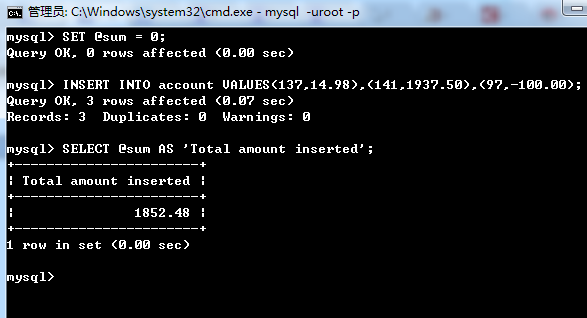
mysql機能優化之索引優化。本站提示廣大學習愛好者:(mysql機能優化之索引優化)文章只能為提供參考,不一定能成為您想要的結果。以下是mysql機能優化之索引優化正文
作為收費又高效的數據庫,mysql根本是首選。優越的平安銜接,自帶查詢解析、sql語句優化,應用讀寫鎖(細化到行)、事物隔離和多版本並發掌握進步並發,完整的事務日記記載,壯大的存儲引擎供給高效查詢(表記載可達百萬級),假如是InnoDB,還可在瓦解落後行完全的恢復,長處異常多。即便有這麼多長處,仍依附人去做點優化,看書後寫個總結穩固下,有錯請斧正。
完全的mysql優化須要很深的功底,年夜公司乃至有專門寫mysql內核的,sql優化攻城獅,mysql辦事器的優化,各類參數常量設定,查詢語句優化,主從復制,軟硬件進級,容災備份,sql編程,須要的不是一星半點的常識與時光來控制,作為一位像俺如許的菜鳥開辟,強吃這麼多消化不了也沒意義:沒地兒用啊,何況還有運維和dba,還不如把手頭的營業寫好,也就是寫好點的sql,並且許多sql語句優化跟索引照樣有很年夜關系的。
起首,mysql的查詢流程年夜致是:mysql客戶端經由過程協定與mysql辦事器樹立銜接,發送查詢語句,先檢討查詢緩存,假如射中,直接前往成果,不然停止語句解析,有一系列預處置,好比檢討語句能否寫准確了,然後是查詢優化(好比能否應用索引掃描,假如是一個弗成能的前提,則提早終止),生成查詢籌劃,然後查詢引擎啟動,開端履行查詢,從底層存儲引擎挪用API獲得數據,最初前往給客戶端。怎樣存數據、怎樣取數據,都與存儲引擎有關。然後,mysql默許應用的BTREE索引,而且一個年夜偏向是,不管怎樣折騰sql,至多在今朝來講,mysql最多只用到表中的一個索引。
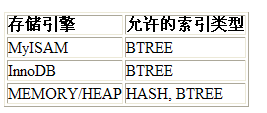
mysql經由過程存儲引擎取數據,天然跟存儲引擎有很年夜關系,分歧的存儲引擎索引也紛歧樣,如MyISAM的全文索引,即使索引叫一個名字外部組織方法也不盡雷同,最經常使用確當然就是InnoDB了(還有完整兼容mysql的MariaDB,它的默引擎是XtraDB,跟InnoDB很像),這裡寫的是InnoDB引擎。而索引的完成也跟存儲引擎,依照完成方法分,InnoDB的索引今朝只要兩種:BTREE索引和HASH索引。平日我們說的索引不出不測指的就是B樹索引,InnoDB的BTREE索引,現實是用B+樹完成的,由於在檢查表索引時,mysql一概打印BTREE,所以簡稱為B樹索引。至於B樹與B+樹的差別,諒解的俺數據構造沒好勤學,也是須要補的處所。
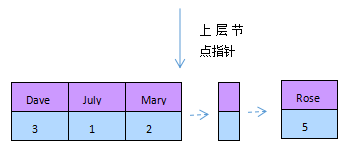
應用了BTREE索引,意味著一切的索引是按次序分列存儲的(升序),mysql就是這麼干的,mysl中的BTREE索引籠統構造以下圖(參考高機能mysql)。

構造中,每層節點均從左往右從小到年夜分列,key1 < key2 < ... < keyN,關於小於key1或在[key1,key2)或其他的值的節點,在進入葉子節點查找,是一個規模散布,同時,統一層節點之間可直接拜訪,由於他們之間有指針指向接洽(MyISAM的BTREE索引沒有)。每次搜刮是一個區間搜刮,有的話就找到了,沒有的話就是空。索引能加速拜訪速度,由於有了它無需全表掃描數據(不老是如許),依據查找的值,跟節點中的值比擬,平日應用二分查找,關於排好序的數值來講,均勻速度簡直是最快的。
