,固然不須要取值來填,然則拔出這行後有能夠須要轉變AUTO_INCREMENT的值(若本來是<10,則應當改成10),所以這個鎖照樣省不了。流程釀成:
1) 拔出數據
2) 若掉敗則流程停止
3) 若勝利,請求AUTO_INC鎖
4) 挪用set_max….函數,若有需要則修正AUTO_INCREMENT
5) 語句停止時釋放AUTO_INC鎖。
6、為何修正AUTO_INC次序
這麼調劑的利益是甚麼? 重要是為了削減不用要的鎖拜訪。若在拔出數據時代產生毛病,好比其他字段形成DUPLICATE KEY error,如許就不消拜訪AUTO_INC鎖。
7、逝世鎖進程復現
必需強調是“語句停止時”。如許我們來看一個每行都曾經指定了自增列值的LOAD DATA語句的流程(也就是本文例子的情形):
1) 拔出第一條數據
2) 請求AUTO_INC鎖
3) 拔出第二條
4) 請求AUTO_INC 鎖(由於曾經是本身的,直接勝利)
5) 。。。。。。拔出殘剩一切行
6) 釋放AUTO_INC鎖。
所以這個流程就簡略描寫為:拔出第一行,請求AUTO_INC鎖,然後拔出剩下的一切行後再釋放。
我們後面提到過,拔出第一條數據時能夠須要拜訪的記載鎖,是要比及全部事務停止後才釋放的.
有了下面的這些配景常識,我們來復現一下逝世鎖湧現的進程

可以看到觸發前提照樣比擬刻薄的,特別是session2要恰好要用到session1鎖住的誰人記載鎖。須要解釋,因為InnoDB外部對記載的表現,統一個記載鎖其實不表現主鍵值必定雷同。
8、處理計劃1:去失落不用要的AUTO_INCREMENT字段
在這個營業中,因為一切的數據都是經由過程LOAD DATA出來,並且都曾經指定了自增字段的值,是以這個AUTO)INCREMENT屬性是不須要的。
少了一個,就逝世鎖不了了。
9、處理計劃2:強迫形式1
後面我們說到innodb_autoinc_lock_mode這個參數的可選值有0、1、2。當設置為1的時刻,在LOAD DATA語句會退步為形式0。但如果設置為2,則不管若何都邑應用形式1。
我們後面說到應用形式1會招致LOAD DATA生成的自增id值不持續,如許會招致在binlog_format是1時主從紛歧致,是以設置為2的條件,是binlog_format 是row.
在binlog_format='row'時,設置innodb_autoinc_lock_mode為2是平安的。
若許可,計劃2比喻案1更輕量些,不須要修正數據和表構造。
��延遲 , 假如是 Linux kernel 的默許設置裝備擺設,會到達 40 毫秒 .
