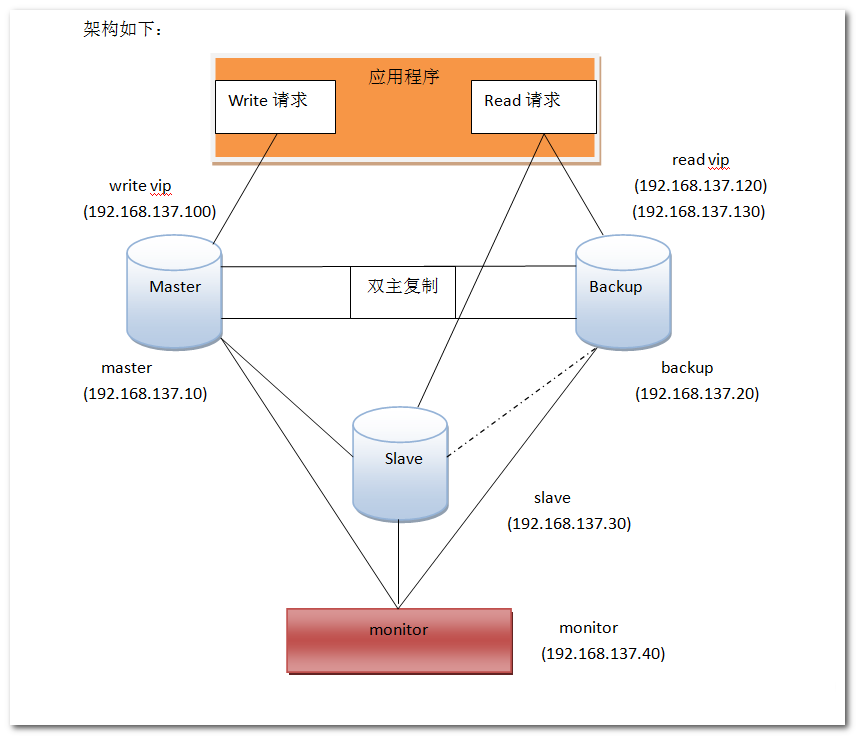
step by step設置裝備擺設mysql復制的詳細辦法。本站提示廣大學習愛好者:(step by step設置裝備擺設mysql復制的詳細辦法)文章只能為提供參考,不一定能成為您想要的結果。以下是step by step設置裝備擺設mysql復制的詳細辦法正文
表分區是比來才曉得的哦 ,之前本身做都是分表來完成上億級其余數據了,上面我來給年夜家引見一下mysql表分區創立與應用吧,願望對列位同窗會有所贊助。
表分區的測試應用,重要內容來自於其他博客文章和mysql5.1的參考手冊
mysql測試版本:mysql5.5.28
mysql物理存儲文件(有mysql設置裝備擺設的datadir決議存儲途徑)格局簡介
數據庫engine為MYISAM
frm表構造文件,myd表數據文件,myi表索引文件。
INNODB engine對應的表物理存儲文件
innodb的數據庫的物理文件構造為:
.frm文件
.ibd文件和.ibdata文件:
這兩種文件都是寄存innodb數據的文件,之所以用兩種文件來寄存innodb的數據,是由於innodb的數據存儲方法可以或許經由過程設置裝備擺設來決議是應用同享表空間寄存存儲數據,照樣用獨享表空間寄存存儲數據。
獨享表空間存儲方法應用.ibd文件,而且每一個表一個ibd文件
同享表空間存儲方法應用.ibdata文件,一切表配合應用一個ibdata文件
創立分區
分區的一些長處包含:
· 與單個磁盤或文件體系分區比擬,可以存儲更多的數據。
· 關於那些曾經掉去保留意義的數據,平日可以經由過程刪除與那些數據相關的分區,很輕易地刪除那些數據。相反地,在某些情形下,添加新數據的進程又可以經由過程為那些新數據專門增長一個新的分區,來很便利地完成。
平日和分區有關的其他長處包含上面列出的這些。MySQL 分區中的這些功效今朝還沒有完成,然則在我們的優先級列表中,具有高的優先級;我們願望在5.1的臨盆版本中,能包含這些功效。
· 一些查詢可以獲得極年夜的優化,這重要是借助於知足一個給定WHERE 語句的數據可以只保留在一個或多個分區內,如許在查找時就不消查找其他殘剩的分區。由於分區可以在創立了分區表落後行修正,所以在第一次設置裝備擺設分區計劃時還不曾這麼做時,可以從新組織數據,來進步那些經常使用查詢的效力。
· 觸及到例如SUM() 和 COUNT()如許聚合函數的查詢,可以很輕易地停止並行處置。這類查詢的一個簡略例子如 “SELECT salesperson_id, COUNT(orders) as order_total FROM sales GROUP BY salesperson_id;”。經由過程“並行”, 這意味著該查詢可以在每一個分區上同時停止,終究成果只需經由過程總計一切分區獲得的成果。
· 經由過程跨多個磁盤來疏散數據查詢,來取得更年夜的查詢吞吐量。
簡而言之就是 數據治理優化,查詢更快,數據查詢並行
檢測mysql能否支撐分區
mysql> show variables like
"%partition%";
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| have_partitioning | YES |
+-------------------+-------+
1 row in set
RANGE 分區:基於屬於一個給定持續區間的列值,把多行分派給分區。
DROP TABLE IF EXISTS `p_range`;
CREATE TABLE `p_range` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`name` char(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=9 DEFAULT CHARSET=utf8
/*!50100 PARTITION BY RANGE (id)
(PARTITION p0 VALUES LESS THAN (8) ENGINE = MyISAM) */;
range分區就是 partition by range(id) 表現按id 1-7的數據存儲在p0分區;假如id年夜於7了則數據不克不及寫入了,由於沒有對應的數據分區來存儲;
