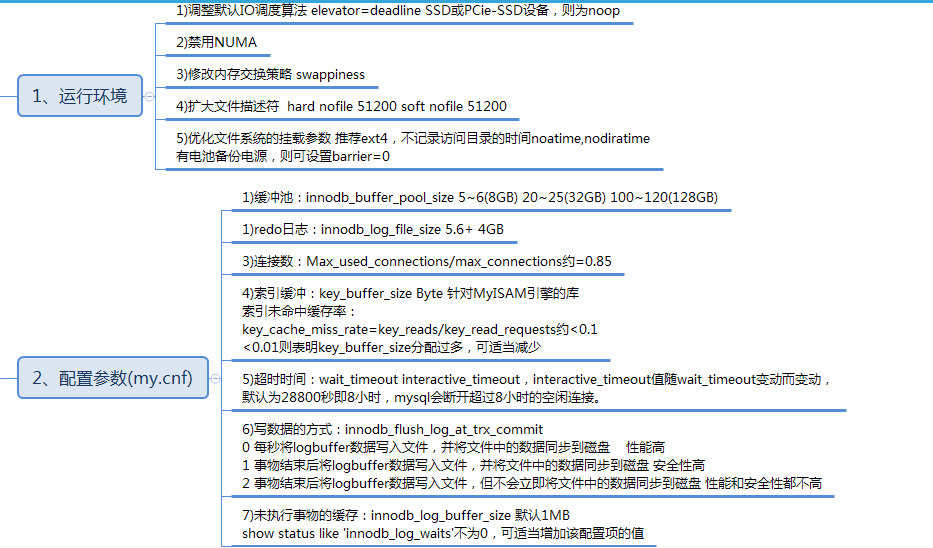
詳解MySql根本查詢、銜接查詢、子查詢、正則表達查詢。本站提示廣大學習愛好者:(詳解MySql根本查詢、銜接查詢、子查詢、正則表達查詢)文章只能為提供參考,不一定能成為您想要的結果。以下是詳解MySql根本查詢、銜接查詢、子查詢、正則表達查詢正文
查詢數據指從數據庫中獲得所須要的數據。查詢數據是數據庫操作中最經常使用,也是最主要的操作。用戶可以依據本身對數據的需求,應用分歧的查詢方法。經由過程分歧的查詢方法,可以取得分歧的數據。MySQL中是應用SELECT語句來查詢數據的。在這一章中將講授的內容包含。
1、查詢語句的根本語法
2、在單表上查詢數據
3、應用聚合函數查詢數據
4、多表上結合查詢
5、子查詢
6、歸並查詢成果
7、為表和字段取別號
8、應用正則表達式查詢
甚麼是查詢?
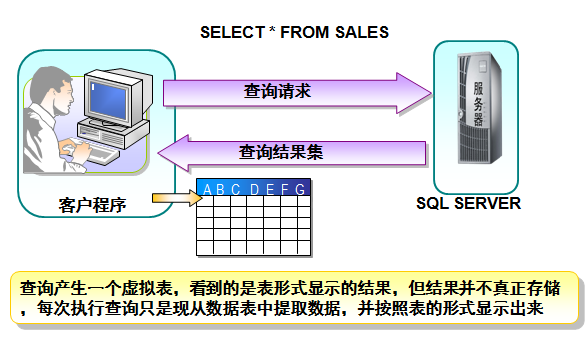
怎樣查的?