val指向了哪裡,關於InnoDB,它指向的就是表數據,由於InnoDB的表數據自己就是索引文件,這是與MyISAM索引的明顯差別,MyISAM的索引指向的是表數據的地址(val指向的是相似於0x7DFF..之類)。好比關於InnoDB一個主鍵索引來講,能夠是如許

InnoDB的索引節點val值直接指向表數據,即它的葉子節點就是表數據,它們連在一路,表記載行沒有再零丁放在其他處所,葉子節點(數據)之間可拜訪。
後面在BTREE的籠統構造中,索引值的節點是放在頁中的,這裡有兩個需留意的成績:
1. 葉子頁、頁中的值(上上圖),即所謂的頁是啥,俺加了個節點正文,即這裡的頁最小可近似當作是單個節點。我們曉得盤算機的存儲空間是一塊一塊的,平日一塊用完了再用另外一塊,假如上一塊只殘剩5kb,但這裡恰好要請求8kb的空間,就得在一個新的塊上請求這個空間,然後今後的請求又接在這個8kb前面,只需這個塊的空間足夠,那末上一塊的5kb平日就成了所謂的“碎片”,電腦用多了會有許多如許零碎的碎片空間,是以有碎片整頓。在mysql中,這裡的頁可懂得為塊存儲空間,即索引的樹節點是寄存在頁中的,每頁(稱為邏輯頁)有固定年夜小,InnoDB今朝是16kb,一頁用完了,當持續拔出表生成新的索引節點時,就去新的頁中存儲這個節點,再有新的節點就持續放在這個新的頁的節點前面。
2. 頁決裂成績,一頁總要被存滿,然後新開一頁持續,這類行動被稱作頁決裂。什麼時候開拓新的頁,mysql劃定了一個決裂因子,到達頁存儲空間的15/16則存到下一頁。頁決裂的存在能夠極年夜影響機能保護索引的機能。平日倡導的是,設定一個有意義的整數自增索引,有益於索引存儲

假如非自增或不是整數索引,如非自增整數、相似MD5的字符串,以他們作為索引值時,由於待拔出的下一條數據的值紛歧定比上一條年夜,乃至比以後頁一切值都小,須要跑到前幾頁去比擬而找到適合地位,InnoDB沒法簡略的把新行拔出到上一行前面,而找到並拔出索引後,能夠招致該頁到達決裂因子閥值,須要頁決裂,進一步招致前面一切的索引頁的決裂和排序,數據量小或許沒甚麼成績,數據量年夜的話能夠會糟蹋年夜量時光,發生很多碎片。

主鍵老是獨一且非空,InnoDB主動對它樹立了索引(primary key),關於非主鍵字段上樹立的索引,又稱幫助索引,索引分列也是次序分列,只是它還附帶一個本筆記錄的主鍵值的數據域,不是指向本數據行的指針,在應用幫助索引查找時,先找到對應這一列的索引值,再依據索引節點上的另外一個數據域---主鍵值,來查找該行記載,即每次查找現實經由查找了兩次。額定的數據域存儲主鍵值的利益是,當頁決裂產生時,無需修正數據域的值,由於即便頁決裂,該行的主鍵值是不變的,而地址就變了。好比name字段的索引簡示以下
包括一列的索引稱為單列索引,多列的稱為復合索引,由於BTREE索引是次序分列的,所以比擬合適規模查詢,然則在復合索引中,還應留意列數量、列的次序和後面規模查詢的列對後邊列的影響。
好比有如許一張表
create table staffs(
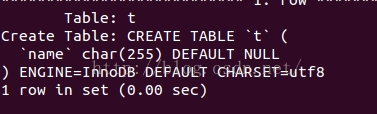
id int primary key auto_increment,
name varchar(24) not null default '' comment '姓名',
age int not null default 0 comment '年紀',
pos varchar(20) not null default '' comment '職位',
