在Hadoop集群情況中為MySQL裝置設置裝備擺設Sqoop的教程。本站提示廣大學習愛好者:(在Hadoop集群情況中為MySQL裝置設置裝備擺設Sqoop的教程)文章只能為提供參考,不一定能成為您想要的結果。以下是在Hadoop集群情況中為MySQL裝置設置裝備擺設Sqoop的教程正文
Sqoop是一個用來將Hadoop和關系型數據庫中的數據互相轉移的對象,可以將一個關系型數據庫(例如 : MySQL ,Oracle ,Postgres等)中的數據導進到Hadoop的HDFS中,也能夠將HDFS的數據導進到關系型數據庫中。
Sqoop中一年夜亮點就是可以經由過程hadoop的mapreduce把數據從關系型數據庫中導入數據到HDFS。
1、裝置sqoop
1、下載sqoop緊縮包,並解壓
緊縮包分離是:sqoop-1.2.0-CDH3B4.tar.gz,hadoop-0.20.2-CDH3B4.tar.gz, Mysql JDBC驅動包mysql-connector-java-5.1.10-bin.jar
[root@node1 ~]# ll
drwxr-xr-x 15 root root 4096 Feb 22 2011 hadoop-0.20.2-CDH3B4 -rw-r--r-- 1 root root 724225 Sep 15 06:46 mysql-connector-java-5.1.10-bin.jar drwxr-xr-x 11 root root 4096 Feb 22 2011 sqoop-1.2.0-CDH3B4
2、將sqoop-1.2.0-CDH3B4拷貝到/home/hadoop目次下,並將Mysql JDBC驅動包和hadoop-0.20.2-CDH3B4下的hadoop-core-0.20.2-CDH3B4.jar至sqoop-1.2.0-CDH3B4/lib下,最初修正一部屬主。
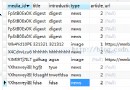
[root@node1 ~]# cp mysql-connector-java-5.1.10-bin.jar sqoop-1.2.0-CDH3B4/lib [root@node1 ~]# cp hadoop-0.20.2-CDH3B4/hadoop-core-0.20.2-CDH3B4.jar sqoop-1.2.0-CDH3B4/lib [root@node1 ~]# chown -R hadoop:hadoop sqoop-1.2.0-CDH3B4 [root@node1 ~]# mv sqoop-1.2.0-CDH3B4 /home/hadoop [root@node1 ~]# ll /home/hadoop
total 35748 -rw-rw-r-- 1 hadoop hadoop 343 Sep 15 05:13 derby.log drwxr-xr-x 13 hadoop hadoop 4096 Sep 14 16:16 hadoop-0.20.2 drwxr-xr-x 9 hadoop hadoop 4096 Sep 14 20:21 hive-0.10.0 -rw-r--r-- 1 hadoop hadoop 36524032 Sep 14 20:20 hive-0.10.0.tar.gz drwxr-xr-x 8 hadoop hadoop 4096 Sep 25 2012 jdk1.7 drwxr-xr-x 12 hadoop hadoop 4096 Sep 15 00:25 mahout-distribution-0.7 drwxrwxr-x 5 hadoop hadoop 4096 Sep 15 05:13 metastore_db -rw-rw-r-- 1 hadoop hadoop 406 Sep 14 16:02 scp.sh drwxr-xr-x 11 hadoop hadoop 4096 Feb 22 2011 sqoop-1.2.0-CDH3B4 drwxrwxr-x 3 hadoop hadoop 4096 Sep 14 16:17 temp drwxrwxr-x 3 hadoop hadoop 4096 Sep 14 15:59 user
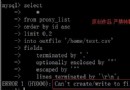
3、設置裝備擺設configure-sqoop,正文失落關於HBase和ZooKeeper的檢討
[root@node1 bin]# pwd
/home/hadoop/sqoop-1.2.0-CDH3B4/bin
[root@node1 bin]# vi configure-sqoop
#!/bin/bash
#
# Licensed to Cloudera, Inc. under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
.
.
.