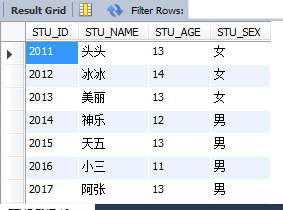
數據的預備以下:
create table STUDENT( STU_ID int primary KEY, STU_NAME char(10) not null, STU_AGE smallint unsigned not null, STU_SEX char(2) not null ); insert into STUDENT values(2001,'小王',13,'男'); insert into STUDENT values(2002,'明明',12,'男'); insert into STUDENT values(2003,'紅紅',14,'女'); insert into STUDENT values(2004,'小花',13,'女'); insert into STUDENT values(2005,'天兒',15,'男'); insert into STUDENT values(2006,'阿獵',13,'女'); insert into STUDENT values(2007,'阿貓',16,'男'); insert into STUDENT values(2008,'阿狗',17,'男'); insert into STUDENT values(2009,'黑子',14,'男'); insert into STUDENT values(2010,'小玉',13,'女'); insert into STUDENT values(2011,'頭頭',13,'女'); insert into STUDENT values(2012,'冰冰',14,'女'); insert into STUDENT values(2013,'俏麗',13,'女'); insert into STUDENT values(2014,'神樂',12,'男'); insert into STUDENT values(2015,'天五',13,'男'); insert into STUDENT values(2016,'小三',11,'男'); insert into STUDENT values(2017,'阿張',13,'男'); insert into STUDENT values(2018,'阿傑',13,'男'); insert into STUDENT values(2019,'阿寶',13,'女'); insert into STUDENT values(2020,'年夜王',14,'男');
然後這是先生成就表,個中界說了外鍵束縛
create table GRADE( STU_ID INT NOT NULL, STU_SCORE INT, foreign key(STU_ID) references STUDENT(STU_ID) ); insert into GRADE values(2001,90); insert into GRADE values(2002,89); insert into GRADE values(2003,67); insert into GRADE values(2004,78); insert into GRADE values(2005,89); insert into GRADE values(2006,78); insert into GRADE values(2007,99); insert into GRADE values(2008,87); insert into GRADE values(2009,70); insert into GRADE values(2010,71); insert into GRADE values(2011,56); insert into GRADE values(2012,85); insert into GRADE values(2013,65); insert into GRADE values(2014,66); insert into GRADE values(2015,77); insert into GRADE values(2016,79); insert into GRADE values(2017,82); insert into GRADE values(2018,88); insert into GRADE values(2019,NULL); insert into GRADE values(2020,NULL);
1、查詢語句的根本語法
查詢數據是指從數據庫中的數據表或視圖中獲得所須要的數據,在MySQL中,可使用SELECT語句來查詢數據。依據查詢前提的分歧,數據庫體系會找到分歧的數據。
SELECT語句的根本語法格局以下:
SELECT 屬性列表 FROM 表名或視圖列表 [WHERE 前提表達式1] [GROUP BY 屬性名1 [HAVING 前提表達式2]] [ORDER BY 屬性名2 [ASC|DESC]]
屬性列表:表現須要查詢的字段名。
表名或視圖列表:表現行將停止數據查詢的數據表或許視圖,表或視圖可以有多個。
前提表達式1:設置查詢的前提。
屬性名1:表現按該字段中的數據停止分組。
前提表達式2:表現知足該表達式的數據能力輸入。
屬性2:表現按該字段中的數據停止排序,排序方法由ASC或DESC參數指定。
ASC:表現按升序的次序停止排序。即表現值依照從小到年夜的次序分列。這是默許參數。
DESC:表現按降序的次序停止排序。即表現值依照從年夜到小的次序分列。
假如有WHERE子句,就依照“前提表達式1”指定的前提停止查詢;假如沒有WHERE子句,就查詢一切記載。
假如有GROUP BY子句,就依照“屬性名1”指定的字段停止分組;假如GROUP BY子句前面帶著HAVING症結字,那末只要知足“前提表達式2”中指定的前提的記載能力夠輸入。GROUP BY子句平日和COUNT()、SUM()等聚合函數一路應用。
假如有ORDER BY子句,就依照“屬性名2”指定的字段停止排序。排序方法由ASC或DESC參數指定。默許的排序方法為ASC。
2、在單表上查詢數據
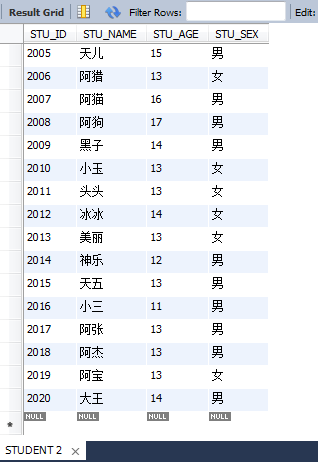
2.1、查詢一切字段
select * from STUDENT;
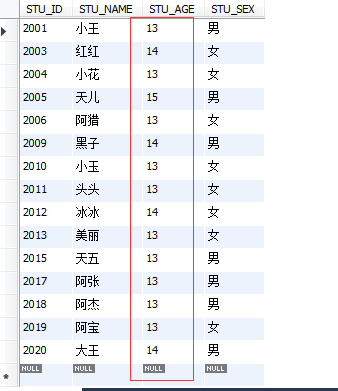
2.2、按前提查詢

