處理MySQL中的Slave延遲成績的根本教程。本站提示廣大學習愛好者:(處理MySQL中的Slave延遲成績的根本教程)文章只能為提供參考,不一定能成為您想要的結果。以下是處理MySQL中的Slave延遲成績的根本教程正文
1、緣由剖析
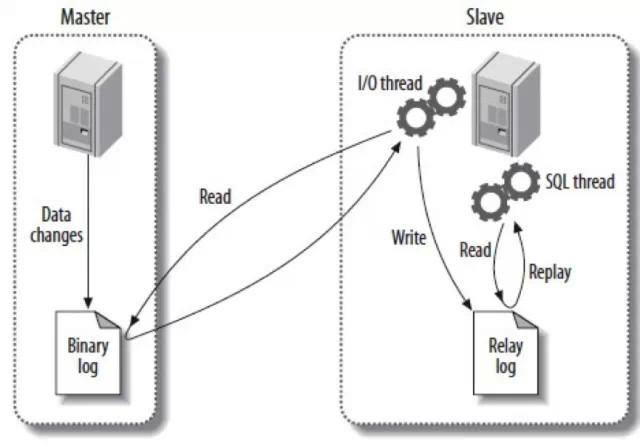
普通而言,slave絕對master延遲較年夜,其基本緣由就是slave上的復制線程沒方法真正做到並發。簡略說,在master上是並發形式(以InnoDB引擎為主)完成事務提交的,而在slave上,復制線程只要一個sql thread用於binlog的apply,所以難怪slave在高並發時會遠落伍master。
ORACLE MySQL 5.6版本開端支撐多線程復制,設置裝備擺設選項 slave_parallel_workers 便可完成在slave上多線程並發復制。不外,它只能支撐一個實例下多個 database 間的並發復制,其實不能真正做到多表並發復制。是以在較年夜並發負載時,slave照樣沒有方法實時追上master,須要想方法停止優化。
另外一個主要緣由是,傳統的MySQL復制是異步(asynchronous)的,也就是說在master提交完後,才在slave上再運用一遍,其實不是真正意義上的同步。哪怕是後來的Semi-sync Repication(半同步復制),也不是真同步,由於它只包管事務傳送到slave,但沒請求比及確認事務提交勝利。既然是異步,那確定若干會有延遲。是以,嚴厲意義上講,MySQL復制不克不及叫做MySQL同步(童貞座的面試官有能夠會在面試時把說成MySQL同步的一概刷失落哦)。
別的,很多人的不雅念裡,slave絕對沒那末主要,是以就不會供給和master雷同設置裝備擺設級其余辦事器。有的乃至不只應用更差的辦事器,並且還在下面跑多實例。
綜合這兩個重要緣由,slave想要盡量實時跟上master的進度,可以測驗考試采取以下幾種辦法:
采取MariaDB刊行版,它完成了絕對真正意義上的並行復制,其後果遠比ORACLE MySQL好的許多。在我的場景中,采取MariaDB作為slave的實例,簡直老是能實時跟上master。每一個表都要顯式指定主鍵,假如沒有指定主鍵的話,會招致在row形式下,每次修正都要全表掃描,特別是年夜表就異常恐怖了,延遲會更嚴重,乃至招致全部slave庫都被掛起,可參考案例:mysql主鍵的缺乏招致備庫hang;
運用法式端多做些事,讓MySQL端少干事,特別是和IO相干的運動,例如:前端經由過程內存CACHE或許當地寫隊列等,歸並屢次讀寫為一次,乃至清除一些寫要求;
停止適合的分庫、分表戰略,減小單庫單表復制壓力,防止因為單庫單表的的壓力招致全部實例的復制延遲;
其他進步IOPS機能的幾種辦法,依據後果好壞,我做了個簡略排序:
改換成SSD,或許PCIe SSD等IO裝備,其IOPS才能的晉升是通俗15K SAS盤的數以百倍、萬倍,乃至幾十萬倍計;
加年夜物理內存,響應進步InnoDB Buffer Pool年夜小,讓更多熱數據放在內存中,下降產生物理IO的頻率;
調劑文件體系為 XFS 或 ReiserFS,比擬ext3可以極年夜水平進步IOPS才能。在高IOPS壓力下,比擬ext4有更穩健的IOPS表示(有人以為 XFS 在特殊的場景下會有很年夜的成績,但我們除殘剩磁盤空間少於10%時激發丟數據外,其他的還沒有碰到);
調劑RAID級別為raid 1+0,它比擬raid1、raid5等更能進步IOPS機能。假如曾經全體是SSD裝備了,可以2塊盤做成RAID 1,或許多快盤做成RAID 5(而且可以設置全局熱備盤,進步陣列容錯性),乃至有些土豪用戶直接將多塊SSD盤構成RAID 50;
調劑RAID的寫cache戰略為WB或FORCE WB,概況請參考:經常使用PC辦事器陣列卡、硬盤安康監控 和 PC辦事器陣列卡治理簡略單純手冊;
調劑內核的io scheduler,優先應用deadline,假如是SSD,則可使用noop戰略,比擬默許的cfq,個體請客下對IOPS的機能晉升至多是數倍的。
二 、若何處理
日常平凡吸收的比擬多關於主備延時的報警:
check_ins_slave_lag (err_cnt:1)critical-slavelag on ins:3306=39438
信任slave 延遲是MySQL dba 碰到的一個老發展談的成績了。先來剖析一下slave延遲帶來的風險
a. 異常情形下,主從HA沒法切換。HA 軟件須要檢討數據的分歧性,延遲時,主備紛歧致。
b. 備庫復制hang會招致備份掉敗(flush tables with read lock會900s超時)