所以這時候在創立分區時須要應用maxvalues症結字了
PARTITION BY RANGE (id)
(
PARTITION p0 VALUES LESS THAN (8),
PARTITION p1 VALUES LESS THAN MAXVALUE)
如許就表現,一切id年夜於7的數據記載存在在p1分區裡。
RANGE分區在以下場所特殊有效:
· 當須要刪除“舊的”數據時。假如你應用下面比來的誰人例子給出的分區計劃,你只需簡略地應用 “ALTER TABLE employees DROP PARTITION p0;”來刪除一切在1991年前就曾經停滯任務的雇員絕對應的一切行。關於有年夜量行的表,這比運轉一個如“DELETE FROM employees WHERE YEAR(separated) <= 1990;”如許的一個DELETE查詢要有用很多。
· 想要應用一個包括有日期或時光值,或包括有從一些其他級數開端增加的值的列。
· 常常運轉直接依附於用於朋分表的列的查詢。例如,當履行一個如“SELECT COUNT(*) FROM employees WHERE YEAR(separated) = 2000 GROUP BY store_id;”如許的查詢時,MySQL可以很敏捷地肯定只要分區p2須要掃描,這是由於余下的分區弗成能包括有相符該WHERE子句的任何記載。
LIST 分區:相似於按RANGE分區,差別在於LIST分區是基於列值婚配一個團圓值聚集中的某個值來停止選擇。
list分區可以懂得為按一個鍵的id區間停止數據存儲,好比類型表 1,2,3,4的一切記載存儲在p0外面,5,6,7,8存在在p1分區外面
這裡與range分區一樣,假如如今有筆記錄typeid是9,那末這筆記錄是不克不及存入的;
須要留意的是:LIST分區沒有相似如“VALUES LESS THAN MAXVALUE”如許的包括其他值在內的界說。將要婚配的任何值都必需在值列表中找到。
DROP TABLE IF EXISTS `p_list`;
CREATE TABLE `p_list` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`typeid` mediumint(10) NOT NULL DEFAULT '0',
`typename` char(20) DEFAULT NULL,
PRIMARY KEY (`id`,`typeid`)
) ENGINE=MyISAM AUTO_INCREMENT=9 DEFAULT CHARSET=utf8
/*!50100 PARTITION BY LIST (typeid)
(PARTITION p0 VALUES IN (1,2,3,4) ENGINE = MyISAM,
PARTITION p1 VALUES IN (5,6,7,8) ENGINE = MyISAM) */;
HASH分區:基於用戶界說的表達式的前往值來停止選擇的分區,該表達式應用將要拔出到表中的這些行的列值停止盤算。這個函數可以包括MySQL 中有用的、發生非負整數值的任何表達式。
HASH分區重要用來確保數據在事後肯定數量的分區中均勻散布。在RANGE和LIST分區中,必需明白指定一個給定的列值或列值聚集應當保留在哪一個分區中;而在HASH分區中,MySQL 主動完成這些任務,你所要做的只是基於將要被哈希的列值指定一個列值或表達式,和指定被分區的表將要被朋分成的分區數目。
要應用HASH分區來朋分一個表,要在CREATE TABLE 語句上添加一個“PARTITION BY HASH (expr)”子句,個中“expr”是一個前往一個整數的表達式。它可以僅僅是字段類型為MySQL 整型的一列的名字。另外,你極可能須要在前面再添加一個“PARTITIONS num”子句,個中num 是一個非負的整數,它表現表將要被朋分成份區的數目。假如沒有包含一個PARTITIONS子句,那末分區的數目將默許為1。
DROP TABLE IF EXISTS `p_hash`;
CREATE TABLE `p_hash` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`storeid` mediumint(10) NOT NULL DEFAULT '0',