(1) 比擬運算符
> , < ,= , != (< >),>= , <=
select * from STUDENT where STU_AGE>13;
in(v1,v2..vn) ,相符v1,v2,,,vn能力被查出
IN症結字可以斷定某個字段的值能否在指定的聚集中。假如字段的值在聚集中,則知足查詢前提,該記載將被查詢出來。假如不在聚集中,則不知足查詢前提。其語律例則以下:[ NOT ] IN ( 元素1, 元素2, …, 元素n )
select * from STUDENT where STU_AGE in(11,12);

between v1 and v2 在v1至v2之間(包括v1,v2)
BETWEEN AND症結字可以判讀某個字段的值能否在指定的規模內。假如字段的值在指定規模內,則知足查詢前提,該記載將被查詢出來。假如不在指定規模內,則不知足查詢前提。其語律例則以下:
[ NOT ] BETWEEN 取值1 AND 取值2
select * from STUDENT where STU_AGE between 13 and 15;
(2)邏輯運算符
not ( ! ) 邏輯非
select * from STUDENT where STU_AGE NOT IN(13,14,16);
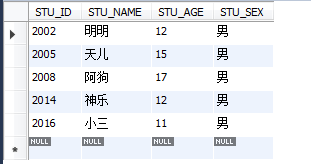
or ( || ) 邏輯或
OR症結字也能夠用來結合多個前提停止查詢,然則與AND症結字分歧。應用OR症結字時,只需知足這幾個查詢前提的個中一個,如許的記載將會被查詢出來。假如不知足這些查詢前提中的任何一個,如許的記載將被消除失落。OR症結字的語律例則以下:
前提表達式1 OR 前提表達式2 [ …OR 前提表達式n ]
個中,OR可以用來銜接兩個前提表達式。並且,可以同時應用多個OR症結字,如許可以銜接更多的前提表達式。
select * from STUDENT where STU_ID<2005 OR STU_ID>2015;

and ( && ) 邏輯與
AND症結字可以用來結合多個前提停止查詢。應用AND症結字時,只要同時知足一切查詢前提的記載會被查詢出來。假如不知足這些查詢前提的個中一個,如許的記載將被消除失落。AND症結字的語律例則以下:
前提表達式1 AND 前提表達式2 [ … AND 前提表達式n ]
個中,AND可以銜接兩個前提表達式。並且,可以同時應用多個AND症結字,如許可以銜接更多的前提表達式。
(3)隱約查詢
like 像
LIKE症結字可以婚配字符串能否相等。假如字段的值與指定的字符串相婚配,則知足查詢前提,該記載將被查詢出來。假如與指定的字符串不婚配,則不知足查詢前提。其語律例則以下:[ NOT ] LIKE '字符串' “NOT”可選參數,加上 NOT表現與指定的字符串不婚配時知足前提;“字符串”表現指定用來婚配的字符串,該字符串必需加單引號或雙引號。
通配符:
% 隨意率性字符
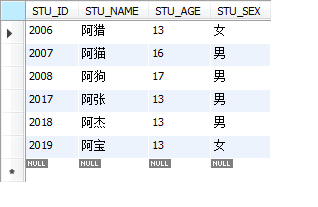
select * from STUDENT where STU_NAME LIKE '%王';
表現婚配任何故王開頭的

select * from STUDENT where STU_NAME LIKE '阿%';
表現婚配任何故阿開首的
_ 單個字符
好比說拔出
select * from STUDENT where STU_NAME LIKE '阿%';
然後
select * from STUDENT where STU_NAME LIKE '阿%';
查詢的成果為空