# 假如選擇 "no" ,則發送數據到 slave 真個延遲會下降,但將應用更多的帶寬用於復制 .
repl-disable-tcp-nodelay no
# 設置復制的後台日記年夜小。
# 復制的後台日記越年夜, slave 斷開銜接及後來能夠履行部門復制花的時光就越長。
# 後台日記在至多有一個 slave 銜接時,僅僅分派一次。
# repl-backlog-size 1mb
# 在 master 不再銜接 slave 後,後台日記將被釋放。上面的設置裝備擺設界說從最初一個 slave 斷開銜接後須要釋放的時光(秒)。
# 0 意味著從不釋放後台日記
# repl-backlog-ttl 3600
# 假如 master 不克不及再正常任務,那末會在多個 slave 中,選擇優先值最小的一個 slave 晉升為 master ,優先值為 0 表現不克不及晉升為 master 。
slave-priority 100
# 假如少於 N 個 slave 銜接,且延遲時光 <=M 秒,則 master 可設置裝備擺設停滯接收寫操作。
# 例如須要至多 3 個 slave 銜接,且延遲 <=10 秒的設置裝備擺設:
# min-slaves-to-write 3
# min-slaves-max-lag 10
# 設置 0 為禁用
# 默許 min-slaves-to-write 為 0 (禁用), min-slaves-max-lag 為 10
################################## 平安 ###################################
# 設置客戶端銜接落後行任何其他指定前須要應用的暗碼。
# 正告:由於 redis 速度相當快,所以在一台比擬好的辦事器下,一個內部的用戶可以在一秒鐘停止 150K 次的暗碼測驗考試,這意味著你須要指定異常異常壯大的暗碼來避免暴力破解
# requirepass foobared
# 敕令重定名 .
# 在一個同享情況下可以重定名絕對風險的敕令。好比把 CONFIG 重名為一個不輕易猜想的字符。
# 舉例 :
# rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52
# 假如想刪除一個敕令,直接把它重定名為一個空字符 "" 便可,以下:
# rename-command CONFIG ""
################################### 束縛###################################
#設置統一時光最年夜客戶端銜接數,默許無窮制,
#Redis 可以同時翻開的客戶端銜接數為 Redis 過程可以翻開的最年夜文件描寫符數,
#假如設置 maxclients 0 ,表現不作限制。
#當客戶端銜接數達到限制時, Redis 會封閉新的銜接並向客戶端前往 max number of clients reached 毛病信息
# maxclients 10000
# 指定 Redis 最年夜內存限制, Redis 在啟動時會把數據加載到內存中,到達最年夜內存後, Redis 會依照消除戰略測驗考試消除已到期的 Key
# 假如 Redis 按照戰略消除後沒法供給足夠空間,或許戰略設置為 ”noeviction” ,則應用更多空間的敕令將會報錯,例如 SET, LPUSH 等。但依然可以停止讀取操作
# 留意: Redis 新的 vm 機制,會把 Key 寄存內存, Value 會寄存在 swap 區
# 該選項對 LRU 戰略很有效。
# maxmemory 的設置比擬合適於把 redis 看成於相似 memcached 的緩存來應用,而不合適當作一個真實的 DB 。
# 當把 Redis 當作一個真實的數據庫應用的時刻,內存應用將是一個很年夜的開支
# maxmemory
# 當內存到達最年夜值的時刻 Redis 會選擇刪除哪些數據?有五種方法可供選擇
# volatile-lru -> 應用 LRU 算法移除設置過過時時光的 key (LRU: 比來應用 Least RecentlyUsed )
# allkeys-lru -> 應用 LRU 算法移除任何 key
# volatile-random -> 移除設置過過時時光的隨機 key
# allkeys->random -> remove a randomkey, any key
# volatile-ttl -> 移除行將過時的 key(minor TTL)
# noeviction -> 不移除任何可以,只是前往一個寫毛病
# 留意:關於下面的戰略,假如沒有適合的 key 可以移除,當寫的時刻 Redis 會前往一個毛病
# 默許是 : volatile-lru
# maxmemory-policy volatile-lru
# LRU 和 minimal TTL 算法都不是精准的算法,然則絕對准確的算法 ( 為了節儉內存 ) ,隨便你可以選擇樣本年夜小停止檢測。
# Redis 默許的灰選擇 3 個樣本停止檢測,你可以經由過程 maxmemory-samples 停止設置
# maxmemory-samples 3
############################## AOF###############################
# 默許情形下, redis 會在後台異步的把數據庫鏡像備份到磁盤,然則該備份長短常耗時的,並且備份也不克不及很頻仍,假如產生諸如拉閘限電、拔插優等狀態,那末將形成比擬年夜規模的數據喪失。
# 所以 redis 供給了別的一種加倍高效的數據庫備份及災害恢復方法。
# 開啟 append only 形式以後, redis 會把所吸收到的每次寫操作要求都追加到 appendonly.aof 文件中,當 redis 從新啟動時,會從該文件恢復出之前的狀況。
# 然則如許會形成 appendonly.aof 文件過年夜,所以 redis 還支撐了 BGREWRITEAOF 指令,對 appendonly.aof 停止從新整頓。
# 你可以同時開啟 asynchronous dumps 和 AOF
appendonly no