`storename` char(255) DEFAULT NULL,
PRIMARY KEY (`id`,`storeid`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8
/*!50100 PARTITION BY HASH (storeid)
PARTITIONS 4 */;
InnoDB引擎
簡略點說就是數據的存入可以按 partition by hash(expr); 這裡的expr可所以鍵名也能夠是表達式好比YEAR(time),假如是表達式的情形下
“然則應該記住,每當拔出或更新(或許能夠刪除)一行,這個表達式都要盤算一次;這意味著異常龐雜的表達式能夠會惹起機能成績,特別是在履行同時影響年夜量行的運算(例如批量拔出)的時刻。 ”
在履行刪除、寫入、更新時這個表達式都邑盤算一次。
數據的散布采取基於用戶函數成果的模數來肯定應用哪一個編號的分區。換句話,關於一個表達式“expr”,將要保留記載的分區編號為N ,個中“N = MOD(expr, num)”。
好比下面的storeid 為10;那末 N=MOD(10,4) ;N是等於2的,那末這筆記錄就存儲在p2的分區外面。
假如拔出一個表達式列值為'2005-09-15′的記載到表中,那末保留該筆記錄的分區肯定以下:MOD(YEAR('2005-09-01′),4) = MOD(2005,4) = 1 ;就存儲在p1分區外面了。
“MySQL 5.1 還支撐一個被稱為“linear hashing(線性哈希功效)”的變量,它應用一個加倍龐雜的算法來肯定新行拔出到曾經分區了的表中的地位。
線性哈希分區和慣例哈希分區在語法上的獨一差別在於,在“PARTITION BY” 子句中添加“LINEAR”症結字;線性哈希功效應用的一個線性的2的冪(powers-of-two)運算軌則
依照線性哈希分區的長處在於增長、刪除、歸並和拆分分區將變得加倍快捷,有益於處置含有極端年夜量(1000GB)數據的表。
它的缺陷在於,與應用慣例HASH分區獲得的數據散布比擬,各個分區間數據的散布不年夜能夠平衡。”
KEY 分區:相似於按HASH分區,差別在於KEY分區只支撐盤算一列或多列,且MySQL 辦事器供給其本身的哈希函數。必需有一列或多列包括整數值。
DROP TABLE IF EXISTS `p_key`;
CREATE TABLE `p_key` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`keyname` char(20) DEFAULT NULL,
`keyval` varchar(1000) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=12 DEFAULT CHARSET=utf8
/*!50100 PARTITION BY KEY (id)
PARTITIONS 4 */;
依照KEY停止分區相似於依照HASH分區,除HASH分區應用的用戶界說的表達式,而KEY分區的 哈希函數是由MySQL 辦事器供給。MySQL 簇(Cluster)應用函數MD5()來完成KEY分區;關於應用其他存儲引擎的表,辦事器應用其本身外部的 哈希函數,這些函數是基於與PASSWORD()一樣的運算軌則。
“CREATE TABLE … PARTITION BY KEY”的語律例則相似於創立一個經由過程HASH分區的表的規矩。它們獨一的差別在於應用的症結字是KEY而不是HASH,而且KEY分區只采取一個或多個列名的一個列表。
與hash的差別就是,hash應用用戶界說的表達式如YEAR(time) ;而key分區則是由mysql辦事器供給的。異樣KEY也是可使用linear線性key的,與hash linear是雷同的算法。
子分區:是分區表中每一個分區的再次朋分。
DROP TABLE IF EXISTS `p_subpartition`;
CREATE TABLE `p_subpartition` (
`id` int(10) DEFAULT NULL,
`title` char(255) NOT NULL,
