Windows辦事器MySQL中文亂碼的處理辦法。本站提示廣大學習愛好者:(Windows辦事器MySQL中文亂碼的處理辦法)文章只能為提供參考,不一定能成為您想要的結果。以下是Windows辦事器MySQL中文亂碼的處理辦法正文
我們本身鼓搗mysql時,總免不了會碰到這個成績:拔出中文字符湧現亂碼,固然這是運維先給配好的情況,然則在本身機子上玩的時刻咧,總得曉得個一二吧,否則今後若何優雅的吹法螺B。
假如你也碰到了這個成績,咱先不談緣由,在PC自帶的cmd中(或許是mysql裝置版裝置後的Command Line客戶端,又或許是任務用的SecureCRT)嘗嘗後果。進入mysql情況,從頭開端操作。假定你的客戶端編碼是gbk或許utf8(這麼說太不嚴謹了,怎樣能假定呢,然則普通來講假設裝置後沒動過,cmd是gbk編碼,mysql裝置後的Command Line客戶端沒裝不記得,CRT看看Session Options外面的編碼設置,普通也會設置成utf8),履行一些語句:
1. 設置編碼客戶端、銜接、前往成果的字符集,先設置成latin1

2. 然後履行上面的看下各個字符是否是如許的

假如你的character_set_client、character_set_connection、character_set_results不是latin1,可以如許履行,把他們單個分離設置成latin1,好比設character_set_client,其他兩個一樣,確保這三個均是latin1(第一步的sql語句現實做的就是這件事),

3. 零丁創立一個數據庫db_latin1,固然是很簡略的了,測試嘛,創立時就設置數據庫的編碼的為latin1

4. 在它上面創立一張表tab_latin1,字符集也設置成latin1,這裡不設置字符也行,數據庫級曾經設置了,這裡只創立一個name字段
5. 拔出一些中文字符到表中,先解釋,本機的cmd編碼是gbk,檢查辦法是右鍵屬性->選項,看下以後代碼頁便可曉得

6. 檢查下成果

看吧,正常顯示中文了~~~
OK,都到這兒了你就不想曉得“為何我那樣設置就是不可”麼,固然得往下看看是不。上圖:

我們曉得mysql是客戶端-辦事器軟件,每次操作都是客戶端向辦事端發送要求,然後能夠會前往一些成果,這之間拔出的字符經由了一系列轉換。起首供我們編纂的客戶端自己就有一種編碼,好比PC真個敕令行默許是gbk,PC自帶notepad新建文本文件默許是ANSI,經常使用的文本編纂器如notepad++,我們能夠會設置默許編碼為utf8,就是說在編纂器上編纂,你所看到的自己就是一種編碼了。
1. 在客戶端編纂後,起首轉化為client對應的字符集,即下面打印出的character_set_client變量指導的字符集;
2. 向數據庫辦事發送要求,發送進程中,轉化為connection對應銜接字符集,即character_set_connection變量對應字符集;
3. 存儲到數據庫中,轉化為數據庫存儲的字符集,能夠是server級別(character_set_server)、database級別(character_set_database)或許表級別和列級別(這裡還要細說下);
4. 數據庫收到要求,履行查詢獲得成果,再次轉化為results對應字符集,即character_set_results變量所指,該成果前往到客戶端上;
5. 成果來了,是依照results字符集編碼的,那我們讓這個成果顯示的客戶端對象它支撐甚麼樣的編碼也很主要,這決議了它若何去解碼成果。假設這個成果是utf8編碼,前往給某客戶端了,但這個客戶端只要ANSI編碼,那固然不克不及顯示正常,好比它前往到SecureCRT,成果顯示不正常,然則CRT支撐多種編碼,我們手動將它調成utf8編碼,那它就又顯示正常了,所以嚴厲來講這一步算不上,只是跟客戶端前提有關,究竟當我們曉得後將客戶端調劑成正常的編碼或許原來就支撐轉換results的編碼後,這一步就不存在了。
在下面的第3步中,從銜接字符集編碼轉化為數據庫存儲應用的編碼時,要分幾種情形,普通我們在裝mysql時,特殊是32位裝置版本時,中央有一個選擇編碼的步調,年夜多會選擇utf8編碼,這時候體系便可能會把一系列的字符集變量均設置成了utf8,好比character_set_server、character_set_connection、character_set_database等等。也就是說這個character_set_server變量在你啟動mysql辦事的事前就被設置好了,我們可以稱它為辦事器級編碼,那我們在建表前,先得創立數據庫,在創立數據庫時,我們曉得可以顯式指定編碼的,好比最開首時我創立時顯式指定采取latin1字符集,也能夠不指定,假如不指定的話,它將采取辦事器級的字符集,即character_set_server,同理在創立表時,也可不指定編碼,不指定的話,采取數據庫級編碼,級character_set_database,加倍同理在創立表中列字段時也可指定編碼,不指定編碼的話將采取表級別字符集,是以有這麼一個繼續關系在這:
character_set_server => character_set_database => character set in table(無此變量) => character set column(無此變量)
mysql創立表可以細化到這四個條理,不是每層都必需指定,默許應用上一級的字符集(字符校訂規矩也是如許的,collation,稍後解釋)。
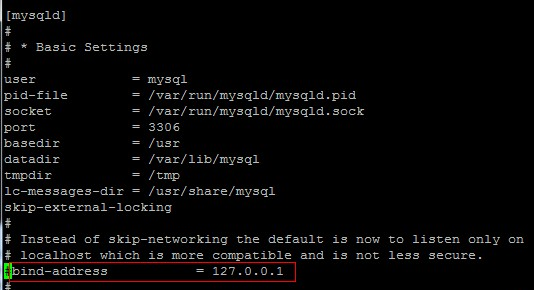
那末有無能夠character_set_server沒有指定呢,假如任何處所都沒指定,特殊長短裝置版中,假如忘了,mysql在編譯時默許采取latin1,為了應對這類情形,特殊長短裝置版本中在設置裝備擺設mysql時,常常須要手動設置裝備擺設mysql設置裝備擺設文件mysql.ini,個中就有年夜概這麼一項:

在設置裝備擺設文件中默許采取的字符集,是以假如指定了character_set_server默許就會采取它,如許其他條理都不指定的話順次繼續。
其他的,character_set_filesystem:把操作體系上的字符轉換成此字符集,即把character_set_client轉換成character_set_filesystem,默許為binary則不轉換,character_set_system:此變量老是utf8,為存儲體系元字符的字符集,如表名、列名、用戶名等,character_set_dir:很顯著是指導一個目次的變量,翻開這個目次,裡邊寄存的是mysql的各類用於編碼字符集的xml格局文件。以上三個值在處理亂碼成績時根本可疏忽。
好,轉換流程和各變量的寄義清晰了,就要弄清晰哪些字符集編碼之間可以轉換,能轉換能夠也是在必定編碼規模內的字符能轉換,不至於湧現亂碼乃至破壞。破壞了就再也沒法准確顯示了,哪怕設置是准確的,復原是復原不回來的。固然關於字符之間的轉化情形許多,字符集有那末多種,隨意兩個之間都可以轉換一下嘗嘗,不克不及逐個羅列,可以參考這篇文章:http://www.imcjd.com/?p=1324,它針對常常用到的字符轉換作了一些轉換比擬和測試。
個中,可以懂得到,完整婚配的轉換是確定沒有成績的,好比,gbk->gbk,utf8->utf8,latin1->latin1;轉換為單字節編碼的latin1也沒成績,好比gbk->latin1、utf8->latin1;單字節編碼(latin1)轉為其他在某些編碼某些規模內能夠會湧現轉換不全,好比latin1->gbk(很特別的中文),或許編碼長度轉變,好比latin1->utf8,變成2、3等字節數。
上面援用另外一篇文章(http://hi.百度.com/cuttinger/item/f4e79726a60ab450c28d59da)中的一段。
【Latin1是一種很罕見的字符集,這類字符集是單字節編碼,向下兼容ASCII,其編碼規模是0x00-0xFF,0x00-0x7F之間完整和ASCII分歧,0x80-0x9F之間是掌握字符,0xA0-0xFF之間是文字符號。很顯著,Latin1籠罩了一切的單字節,是以,可以將隨意率性字符串保留在latin1字符集中,而不消擔憂有內容不相符latin1的編碼標准而被擯棄。——gbk和utf8是多字節編碼,沒有這類特征。
mysql應用者常常應用Latin1的這類全籠罩特征,將其它類型的字符串,gbk,utf8,big5等,保留在latin1列中。保留的進程中沒稀有據喪失,只需原樣掏出來,便又是正當的gbk/utf8/big字符串。假如將gbk字符串保留在utf8列中,則gbk字符串中那些不相符utf8編碼格局的內容,會被擯棄,保留的內容沒法原樣掏出,數據現實上遭到了損壞。
綜上,假如我們看到一個字段的字符集是latin1的,那末,他保留的能夠是任何編碼的字符串;而一個字段的字符集是utf8或許gbk的,那末他保留的就應當是utf8或gbk的——除非數據庫的應用者用錯了。】
我沒有深刻進修過utf8、gbk編碼的細節,很可能說的禁絕確,只曉得簡略的ASCII編碼(-_-),然則可以懂得個全局情形。從下面來看,latin1的單字節編碼方法很有效,其他的編碼可以轉換為它再轉歸去而不至於喪失內容。所謂單字節編碼就是挨著一個個來,我懂得是,好比聖誕節到了,你要送妹子一箱蘋果,為制作浪漫,商鋪供給兩種包裝方法,一是按個數來,即單個蘋果包裝進一個盒子,來一個包裝一個,如許,妹子在拆完一切的盒子後完完全整的可以復原為一個個完全的和一箱無缺無損的蘋果,二是按分量來,每一個盒子限重2兩、3兩、6兩,如許在包裝時,若恰好重3兩確當然可以完全的放進一個盒子,然則若不敷或許多了,勉不了要切開蘋果,或許再往盒子中添加其他的部門蘋果,如許的話,妹子再不管如何拆開盒子,都邑獲得一箱殘破不勝的蘋果了,由於你在依照這類包裝方法停止時,曾經損壞了單個蘋果的完全性,如今復原不回來了~我們的字符集編碼轉換就是在做這類從新包裝的任務,latin1正好就像單個蘋果包裝,而utf8就像第二種方法。
而適才說的完整婚配的情形是,你去買一箱蘋果,箱子裡邊的一切蘋果分量曾經正好要末是2兩,要末是3兩或6兩的,如許再按分量包裝時固然就正好分派了,獲得的依然是完全的蘋果。
所以說白了,兩種可行的方法是:
1. 一切變量均設置成latin1(set names latin1;),如許,即使我們所應用的編纂客戶端編碼多樣(gbk或utf8),終究可以獲得准確成果;
2. 一切的設置成gbk或許gb2312(國標編碼,只用於簡體中文),采取完整婚配;
3. 針對中央的轉換進程,好比gbk輸出,將character_set_client、character_set_connection視為latin1,character_set_database設為gb2312,建表時定字符集為gb2312,character_set_results也能夠定為gb2312,固然這只是雞肋,實質上照樣用了latin1,gbk轉latin1再轉gb2312時只實用於簡體。
最初,關於字符集校訂規矩,只懂得一點。在我們設置mysql字符集時,mysql會主動給一個對應的校訂規矩,好比設置charset為utf8,默許的collation就是utf8_general_ci,gb2312字符集對應gb2312_chinese_ci,mysql敕令檢查一切校訂規矩是show collation,檢查某一對應字符集的校訂規就是show collation like 'utf8%'了。
字符集校訂是一種對應用以後字符集時采取的排序、比較方法,即使統一種字符集,在分歧的地域也是分歧的比較方法,所以才有校訂這麼一說,好比utf8_general_ci,這個ci就是case insensitive,即年夜小寫不敏感,采取它校訂時,查詢某字段值婚配時,年夜小寫的記載都邑湧現,固然還有其他的規矩,utf8打印出來一年夜坨,不細研討了~