c. 以 slave 為基准停止的備份,數據不是最新的,而是延遲。
面臨此類成績我們若何處理 ,若何躲避?剖析一下招致備庫延遲的幾種緣由
1. ROW形式無主鍵、無索引或索引辨別度不高.
有以下特點
a. show slave status 顯示position一向沒有變
b. show open tables 顯示某個表一向是 in_use 為 1
c. show create table 檢查表構造可以看到無主鍵,或許無任何索引,或許索引辨別度很差。
處理辦法:
a. 找到表辨別度比擬高的幾個字段, 可使用這個辦法斷定:
select count(*) from xx; select count(*) from (select distinct xx from xxx) t;
假如2個查詢count(*)的成果差不多,解釋可以對這些字段加索引
b. 備庫stop slave;
能夠會履行比擬久,由於須要回滾事務。
c. 備庫
set sql_log_bin=0; alter table xx add key xx(xx);
老的版本slave運用binlog時只會選擇第一個索引,須要把新加的索引放在最後面,可以先把老的索引刪失落,建新的索引,再把老的索引建上。可以放到一個sql中履行。
d. 備庫start slave
假如是innodb,可以經由過程show innodb status來檢查 rows_inserted,updated,deleted,selected這幾個目標來斷定。
假如每秒修正的記載數比擬多,解釋復制正在以比擬快的速度履行。
2 MIXED形式無索引或SQL慢
在從庫上show full processlist 檢查到正在履行的SQL。
處理辦法:
a. SQL比擬簡略, 則檢討能否缺乏索引,並添加索引。
b. 另外一類是 insert into select from的語句,假如select 裡包括group by,多表聯系關系,能夠效力會比擬低。
這類可以到主庫把binlog_format改成row。
3 主庫上有年夜事務,招致從庫延時
景象解析binlog 發明相似於下圖的情形看
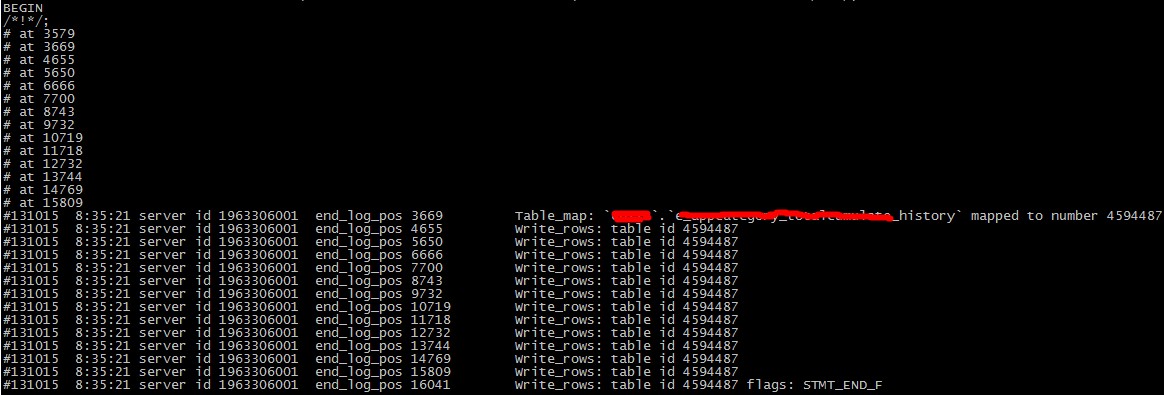
處理辦法:
與開辟溝通,增長緩存,異步寫入數據庫,削減直接對db的年夜量寫入。
4. 主庫寫入頻仍,從庫壓力跟不上招致延時
此類緣由的重要景象是數據庫的 IUD 操作異常多,slave因為sql_thread單線程的緣由追不上主庫。
處理辦法:
a 進級從庫的硬件設置裝備擺設,好比ssd,fio.
b 應用@丁奇的預熱對象-relay fetch
在備庫sql線程履行更新之前,事後將響應的數據加載到內存中,其實不能進步sql_thread線程履行sql的才能,也不克不及加速io_thread線程讀取日記的速度。
c 應用多線程復制 阿裡MySQL團隊完成的計劃--基於行的並行復制。
該計劃許可對統一張表停止修正的兩個事務並行履行,只需這兩個事務修正了表中的分歧的行。這個計劃可以到達事務間更高的並發度,然則局限是必需應用Row格局的binlog。由於只要應用 Row格局的binlog才可以曉得一個事務所修正的行的規模,而應用Statement格局的binlog只能曉得修正的表對象。
5. 數據庫中存在年夜量myisam表,在備份的時刻招致slave 延遲

因為xtrabackup 對象備份到最初會履行flash tables with read lock ,對數據庫停止鎖表以便停止分歧性備份,然後關於myisam表 鎖,會障礙salve_sql_thread 停止運轉進而招致hang
該成績今朝的比擬好的處理方法是修正表構造為innodb存儲引擎的表。