# AOF 文件稱號 ( 默許 : "appendonly.aof")
# appendfilename appendonly.aof
# Redis 支撐三種同步 AOF 文件的戰略 :
# no: 不停止同步,體系去操作 . Faster.
# always: always 表現每次有寫操作都停止同步 . Slow, Safest.
# everysec: 表現對寫操作停止積累,每秒同步一次 . Compromise.
# 默許是 "everysec" ,依照速度和平安折衷這是最好的。
# 假如想讓 Redis 能更高效的運轉,你也能夠設置為 "no" ,讓操作體系決議甚麼時刻去履行
# 或許相反想讓數據更平安你也能夠設置為 "always"
# 假如不肯定就用 "everysec".
# appendfsync always
appendfsync everysec
# appendfsync no
# AOF 戰略設置為 always 或許 everysec 時,後台處置過程 ( 後台保留或許 AOF 日記重寫 ) 會履行年夜量的 I/O 操作
# 在某些 Linux 設置裝備擺設中會阻攔太長的 fsync() 要求。留意如今沒有任何修復,即便 fsync 在別的一個線程停止處置
# 為了減緩這個成績,可以設置上面這個參數 no-appendfsync-on-rewrite
no-appendfsync-on-rewrite no
# AOF 主動重寫
# 當 AOF 文件增加到必定年夜小的時刻 Redis 可以或許挪用 BGREWRITEAOF 對日記文件停止重寫
# 它是如許任務的: Redis 會記住前次停止些日記後文件的年夜小 ( 假如從開機以來還沒停止太重寫,那日子年夜小在開機的時刻肯定 )
# 基本年夜小會同如今的年夜小停止比擬。假如如今的年夜小比基本年夜小年夜制訂的百分比,重寫功效將啟動
# 同時須要指定一個最小年夜小用於 AOF 重寫,這個用於阻攔即便文件很小然則增加幅度很年夜也去重寫 AOF 文件的情形
# 設置 percentage 為 0 就封閉這個特征
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
################################ LUASCRIPTING #############################
# 一個 Lua 劇本最長的履行時光為 5000 毫秒( 5 秒),假如為 0 或正數表現無窮履行時光。
lua-time-limit 5000
################################LOW LOG################################
# Redis Slow Log 記載跨越特定履行時光的敕令。履行時光不包含 I/O 盤算好比銜接客戶端,前往成果等,只是敕令履行時光
# 可以經由過程兩個參數設置 slow log :一個是告知 Redis 履行跨越若干時光被記載的參數 slowlog-log-slower-than( 奧妙 ) ,
# 另外一個是 slow log 的長度。當一個新敕令被記載的時刻最早的敕令將被從隊列中移除
# 上面的時光以奧妙為單元,是以 1000000 代表一秒。
# 留意指定一個正數將封閉慢日記,而設置為 0 將強迫每一個敕令都邑記載
slowlog-log-slower-than 10000
# 對日記長度沒無限制,只是要留意它會消費內存
# 可以經由過程 SLOWLOG RESET 收受接管被慢日記消費的內存
# 推舉應用默許值 128 ,當慢日記跨越 128 時,最早進入隊列的記載會被踢出
slowlog-max-len 128
################################ 事宜告訴 #############################
# 當事宜產生時, Redis 可以告訴 Pub/Sub 客戶端。
# 可以鄙人表當選擇 Redis 要告訴的事宜類型。事宜類型由單個字符來標識:
# K Keyspace 事宜,以 _keyspace@_ 的前綴方法宣布
# E Keyevent 事宜,以 _keysevent@_ 的前綴方法宣布
# g 通用事宜(不指定類型),像 DEL, EXPIRE, RENAME, …
# $ String 敕令
# s Set 敕令
# h Hash 敕令
# z 有序聚集敕令
# x 過時事宜(每次 key 過時時生成)
# e 消除事宜(當 key 在內存被消除時生成)
# A g$lshzxe 的別稱,是以 ”AKE” 意味著一切的事宜
# notify-keyspace-events 帶一個由 0 到多個字符構成的字符串參數。空字符串意思是告訴被禁用。
# 例子:啟用 list 和通用事宜:
# notify-keyspace-events Elg
# 默許所用的告訴被禁用,由於用戶平日不須要改特征,而且該特征會有機能消耗。
# 留意假如你不指定至多 K 或 E 之一,不會發送任何事宜。
notify-keyspace-events “”
############################## 高等設置裝備擺設 ###############################