add_time timestamp not null default current_timestamp comment '入職時光'
) charset utf8 comment '員工記載表';
添加三列的復合索引
alter table staffs add index idx_nap(name, age, pos);
在BTREE索引的應用上,以下幾種情形可以用到該索引或索引的一部門(應用explain簡略檢查應用情形):
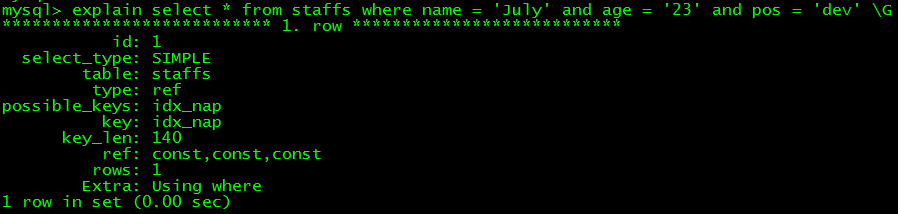
1. 全值婚配
如select * from staffs where name = 'July' and age = '23' and pos = 'dev' ,key字段顯示應用了idx_nap索引
2. 婚配最左列,關於復合索引來講,不老是婚配一切字段列,然則可以婚配索引中靠左的列
如select * from staffs where name = 'July' and age = '23',key字段顯示用到了索引,留意,key_len字段(表現本次語句應用的索引長度)數值比上一條小了,意思是它並未應用全體索引列(平日這個長度可估摸著用了哪些索引列,埋個坑),現實上只用到了name和age列
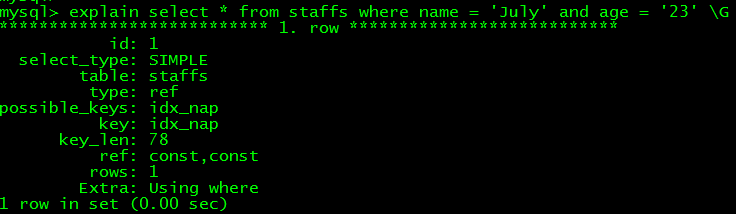
再嘗嘗select * from staffs where name = 'July',它也用了索引,key_len值更小,現實只用到了索引中的name列
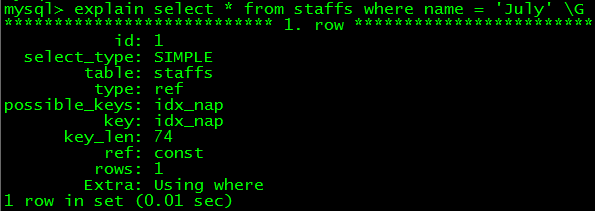
3. 婚配列前綴,即一個索引中列的前一部門,重要用在隱約婚配,如select * fromstaffs where name like 'J%',explain信息的key字段表現應用了索引,然則mysql的B樹索引不克不及非列前綴的隱約婚配,如select * from staffs where name like '%y' 或許 like '%u%',聽說是因為底層存儲引擎的API限制
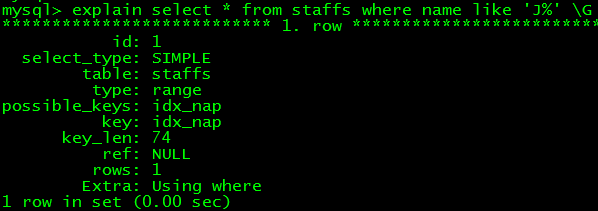
4. 婚配規模,如select * from staffs where name > 'Mary',但俺在測試時發明>可以,>=卻不可,至多在字符串列上不可(測試mysql版本5.5.12),但是在時光類型(timestamp)上卻可以,意外試下還真不克不及肯定說就用到了索引==
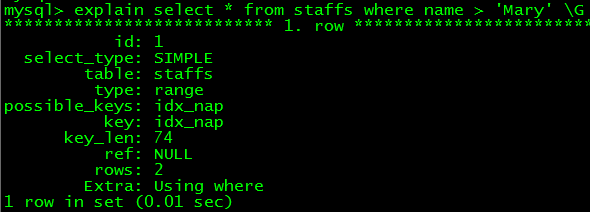
出於獵奇測了下整型字段的索引(idx_cn(count, name),count為整型),發明整型受限制少許多,上面的都能用到索引,連前隱約婚配的都行
select * from indexTest1 where count > '10' select * from indexTest1 where count >= '10' select * from indexTest1 where count > '10%' select * from indexTest1 where count >= '10%' select * from indexTest1 where count > '%10%' select * from indexTest1 where count >= '%10%'