`createtime` date NOT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8
/*!50100
PARTITION BY RANGE (YEAR(createtime))
SUBPARTITION BY HASH (MONTH(createtime))
(PARTITION p0 VALUES LESS THAN (2012)
(SUBPARTITION s1 ENGINE = MyISAM,
SUBPARTITION s2 ENGINE = MyISAM),
PARTITION p1 VALUES LESS THAN (2013)
(SUBPARTITION s3 ENGINE = MyISAM,
SUBPARTITION s4 ENGINE = MyISAM),
PARTITION p2 VALUES LESS THAN MAXVALUE
(SUBPARTITION s5 ENGINE = MyISAM,
SUBPARTITION s6 ENGINE = MyISAM)) */;
可以看到p_subpartition有三個分區p0,p1,p2;而這三個分區每個又進一步分為2個分區。那末全部表都就分為6個小分區;
可以看到代表p_sobpartitionp0.myd的文件消逝了,代替的是p_subpartition#p#p0#sp#s1.myd
在MySQL 5.1中,關於曾經經由過程RANGE或LIST分區了的表再停止子分區是能夠的。
子分區是分區表中每一個分區的再次朋分,子分區既可使用HASH希分區,也能夠應用KEY分區。這 也被稱為復合分區(composite partitioning)。
1,假如一個分區中創立了子分區,其他分區也要有子分區
2,假如創立了了分區,每一個分區中的子分區數必有雷同
3,統一分區內的子分區,名字不雷同,分歧分區內的子分區名子可以雷同(5.1.50不實用)
分區留意點
1、從新分區時,假如原分區外面存在maxvalue則新的分區外面也必需包括maxvalue不然就毛病。
alter table p_range2x
reorganize partition p1,p2
into (partition p0 values less than (5), partition p1 values less than maxvalue);
[Err] 1520 – Reorganize of range partitions cannot change total ranges except for last partition where it can extend the range
2、分區刪除時,數據也異樣會被刪除
alter table p_range drop partition p0;
3、假如range分區列內外面沒有maxvalue則若有新數據年夜於如今分區range數據值那末這個數據是沒法寫入到數據庫表的。
4、修正表名不須要 刪除分區後在停止更改,修正表名後分區存儲myd myi對應也會主動更改。
假如願望從一切分區刪除一切的數據,然則又保存表的界說和表的分區形式,應用TRUNCATE TABLE敕令。(請拜見13.2.9節,“TRUNCATE語法”)。
假如願望轉變表的分區而又不喪失數據,應用“ALTER TABLE … REORGANIZE PARTITION”語句。拜見上面的內容,或許在13.1.2節,“ALTER TABLE語法” 中參考關於REORGANIZE PARTITION的信息。
5、對表停止分區時,豈論采取哪一種分區方法假如表中存在主鍵那末主鍵必需在分區列中。表分區的局限性。
6、list方法分區沒有相似於range那種 less than maxvalue的寫法,也就是說list分區表的一切數據都必需在分區字段的值列表聚集中。
7、在MySQL 5.1版中,統一個分區表的一切分區必需應用統一個存儲引擎;例如,不克不及對一個分區應用MyISAM,而對另外一個應用InnoDB。
8、分區的名字是不辨別年夜小寫的,myp1與MYp1是雷同的。
分區的治理
range與list分區的轉變舉措不克不及實用於hash與key方法的分區。刪除與添加舉措是都能應用的。
以上面的例子