然則假如下前面加兩個_符號
select * from STUDENT where STU_NAME LIKE '_下__';
查詢成果不為空

“字符串”參數的值可所以一個完全的字符串,也能夠是包括百分號(%)或許下劃線(_)的通配字符。兩者有很年夜差別
“%”可以代表隨意率性長度的字符串,長度可認為0;
“_”只能表現單個字符。
假如要婚配姓張且名字只要兩個字的人的記載,“張”字前面必需要有兩個“_”符號。由於一個漢字是兩個字符,而一個“_”符號只能代表一個字符。
(4)空值查詢
IS NULL症結字可以用來斷定字段的值能否為空值(NULL)。假如字段的值是空值,則知足查詢前提,該記載將被查詢出來。假如字段的值不是空值,則不知足查詢前提。其語律例則以下:
IS [ NOT ] NULL
個中,“NOT”是可選參數,加上NOT表現字段不是空值時知足前提。
IS NULL是一個全體,不克不及將IS換成”=”.
3、應用聚合函數查詢數據
3.1、group by 分組
以下:
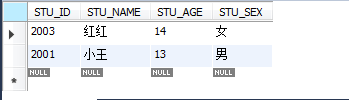
select * from STUDENT group by STU_SEX;
不加前提,那末就只取每一個分組的第一條。
假如想看分組的內容,可以加groub_concat
select STU_SEX,group_concat(STU_NAME) from STUDENT group by STU_SEX;

3.2、普通情形下group需與統計函數(聚合函數)一路應用才成心義
先預備一些數據:
create table EMPLOYEES(
EMP_NAME CHAR(10) NOT NULL,
EMP_SALARY INT unsigned NOT NULL,
EMP_DEP CHAR(10) NOT NULL
);
insert into EMPLOYEES values('小王',5000,'發賣部');
insert into EMPLOYEES values('阿小王',6000,'發賣部');
insert into EMPLOYEES values('工是不',7000,'發賣部');
insert into EMPLOYEES values('人人樂',3000,'資本部');
insert into EMPLOYEES values('滿頭年夜',4000,'資本部');
insert into EMPLOYEES values('生成一家',5500,'資本部');
insert into EMPLOYEES values('小花',14500,'資本部');
insert into EMPLOYEES values('年夜玉',15000,'研發部');
insert into EMPLOYEES values('條條',12000,'研發部');
insert into EMPLOYEES values('笨笨',13000,'研發部');
insert into EMPLOYEES values('我是天賦',15000,'研發部');
insert into EMPLOYEES values('無語了',6000,'審計部');
insert into EMPLOYEES values('甚麼人',5000,'審計部');
insert into EMPLOYEES values('不曉得',4000,'審計部');
mysql中的五種統計函數:
(1)max:求最年夜值
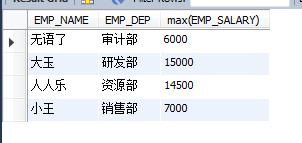
求每一個部分的最高工資:
select EMP_NAME,EMP_DEP,max(EMP_SALARY) from EMPLOYEES group by EMP_DEP;
(2)min:求最小值
求每一個部分的最仰工資:
select EMP_NAME,EMP_DEP,min(EMP_SALARY) from EMPLOYEES group by EMP_DEP;

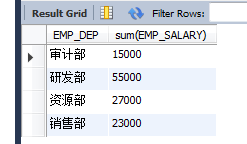
(3)sum:求總數和
求每一個部分的工資總和:
select EMP_DEP,sum(EMP_SALARY) from EMPLOYEES group by EMP_DEP
(4)avg:求均勻值
求每一個部分的工資均勻值
select EMP_DEP,avg(EMP_SALARY) from EMPLOYEES group by EMP_DEP;

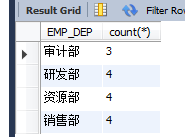
(5)count:求總行數
求每一個部分工資年夜於必定金額的人數
select EMP_DEP,count(*) from EMPLOYEES where EMP_SALARY>=500 group by EMP_DEP;
3.3、帶前提的groub by 字段 having,應用HAVING語句過濾分組數據
having 子句的感化是挑選知足前提的組,即在分組以後過濾數據,前提中常常包括聚組函數,應用having 前提顯示特定的組,也能夠應用多個分組尺度停止分組。
having 子句被限制子曾經在SELECT語句中界說的列和聚合表達式上。平日,你須要經由過程在HAVING子句中反復聚合函數表達式來援用聚合值,就如你在SELECT語句中做的那樣。
查找均勻工資年夜於6000的部分,並把部分裡的人全體列出來