5. 准確婚配一列並規模婚配右邊相鄰列,即前一列是固定值,後一列是規模值,它用了name與age兩個列的索引(key_len推想)
如select * from staffs where name = 'July' and age > 25
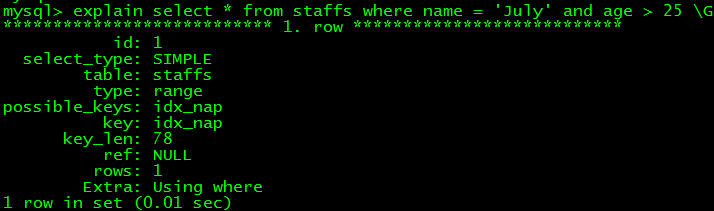
6. 只拜訪索引的查詢,好比staffs表的情形,索引樹立在(name,age,pos)下面,後面一向是讀取的全體列,假如我們用到了哪些列的索引,查詢時也只查這些列的數據,就是只拜訪索引的查詢,如
select name,age,pos from staffs where name = 'July' and age = 25 and pos = 'dev' select name,age from staffs where name = July and age > 25
第一句用到了全體索引列,第二句只用了索引前兩列,select的字段就最多只能是這兩列,這類查詢情形的索引,mysql稱為籠罩索引,就是索引包括(籠罩)了查詢的全體字段。是否是用到了索引查詢,在explain中須要看最初一個Extra列的信息,Using index注解應用了籠罩索引,同時Using where注解也應用了where過濾
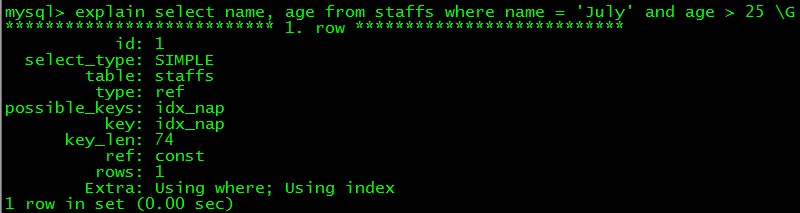
7. 前綴索引
差別於列前綴(相似like 'J%'情勢的隱約婚配)和最左列索引(次序取索引中靠左的列的查詢),它只取某列的一部門作為索引。平日在說InnoDB跟MyISAM的差別時,一個顯著的差別是:MyISAM支撐全文索引,而InnoDB不可,乃至關於text、blob這類超長的字符串或二進制數據時,MyISAM會取前若干個字符作為索引,InnoDb的前綴索引跟這個相似,某些列,普通是字符串類型,很長,全體作為索引年夜年夜增長存儲空間,索引也須要保護,關於長字符串,又想作為索引列,一個可取的方法就是取前一部門(前綴),代表一整列作為索引串,成績是:若何確保這個前綴能代表或年夜致代表這一列?所以mysql中有個概念是索引的選擇性,是指索引中不反復的值的數量(也稱基數)與全部表該列記載總數(#T)的比值,好比一個列表(1,2,2,3),總數是4,不反復值數量為3,選擇性為3/4,是以選擇性規模是[1/#T, 1],這個值越年夜,表現列中不反復值越多,越合適作為前綴索引,獨一索引(UNIQUE KEY)的選擇性是1。
好比有一列a varchar(255),以它作前綴索引,好比以7個測試,逐一增長看看選擇性值增加到誰人數根本不變,就表現可以代表整列了,再聯合這個長度的索引列能否存儲數據太多,做個衡量,根本就好了。但假如這個選擇性原來就小的不幸照樣算了
select count(distinct left(a, 7))/count(*) as non_repeat from tab;
定好一個前綴數量,如9,添加索引時可以如許
alter table tab add index idx_pn(name(9)) --零丁前綴索引 alter table tab add index idx_cpn(count, name(9)) --復合前綴索引
以上為罕見的應用索引的方法,有這麼些情形不克不及用或不克不及全用,有的就是下面情形的反例,以key(a, b, c)為例
1. 跳過列,where a = 1 and c = 3,最多用到索引列a;where b = 2 and c = 3,一個也用不到,必需從最左列開端