# Check: If we can't find our dependencies, give up here.
if [ ! -d "${HADOOP_HOME}" ]; then
echo "Error: $HADOOP_HOME does not exist!"
echo 'Please set $HADOOP_HOME to the root of your Hadoop installation.'
exit 1
fi
#if [ ! -d "${HBASE_HOME}" ]; then
# echo "Error: $HBASE_HOME does not exist!"
# echo 'Please set $HBASE_HOME to the root of your HBase installation.'
# exit 1
#fi
#if [ ! -d "${ZOOKEEPER_HOME}" ]; then
# echo "Error: $ZOOKEEPER_HOME does not exist!"
# echo 'Please set $ZOOKEEPER_HOME to the root of your ZooKeeper installation.'
# exit 1
#fi
4、修正/etc/profile和.bash_profile文件,添加Hadoop_Home,調劑PATH
[hadoop@node1 ~]$ vi .bash_profile
# .bash_profile # Get the aliases and functions if [ -f ~/.bashrc ]; then . ~/.bashrc fi # User specific environment and startup programs HADOOP_HOME=/home/hadoop/hadoop-0.20.2 PATH=$HADOOP_HOME/bin:$PATH:$HOME/bin export HIVE_HOME=/home/hadoop/hive-0.10.0 export MAHOUT_HOME=/home/hadoop/mahout-distribution-0.7 export PATH HADOOP_HOME
2、測試Sqoop
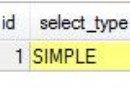
1、檢查mysql中的數據庫:
[hadoop@node1 bin]$ ./sqoop list-databases --connect jdbc:mysql://192.168.1.152:3306/ --username sqoop --password sqoop
13/09/15 07:17:16 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 13/09/15 07:17:17 INFO manager.MySQLManager: Executing SQL statement: SHOW DATABASES information_schema mysql performance_schema sqoop test
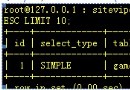
2、將mysql的表導入到hive中:
[hadoop@node1 bin]$ ./sqoop import --connect jdbc:mysql://192.168.1.152:3306/sqoop --username sqoop --password sqoop --table test --hive-import -m 1
13/09/15 08:15:01 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 13/09/15 08:15:01 INFO tool.BaseSqoopTool: Using Hive-specific delimiters for output. You can override 13/09/15 08:15:01 INFO tool.BaseSqoopTool: delimiters with --fields-terminated-by, etc. 13/09/15 08:15:01 INFO tool.CodeGenTool: Beginning code generation 13/09/15 08:15:01 INFO manager.MySQLManager: Executing SQL statement: SELECT t.* FROM `test` AS t LIMIT 1 13/09/15 08:15:02 INFO manager.MySQLManager: Executing SQL statement: SELECT t.* FROM `test` AS t LIMIT 1 13/09/15 08:15:02 INFO orm.CompilationManager: HADOOP_HOME is /home/hadoop/hadoop-0.20.2/bin/.. 13/09/15 08:15:02 INFO orm.CompilationManager: Found hadoop core jar at: /home/hadoop/hadoop-0.20.2/bin/../hadoop-0.20.2-core.jar 13/09/15 08:15:03 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/a71936fd2bb45ea6757df22751a320e3/test.jar 13/09/15 08:15:03 WARN manager.MySQLManager: It looks like you are importing from mysql. 13/09/15 08:15:03 WARN manager.MySQLManager: This transfer can be faster! Use the --direct 13/09/15 08:15:03 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path. 13/09/15 08:15:03 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql) 13/09/15 08:15:03 INFO mapreduce.ImportJobBase: Beginning import of test 13/09/15 08:15:04 INFO manager.MySQLManager: Executing SQL statement: SELECT t.