4、多表上結合查詢
多表上結合查詢分為內銜接查詢和外銜接查詢
(1)隱式內銜接查詢
查找年夜於90分的先生信息:
(2)顯式內銜接查詢
用法:select .... from 表1 inner join 表2 on 前提表達式
(3)外銜接查詢
left join.左銜接查詢。
用法 :select .... from 表1 left join 表2 on 前提表達式
意思是表1查出來的數據不克不及為null,然則其對應表2的數據可認為null

right join就是相反的了,用法雷同
用left join的時刻,left join操作符左邊內外的信息都邑被查詢出來,右邊內外沒有的記載會填空(NULL).right join亦然;inner join的時刻則只要前提適合的才會顯示出來
full join()
完全內部聯接前往左表和右表中的一切行。當某行在另外一個表中沒有婚配行時,則另外一個表的選擇列表列包括空值。假如表之間有婚配行,則全部成果集行包括基表的數據
值。
僅當至多有一個同屬於兩表的行相符聯接前提時,內聯接才前往行。內聯接清除與另外一個表中的任何行不婚配的行。而外聯接會前往 FROM 子句中提到的至多一個表或
視圖的一切行,只需這些行相符任何 WHERE 或 HAVING 搜刮前提。將檢索經由過程左向外聯接援用的左表的一切行,和經由過程右向外聯接援用的右表的一切行。完全外
部聯接中兩個表的一切行都將前往。
5、子查詢
以一個查詢select的成果作為另外一個查詢的前提
語法:select * from 表1 wher 前提1(select ..from 表2 where 前提2)
1、與In聯合
select * from STUDENT where STU_ID IN(select STU_ID from GRADE where STU_SCORE>85);
查找年夜於85分的先生信息

2、與EXISTS聯合
EXISTS和NOT EXISTS操作符只測試某個子查詢能否前往了數據行。假如是,EXISTS將是true,NOT EXISTS將是false。
select * from STUDENT where EXISTS (select STU_ID from GRADE where STU_SCORE>=100);
假如有先生成就年夜於100,才查詢一切的先生信息

3、ALL、ANY和SOME子查詢
any和all的操作符罕見用法是聯合一個絕對比擬操作符對一個數據列子查詢的成果停止測試。它們測試比擬值能否與子查詢所前往的全體或一部門值婚配。比喻說,假如比擬值小於或等於子查詢所前往的每個值,<=all將是true,只需比擬值小於或等於子查詢所前往的任何一個值,<=any將是true。some是any的一個同義詞。
select STU_ID from GRADE where STU_SCORE <67;

只需學號年夜於下面的隨意率性一個就顯示出來:
6、歸並查詢成果
歸並查詢成果是將多個SELECT語句的查詢成果歸並到一路。由於某種情形下,須要將幾個SELECT語句查詢出來的成果歸並起來顯示。
應用UNION症結字時,數據庫體系會將一切的查詢成果歸並到一路,然後去除失落雷同的記載。而UNION ALL症結字則只是簡略的歸並到一路。其語律例則以下:
SELECT語句1 UNION | UNION ALL SELECT語句2 UNION | UNION ALL …. SELECT語句n ;
7、排序與取數
7.1、order by
(1)order by price //默許升序分列
(2)order by price desc //降序分列
(3)order by price asc //升序分列,與默許一樣
(4)order by rand() //隨機分列,效力不高
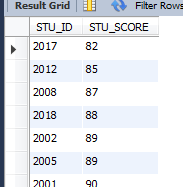
select * from GRADE where STU_SCORE >80 order by STU_SCORE;
默許是按升序的,
也能夠這麼寫
select * from GRADE where STU_SCORE >80 order by STU_SCORE ASC;
成果以下:
假如想換成降序的:
select * from GRADE where STU_SCORE >80 order by STU_SCORE desc;

7.2、limit
limit [offset,] N
offset 偏移量,可選,不寫則相當於limit 0,N
N 掏出條目
取分數最高的前5條
select * from GRADE order by STU_SCORE desc limit 5;
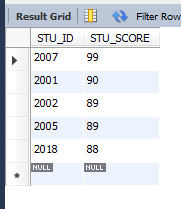
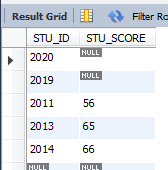
取分數最低的前5條
select * from GRADE order by STU_SCORE asc limit 5;
取分數排名在10-15之間的5條
select * from GRADE order by STU_SCORE desc limit 10,5

8、為表和字段取別號
應用AS來定名列
select STU_ID as '學號',STU_SCORE as '分數' from GRADE;
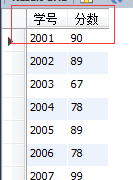
當表的稱號特殊長時,在查詢中直接應用表名很不便利。這時候可認為表取一個體名。用這個體名來取代表的稱號。
MySQL中為表取別號的根本情勢以下:
表名 表的別號