2. 後面是規模查詢,where a = 1 and b > 2 and c = 3,最多用到 a, b兩個索引列;
3. 次序倒置,where c = 3 and b = 2 and a = 1,一個也用不到;
4. 索引列上應用了表達式,如where substr(a, 1, 3) = 'hhh',where a = a + 1,表達式是一年夜隱諱,再簡略mysql也不認。有時數據量不是年夜到嚴重影響速度時,普通可以先查出來,好比先查一切有定單記載的數據,再在法式中去挑選以'cp1001'開首的定單,而不是寫sql過濾它;
5. 隱約婚配時,盡可能寫 where a like 'J%',字符串放在右邊,如許才能夠用獲得a列索引,乃至能夠還用不到,固然這得看數據類型,最好測試一下。
排序對索引的影響
order by是常常用的語句,排序也遵守最左前綴列的准繩,好比key(a, b),上面語句可以用到(測試為妙)
select * from tab where a > 1 order by b select * from tab where a > 1 and b > '2015-12-01 00:00:00' order by b select * from tab order by a, b
以下情形用不到
1. 非最左列,select * from tab order by b;
2. 不按索引列次序來的,select * from tab where b > '2015-12-01 00:00:00' order by a;
3. 多列排序,但列的次序偏向紛歧致,select * from tab a asc, b desc。
聚簇索引與籠罩索引
後面說到,mysql索引從構造上只要兩類,BTREE與HASH,籠罩索引只是在查詢時,要查詢的列恰好與應用的索引列完整分歧,mysql直接掃描索引,然後便可前往數據,年夜年夜進步效力,由於不需再去原表查詢、過濾,這類情勢下的索引稱作籠罩索引,好比key(a,b),查詢時select a,b from tab where a = 1 and b > 2,實質緣由:BTREE索引存儲了原表數據。
聚簇索引也不是零丁的索引,後面扼要寫到,BTREE索引會把數據放在索引中,即索引的葉子頁中,包含主鍵,主鍵是跟表數據緊挨著放在一路的,由於表數據只要一份,一列鍵值要跟每行數據都緊挨在一路,所以一張表只要一個聚簇索引,關於mysql來講,就是主鍵列,它是默許的。
聚簇索引將表數據組織到了一路(參考後面主鍵索引簡單圖),拔出時嚴重依附主鍵次序,最好是持續自增,不然面對頻仍頁決裂成績,挪動很多數據。
哈希索引
扼要說下,相似於數據構造中簡略完成的HASH表(散列表)一樣,當我們在mysql頂用哈希索引時,也是對索引列盤算一個散列值(相似md5、sha1、crc32),然後對這個散列值以次序(默許升序)分列,同時記載該散列值對應數據表中某行的指針,固然這只是簡單模仿圖
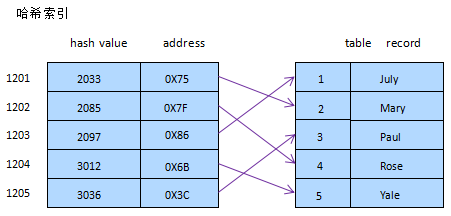
好比對姓名列樹立hash索引,生成hash值按次序分列,然則次序分列的hash值其實不對應表中記載,從地址指針可反響出來,並且,hash索引能夠樹立在兩列或許更多列上,獲得是多列數據後的hash值,它不存儲表中數據。它先盤算列數據的hash值,與索引中的hash值比擬,找到了然後比對列數據能否相等,能夠觸及其他列前提,然後前往數據。hash固然會有抵觸,即碰撞,除非有許多抵觸,普通hash索引效力很高,不然hash保護本錢較高,是以哈希索引平日用在選擇性較高的列下面。哈希索引的構造決議了它的特色:
1. hash索引只是hash值次序分列,跟表數據沒有關系,沒法運用於order by;
2. hash索引是對它的一切列盤算哈希值,是以在查詢時,必需帶上一切列,好比有(a, b)哈希索引,查詢時必需 where a = 1 and b = 2,少任何一個不可;
3. hash索引只能用於比擬查詢 = 或 IN,其他規模查詢有效,實質照樣因不存儲表數據;
4. 一旦湧現碰撞,hash索引必需遍歷一切的hash值,將地址所指向數據逐個比擬,直到找到一切相符前提的行。
填坑
後面提到經由過程explain的key_len字段,可年夜致估量出用了哪些列,索引列的長度跟索引列的數據類型直接相干,普通,我們說int是4字節,bigint8字節,char是1字節,斟酌到建表時要指定字符集,好比utf8,還跟選的字符集有關(==!),在utf8下邊,一個char是3字節,然則曉得這些仍不克不及說key_len就是將用到的索引列的數據類型代表字節數一加不就完啦?現實總有點差別,測試辦法比擬機械(以下基於mysql 5.5.2)
建表,加索引,int型
--測試表
create table keyLenTest1(
id int primary key auto_increment,
typeKey int default 0 ,
add_time timestamp not null default current_timestamp
) charset utf8
--添加索引
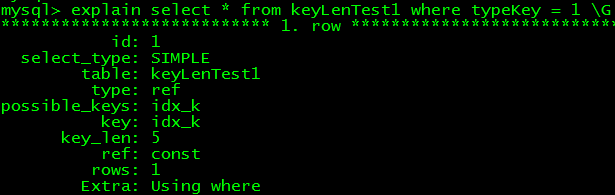
alter table keyLenTest1 add index idx_k(typeKey);
可知int型索引默許長度為5,在4字節基本上+1
char型
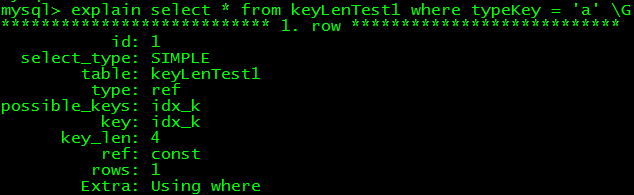
--改成char型,1個字符 alter table keyLenTest1 modify typeKey char(1);
--改成char型,2個字符 alter table keyLenTest1 modify typeKey char(2);
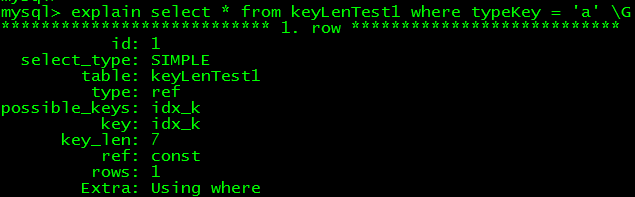
可知,char型初始是4字節(3+1 bytes),後續依照3字節遞增
varchar型
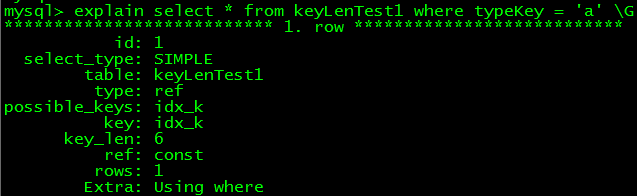
--改成varchar型,1個字符 alter table keyLenTest1 modify typeKey varchar(1);
--改成varchar型,2個字符 alter table keyLenTest1 modify typeKey varchar(2);
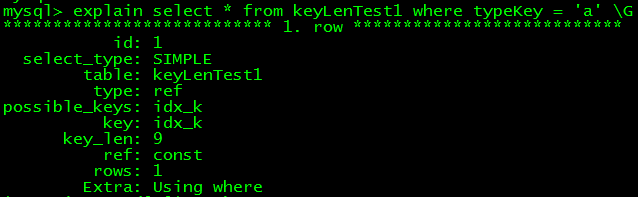
可知,varchar型,1個字符時,key_len為6,今後以3字節遞增
所以,假如一個語句用到了int、char、varchar,key_len若何盤算和用了哪些索引列應當很清晰了。
假如想懂得的更具體點,explain各字段意義,索引的更多細節,除explain,還有show profiles、慢查詢日記等(沒細看),推舉看高機能mysql,究竟俺寫的太浮淺。