DROP TABLE IF EXISTS `p_list`;
CREATE TABLE `p_list` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`typeid` mediumint(10) NOT NULL DEFAULT '0',
`typename` char(20) DEFAULT NULL,
PRIMARY KEY (`id`,`typeid`)
) ENGINE=MyISAM AUTO_INCREMENT=9 DEFAULT CHARSET=utf8
/*!50100 PARTITION BY LIST (typeid)
(PARTITION p0 VALUES IN (1,2,3,4) ENGINE = MyISAM,
PARTITION p1 VALUES IN (5,6,7,8) ENGINE = MyISAM) */;
range與list分區的治理
刪除分區
ALTER TABLE tr DROP PARTITION p1;
須要留意的是刪除分區後,該分區的一切數據都沒有了。同時刪除後存在一個嚴重影響也就是typeid為5,6,7,8的記載是不克不及寫入到該表了的!
清空數據
假如想要保存表構造與分區構造可使用 TRUNCATE TABLE 清空表
更改分區保存數據
ALTER TABLE tbl_name REORGANIZE PARTITION partition_list INTO (partition_definitions);假如想保存數據停止分區的更改
ALTER TABLE p_list REORGANIZE PARTITION p0 INTO (
PARTITION s0 VALUES IN(1,2),
PARTITION s1 VALUES IN(3,4),
);如許就可以停止分區的歸並了,那怎樣停止拆分呢
ALTER TABLE p_list REORGANIZE PARTITION s0,s1 INTO (
PARTITION p0 VALUES IN(1,2,3,4),
); 應用 REORGANIZE PARTITION停止數據的歸並與拆分,數據是沒有喪失的。
在應用REORGANIZE停止從新分區時,須要留意幾點:
1、用來肯定新分區形式的PARTITION子句應用與用在CREATE TABLE中肯定分區形式的PARTITION子句雷同的規矩。(partition 分區子句必需與創立原分區時的規矩雷同)
2、partition_definitions 列表平分區的合集應當與在partition_list 中定名分區的合集占領雷同的區間或值聚集。 (不論是歸並照樣拆分,s0,s1到p0;p0到s0,s1 外面的區間或許值都必需雷同)
3、關於依照RANGE分區的表,只能從新組織相鄰的分區;不克不及跳過RANGE分區。(好比按range年份 p0 1990,p1 2000 ,p2 2013三個分區;在歸並時partition p0,p2 into()
如許是不可的,由於這兩個分區不是相鄰的分區;)
4、不克不及應用REORGANIZE PARTITION來轉變表的分區類型;也就是說,例如,不克不及把RANGE分區變成HASH分區,反之亦然。也不克不及應用該敕令來轉變分區表達式或列。
增長分區
ALTER TABLE p_list ADD PARTITION (PARTITION p2 VALUES IN (9, 10, 11));
然則不克不及應用
ALTER TABLE p_list ADD PARTITION (PARTITION p2 VALUES IN (9, 14));
如許mysql 會發生毛病1465 (HY000): 在LIST分區中,統一個常數的屢次界說
hash與key分區的治理在轉變分區設置方面,依照HASH分區或KEY分區的表彼此異常類似,然則它們又與依照RANGE或LIST分區的表在許多方面有差異。
關於添加和刪除依照RANGE或LIST停止分區的表的分區
不克不及應用與從依照RANGE或LIST分區的表中刪除分區雷同的方法,來從HASH或KEY分區的表中刪除分區。然則,可使用“ALTER TABLE ... COALESCE PARTITION”敕令來歸並HASH或KEY分區。