9、應用正則表達式查詢
正則表達式是用某種形式去婚配一類字符串的一個方法。例如,應用正則表達式可以查詢出包括A、B、C個中任一字母的字符串。正則表達式的查詢才能比通配字符的查詢才能更壯大,並且加倍的靈巧。正則表達式可以運用於異常龐雜查詢。
MySQL中,應用REGEXP症結字來婚配查詢正則表達式。其根本情勢以下:
屬性名 REGEXP '婚配方法'
在應用前先拔出一些數據:
insert into STUDENT values(2022,'12wef',13,'男'); insert into STUDENT values(2023,'faf_23',13,'男'); insert into STUDENT values(2024,'fafa',13,'女'); insert into STUDENT values(2025,'ooop',14,'男'); insert into STUDENT values(2026,'23oop',14,'男'); insert into STUDENT values(2027,'woop89',14,'男'); insert into STUDENT values(2028,'abcdd',11,'男');
(1)應用字符“^”可以婚配以特定字符或字符串開首的記載。
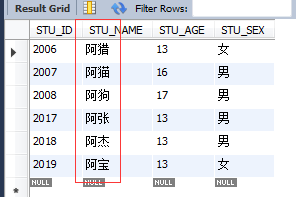
查詢一切以阿頭的
select * from STUDENT where STU_NAME REGEXP '^阿';
以數字開首
select * from STUDENT where STU_NAME REGEXP '^[0-9]';
(2)應用字符“$”可以婚配以特定字符或字符串開頭的記載
以數字開頭
select * from STUDENT where STU_NAME REGEXP '[0-9]$';

(3)用正則表達式來查詢時,可以用“.”來替換字符串中的隨意率性一個字符。
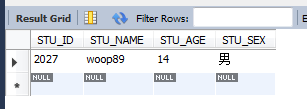
select * from STUDENT where STU_NAME REGEXP '^w....[0-9]$';
以w開首,以數字停止,中央有4個
(4)應用方括號([])
可以將須要查詢字符構成一個字符集。只需記載中包括方括號中的隨意率性字符,該記載將會被查詢出來。
例如,經由過程“[abc]”可以查詢包括a、b、c這三個字母中任何一個的記載。
應用方括號可以指定聚集的區間。
“[a-z]”表現從a-z的一切字母;
“[0-9]”表現從0-9的一切數字;
“[a-z0-9]”表現包括一切的小寫字母和數字。
“[a-zA-Z]”表現婚配一切字母。
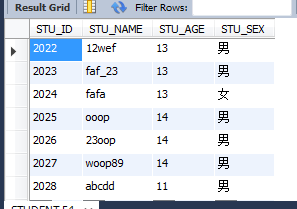
select * from STUDENT where STU_NAME REGEXP '[0-9a-z]';
查詢一切包括稀有字和小寫字母的
應用“[^字符聚集]”可以婚配指定字符之外的字符
(5){}表現湧現的次數
正則表達式中,“字符串{M}”表現字符串聯續湧現M次;“字符串{M,N}”表現字符串連持續湧現至多M次,最多N次。例如,“ab{2}”表現字符串“ab”持續湧現兩次。“ab{2,4}”表現字符串“ab”持續湧現至多兩次,最多四次。
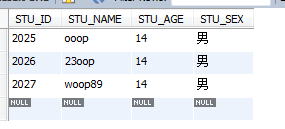
o湧現2次
select * from STUDENT where STU_NAME REGEXP 'o{2}';
(6)+表現到少湧現一次
fa至多湧現一次
select * from STUDENT where STU_NAME REGEXP '(fa)+';
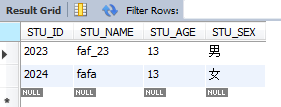
留意:
正則表達式可以婚配字符串。當表中的記載包括這個字符串時,便可以將該記載查詢出來。假如指定多個字符串時,須要用符號“|”離隔。只需婚配這些字符串中的隨意率性一個便可。每一個字符串與”|”之間不克不及有空格。由於,查詢進程中,數據庫體系會將空格也看成一個字符。如許就查詢不出想要的成果。
正則表達式中,“*”和“+”都可以婚配多個該符號之前的字符。然則,“+”至多表現一個字符,而“*”可以表現零個字符。
以上所述就是本文的全體內容,願望年夜家可以或許愛好。