數據庫對象sysbench裝置教程和機能測試例子。本站提示廣大學習愛好者:(數據庫對象sysbench裝置教程和機能測試例子)文章只能為提供參考,不一定能成為您想要的結果。以下是數據庫對象sysbench裝置教程和機能測試例子正文
在數據剖析范疇,最熱點的莫過於Python和R說話,此前有一篇文章《別老扯甚麼Hadoop了,你的數據基本不敷年夜》指出:只要在跨越5TB數據量的范圍下,Hadoop才是一個公道的技巧選擇。此次拿到近億條日記數據,萬萬級數據曾經是關系型數據庫的查詢剖析瓶頸,之前應用過Hadoop對年夜量文本停止分類,此次決議采取Python來處置數據:
硬件情況
CPU:3.5 GHz Intel Core i7
內存:32 GB HDDR 3 1600 MHz
硬盤:3 TB Fusion Drive
數據剖析對象
Python:2.7.6
Pandas:0.15.0
IPython notebook:2.0.0
源數據以下表所示:

數據讀取
啟動IPython notebook,加載pylab情況:
ipython notebook --pylab=inline
Pandas供給了IO對象可以將年夜文件分塊讀取,測試了一下機能,完全加載9800萬條數據也只須要263秒閣下,照樣相當不錯了。
import pandas as pd
reader = pd.read_csv('data/servicelogs', iterator=True)
try:
df = reader.get_chunk(100000000)
except StopIteration:
print "Iteration is stopped."

應用分歧分塊年夜小來讀取再挪用 pandas.concat 銜接DataFrame,chunkSize設置在1000萬條閣下速度優化比擬顯著。
loop = True
chunkSize = 100000
chunks = []
while loop:
try:
chunk = reader.get_chunk(chunkSize)
chunks.append(chunk)
except StopIteration:
loop = False
print "Iteration is stopped."
df = pd.concat(chunks, ignore_index=True)
上面是統計數據,Read Time是數據讀取時光,Total Time是讀取和Pandas停止concat操作的時光,依據數據總量來看,對5~50個DataFrame對象停止歸並,機能表示比擬好。

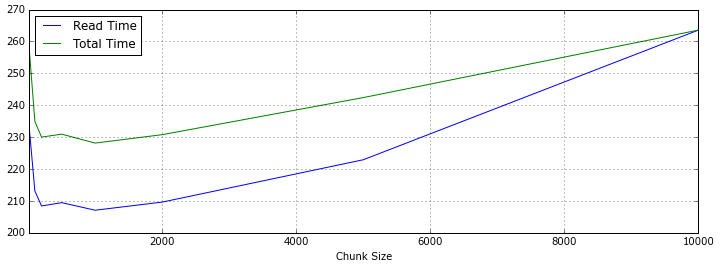
假如應用Spark供給的Python Shell,異樣編寫Pandas加載數據,時光會短25秒閣下,看來Spark對Python的內存應用都有優化。
數據清洗
Pandas供給了 DataFrame.describe 辦法檢查數據摘要,包含數據檢查(默許共輸入首尾60行數據)和行列統計。因為源數據平日包括一些空值乃至空列,會影響數據剖析的時光和效力,在預覽了數據摘要後,須要對這些有效數據停止處置。
起首挪用 DataFrame.isnull() 辦法檢查數據表中哪些為空值,與它相反的辦法是 DataFrame.notnull() ,Pandas會將表中一切數據停止null盤算,以True/False作為成果停止填充,以下圖所示:

Pandas的非空盤算速度很快,9800萬數據也只須要28.7秒。獲得初步信息以後,可以對表中空列停止移除操作。測驗考試了按列名順次盤算獲得非空列,和 DataFrame.dropna() 兩種方法,時光分離為367.0秒和345.3秒,但檢討時發明 dropna() 以後一切的行都沒有了,查了Pandas手冊,本來不加參數的情形下, dropna() 會移除一切包括空值的行。假如只想移除全體為空值的列,須要加上 axis 和 how 兩個參數:
df.dropna(axis=1, how='all')
共移除14列中的6列,時光也只消費了85.9秒。
接上去是處置殘剩行中的空值,經由測試,在 DataFrame.replace() 中應用空字符串,要比默許的空值NaN節儉一些空間;但對全部CSV文件來講,空列只是多存了一個“,”,所以移除的9800萬 x 6列也只省下了200M的空間。進一步的數據清洗照樣在移除無用數據和歸並上。
對數據列的拋棄,除有效值和需求劃定以外,一些表本身的冗余列也須要在這個環節清算,好比說表中的流水號是某兩個字段拼接、類型描寫等,經由過程對這些數據的拋棄,新的數據文件年夜小為4.73GB,足足削減了4.04G!
數據處置
應用 DataFrame.dtypes 可以檢查每列的數據類型,Pandas默許可以讀出int和float64,其它的都處置為object,須要轉換格局的普通為日期時光。DataFrame.astype() 辦法可對全部DataFrame或某一列停止數據格局轉換,支撐Python和NumPy的數據類型。
df['Name'] = df['Name'].astype(np.datetime64)
對數據聚合,我測試了 DataFrame.groupby 和 DataFrame.pivot_table 和 pandas.merge ,groupby 9800萬行 x 3列的時光為99秒,銜接表為26秒,生成透視表的速度更快,僅需5秒。
df.groupby(['NO','TIME','SVID']).count() # 分組
fullData = pd.merge(df, trancodeData)[['NO','SVID','TIME','CLASS','TYPE']] # 銜接
actions = fullData.pivot_table('SVID', columns='TYPE', aggfunc='count') # 透視表
依據透視表生成的生意業務/查詢比例餅圖:

將日記時光參加透視表並輸入天天的生意業務/查詢比例圖:
total_actions = fullData.pivot_table('SVID', index='TIME', columns='TYPE', aggfunc='count')
total_actions.plot(subplots=False, figsize=(18,6), kind='area')
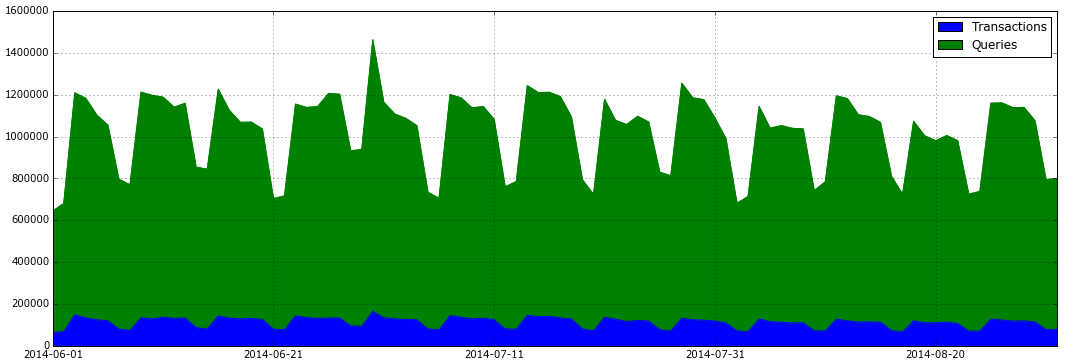
除此以外,Pandas供給的DataFrame查詢統計功效速度表示也異常優良,7秒之內便可以查詢生成一切類型為生意業務的數據子表:
tranData = fullData[fullData['Type'] == 'Transaction']
該子表的年夜小為 [10250666 rows x 5 columns]。在此曾經完成了數據處置的一些根本場景。試驗成果足以解釋,在非“>5TB”數據的情形下,Python的表示曾經能讓善於應用統計剖析說話的數據剖析師熟能生巧。