檢查源代碼打印贊助1 DROP TABLE IF EXISTS `p_hash`; 2 3 CREATE TABLE `p_hash` ( 4 `id` int(10) NOT NULL AUTO_INCREMENT, 5 `storeid` mediumint(10) NOT NULL DEFAULT '0', 6 `storename` char(255) DEFAULT NULL, 7 PRIMARY KEY (`id`,`storeid`) 8 ) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8 9 /*!50100 PARTITION BY HASH (storeid) 10 PARTITIONS 4 */;
如p_hash的分區數為4個;
要削減分區數為2個
ALTER TABLE p_hash COALESCE PARTITION 2;
關於依照HASH,KEY,LINEAR HASH,或LINEAR KEY分區的表, COALESCE能起到異樣的感化。COALESCE不克不及用來增長分區的數目,假如你測驗考試這麼做,成果會湧現相似於上面的毛病:
mysql> ALTER TABLE clients COALESCE PARTITION 18;
毛病1478 (HY000): 不克不及挪動一切分區,應用DROP TABLE取代要增長顧客表的分區數目從12到18,應用“ALTER TABLE … ADD PARTITION”,詳細以下:
ALTER TABLE clients ADD PARTITION PARTITIONS 18;正文:“ALTER TABLE … REORGANIZE PARTITION”不克不及用於依照HASH或HASH分區的表。
分區保護
重建分區
這和先刪除保留在分區中的一切記載,然後從新拔出它們,具有異樣的後果。它可用於整頓分區碎片。
ALTER TABLE t1 REBUILD PARTITION (p0, p1);
優化分區假如從分區中刪除年夜量的行,或許對一個帶有可變長度的行(也就是說,有VARCHAR,BLOB,或TEXT類型的列)作了很多修正,
可使用“ALTER TABLE … OPTIMIZE PARTITION”來發出沒有應用的空間,並整頓分區數據文件的碎片。
ALTER TABLE t1 OPTIMIZE PARTITION (p0, p1);
剖析分區
讀取並保留分區的鍵散布
ALTER TABLE t1 ANALYZE PARTITION (p3);
修補分區: 修補被損壞的分區。
ALTER TABLE t1 REPAIR PARTITION (p0,p1);
檢討分區
可使用簡直與對非分區表應用CHECK TABLE 雷同的方法檢討分區。
ALTER TABLE trb3 CHECK PARTITION (p1);
這個敕令可以告知你表t1的分區p1中的數據或索引能否曾經被損壞。假如產生了這類情形,應用“ALTER TABLE ... REPAIR PARTITION”來修補該分區。獲得分區信息
在mysql辦事器信息數據庫外面的partitions寄存著辦事器一切表的分區信息。
explain partitions敕令
explain partitions select * from p_hash
+----+-------------+--------+-------------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | p_hash | p0,p1,p2,p3 | ALL | NULL | NULL | NULL | NULL | 10 | |
+----+-------------+--------+-------------+------+---------------+------+---------+------+------+-------+
-- 獲得到p_list表的分區具體信息。
select * from information_schema.`PARTITIONS` where TABLE_NAME = 'p_list';
-- 分區的創立信息
show create table p_list;