# 當 hash 中包括跨越指定元素個數而且最年夜的元素沒有跨越臨界時,
# hash 將以一種特別的編碼方法(年夜年夜削減內存應用)來存儲,這裡可以設置這兩個臨界值
# Redis Hash 對應 Value 外部現實就是一個 HashMap ,現實這裡會有 2 種分歧完成,
# 這個 Hash 的成員比擬少時 Redis 為了節儉內存會采取相似一維數組的方法來緊湊存儲,而不會采取真實的 HashMap 構造,對應的 valueredisObject 的 encoding 為 zipmap,
# 當做員數目增年夜時會主動轉成真實的 HashMap, 此時 encoding 為 ht 。
hash-max-zipmap-entries 512
hash-max-zipmap-value 64
# 和 Hash 一樣,多個小的 list 以特定的方法編碼來節儉空間。
# list 數據類型節點值年夜小小於若干字節會采取緊湊存儲格局。
list-max-ziplist-entries 512
list-max-ziplist-value 64
# set 數據類型外部數據假如全體是數值型,且包括若干節點以下會采取緊湊格局存儲。
set-max-intset-entries 512
# 和 hashe 和 list 一樣 , 排序的 set 在指定的長度內以指定編碼方法存儲以節儉空間
# zsort 數據類型節點值年夜小小於若干字節會采取緊湊存儲格局。
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
# Redis 將在每 100 毫秒時應用 1 毫秒的 CPU 時光來對 redis 的 hash 表停止從新 hash ,可以下降內存的應用
# 當你的應用場景中,有異常嚴厲的及時性須要,不克不及夠接收 Redis 時不時的對要求有 2 毫秒的延遲的話,把這項設置裝備擺設為 no 。
# 假如沒有這麼嚴厲的及時性請求,可以設置為 yes ,以便可以或許盡量快的釋放內存
activerehashing yes
# 客戶真個輸入緩沖區的限制,由於某種緣由客戶端從辦事器讀取數據的速度不敷快,
# 可用於強迫斷開銜接(一個罕見的緣由是一個宣布 / 定閱客戶端花費新聞的速度沒法遇上臨盆它們的速度)。
# 可以三種分歧客戶真個方法停止設置:
# normal -> 正常客戶端
# slave -> slave 和 MONITOR 客戶端
# pubsub -> 至多定閱了一個 pubsub channel 或 pattern 的客戶端
# 每一個 client-output-buffer-limit 語法 :
# client-output-buffer-limit
# 一旦到達硬限制客戶端會立刻斷開,或許到達軟限制並堅持殺青的指定秒數(持續)。
# 例如,假如硬限制為 32 兆字節和軟限制為 16 兆字節 /10 秒,客戶端將會立刻斷開
# 假如輸入緩沖區的年夜小到達 32 兆字節,客戶端到達 16 兆字節和持續跨越了限制 10 秒,也將斷開銜接。
# 默許 normal 客戶端不做限制,由於他們在一個要求後未請求時(以推的方法)不吸收數據,
# 只要異步客戶端能夠會湧現要求數據的速度比它可以讀取的速度快的場景。
# 把硬限制和軟限制都設置為 0 來禁用該特征
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb60
client-output-buffer-limit pubsub 32mb 8mb60
# Redis 挪用外部函數來履行很多後台義務,如封閉客戶端超時的銜接,消除過時的 Key ,等等。
# 不是一切的義務都以雷同的頻率履行,但 Redis 按照指定的“ Hz ”值來履行檢討義務。
# 默許情形下,“ Hz ”的被設定為 10 。
# 進步該值將在 Redis 余暇時應用更多的 CPU 時,但同時當有多個 key 同時到期會使 Redis 的反響更敏銳,和超時可以更准確地處置。
# 規模是 1 到 500 之間,然則值跨越 100 平日不是一個好主張。
# 年夜多半用戶應當應用 10 這個預設值,只要在異常低的延遲的情形下有需要進步最年夜到 100 。
hz 10
# 當一個子節點重寫 AOF 文件時,假如啟用上面的選項,則文件每生成 32M 數據停止同步。
aof-rewrite-incremental-fsync yes
8.Redis官方文檔對VM的應用建議:
當你的key很小而value很年夜時,應用VM的後果會比擬好.由於如許勤儉的內存比擬年夜.
當你的key不小時,可以斟酌應用一些異常辦法將很年夜的key釀成很年夜的value,好比你可以斟酌將key,value組分解一個新的value.
最好應用linux ext3 等對稀少文件支撐比擬好的文件體系保留你的swap文件.
vm-max-threads這個參數,可以設置拜訪swap文件的線程數,設置最好不要跨越機械的核數,假如設置為0,那末一切對swap文件的操作都是串行的.能夠會形成比擬長時光的延遲,然則對數據完全性有很好的包管.
有了VM功效,Redis終究解脫了受內存容量限制的惡夢了,仿佛我們可以稱其為Redis數據庫了,我們還可以想象又有若干新的用法可以發生.固然,願望這一功效不會對Redis原本的異常牛B的內存存儲機能有所影響.
9. redis修正耐久化途徑和日記途徑
vim redis.conf
logfile /data/redis_cache/logs/redis.log #日記途徑
dir /data/redis_cache #耐久化途徑,修正後 記得要把dump.rdb耐久化文件拷貝到/data/redis_cache下
先殺失落redis,拷貝dump.rdb,啟動
10. 清redis緩存
./redis-cli #進入
dbsize
flushall #履行
exit
11. 刪除redis以後數據庫中的一切Key
flushdb
12.刪除redis一切數據庫中的key
flushall