mysql數據庫敷衍年夜流量網站的的3種架構擴大方法引見。本站提示廣大學習愛好者:(mysql數據庫敷衍年夜流量網站的的3種架構擴大方法引見)文章只能為提供參考,不一定能成為您想要的結果。以下是mysql數據庫敷衍年夜流量網站的的3種架構擴大方法引見正文
數據庫擴大年夜概分為以下幾個步調:
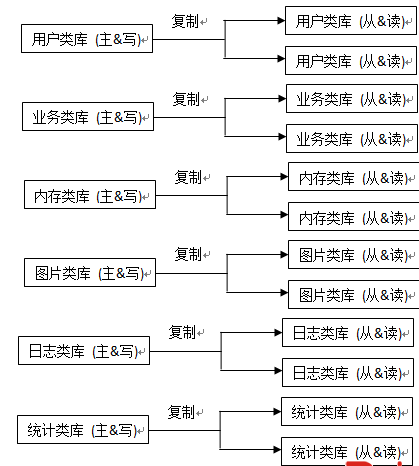
1、讀寫分別:當數據庫拜訪量還不是很年夜的時刻,我們可以恰當增長辦事器,數據庫主從復制的方法將讀寫分別;
2、垂直分區:當寫入操作一旦增長的時刻,那末主從數據庫將花更多的時光的放在數據同步上,這個時刻辦事器也是不勝重負的;那末就有了數據的垂直分區,數據的垂直分區思緒是將寫入操作比擬頻仍的數據表,如用戶表_user,或許定單表_orders,那末我們便可以把這個兩個表分別出來,放在分歧的辦事器,假如這兩個表和其他表存在聯表查詢,那末就只能把本來的sql語句給拆分了,先查詢一個表,在查詢另外一個,固然說這個會消費更過機能,但比起那種年夜量數據同步,累贅照樣加重了很多;
3、程度分區:然則常常工作不盡人意,能夠采用垂直分區能撐一段時光,因為網站太火了,拜訪量又逐日100w,一會兒蹦到了1000w,這個時刻可以采用數據的停止分別,我們可以依據user的Id分歧停止分派,如采用%2的情勢,或許%10的情勢,固然這類情勢對今後的擴大有了很年夜的限制,當我由10個分區增長到20個的時刻,一切的數據都得從新分區,那末將是一個的很宏大的盤算量;以下供給幾種罕見的算法:
哈希算法:就是采取user_id%的方法;
規模:可以依據user_id字符值規模分區,如1-1000為一區,1001-2000則是另外一個區等;
映照關系:就是將user_id存在的所對應的分區放在數據庫中保留,當用戶操作時先去查詢地點分區,再停止操作;
關於以上幾種擴大方法,讀寫分別重要是操作上的擴大,垂直分區重要是對寫入較頻仍數據表的分別,程度分區重要是數據分別;