* FROM `test` AS t LIMIT 1 13/09/15 08:15:05 INFO mapred.JobClient: Running job: job_201309150505_0009 13/09/15 08:15:06 INFO mapred.JobClient: map 0% reduce 0% 13/09/15 08:15:34 INFO mapred.JobClient: map 100% reduce 0% 13/09/15 08:15:36 INFO mapred.JobClient: Job complete: job_201309150505_0009 13/09/15 08:15:36 INFO mapred.JobClient: Counters: 5 13/09/15 08:15:36 INFO mapred.JobClient: Job Counters 13/09/15 08:15:36 INFO mapred.JobClient: Launched map tasks=1 13/09/15 08:15:36 INFO mapred.JobClient: FileSystemCounters 13/09/15 08:15:36 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=583323 13/09/15 08:15:36 INFO mapred.JobClient: Map-Reduce Framework 13/09/15 08:15:36 INFO mapred.JobClient: Map input records=65536 13/09/15 08:15:36 INFO mapred.JobClient: Spilled Records=0 13/09/15 08:15:36 INFO mapred.JobClient: Map output records=65536 13/09/15 08:15:36 INFO mapreduce.ImportJobBase: Transferred 569.6514 KB in 32.0312 seconds (17.7842 KB/sec) 13/09/15 08:15:36 INFO mapreduce.ImportJobBase: Retrieved 65536 records. 13/09/15 08:15:36 INFO hive.HiveImport: Removing temporary files from import process: test/_logs 13/09/15 08:15:36 INFO hive.HiveImport: Loading uploaded data into Hive 13/09/15 08:15:36 INFO manager.MySQLManager: Executing SQL statement: SELECT t.* FROM `test` AS t LIMIT 1 13/09/15 08:15:36 INFO manager.MySQLManager: Executing SQL statement: SELECT t.* FROM `test` AS t LIMIT 1 13/09/15 08:15:41 INFO hive.HiveImport: Logging initialized using configuration in jar:file:/home/hadoop/hive-0.10.0/lib/hive-common-0.10.0.jar!/hive-log4j.properties 13/09/15 08:15:41 INFO hive.HiveImport: Hive history file=/tmp/hadoop/hive_job_log_hadoop_201309150815_1877092059.txt 13/09/15 08:16:10 INFO hive.HiveImport: OK 13/09/15 08:16:10 INFO hive.HiveImport: Time taken: 28.791 seconds 13/09/15 08:16:11 INFO hive.HiveImport: Loading data to table default.test 13/09/15 08:16:12 INFO hive.HiveImport: Table default.test stats: [num_partitions: 0, num_files: 1, num_rows: 0, total_size: 583323, raw_data_size: 0] 13/09/15 08:16:12 INFO hive.HiveImport: OK 13/09/15 08:16:12 INFO hive.HiveImport: Time taken: 1.704 seconds 13/09/15 08:16:12 INFO hive.HiveImport: Hive import complete.
3、Sqoop 敕令
Sqoop年夜約有13種敕令,和幾種通用的參數(都支撐這13種敕令),這裡先列出這13種敕令。
接著列出Sqoop的各類通用參數,然後針對以上13個敕令列出他們本身的參數。Sqoop通用參數又分Common arguments,Incremental import arguments,Output line formatting arguments,Input parsing arguments,Hive arguments,HBase arguments,Generic Hadoop command-line arguments,上面解釋一下幾個經常使用的敕令:
1.Common arguments
通用參數,重要是針對關系型數據庫鏈接的一些參數
1)列出mysql數據庫中的一切數據庫
sqoop list-databases –connect jdbc:mysql://localhost:3306/ –username root –password 123456
2)銜接mysql並列出test數據庫中的表
sqoop list-tables –connect jdbc:mysql://localhost:3306/test –username root –password 123456
敕令中的test為mysql數據庫中的test數據庫稱號 username password分離為mysql數據庫的用戶暗碼
3)將關系型數據的表構造復制到hive中,只是復制表的構造,表中的內容沒有復制曩昔。
sqoop create-hive-table –connect jdbc:mysql://localhost:3306/test –table sqoop_test –username root –password 123456 –hive-table test
個中 –table sqoop_test為mysql中的數據庫test中的表 –hive-table
test 為hive中新建的表稱號
4)從關系數據庫導入文件到hive中
sqoop import –connect jdbc:mysql://localhost:3306/zxtest –username root –password 123456 –table sqoop_test –hive-import –hive-table s_test -m 1
5)將hive中的表數據導入到mysql中,在停止導入之前,mysql中的表
hive_test必需曾經提起創立好了。
sqoop export –connect jdbc:mysql://localhost:3306/zxtest –username root –password root –table hive_test –export-dir /user/hive/warehouse/new_test_partition/dt=2012-03-05
6)從數據庫導出表的數據到HDFS上文件
./sqoop import –connect jdbc:mysql://10.28.168.109:3306/compression –username=hadoop –password=123456 –table HADOOP_USER_INFO -m 1 –target-dir /user/test
7)從數據庫增量導入表數據到hdfs中
./sqoop import –connect jdbc:mysql://10.28.168.109:3306/compression –username=hadoop –password=123456 –table HADOOP_USER_INFO -m 1 –target-dir /user/test –check-column id –incremental append –last-value 3