mysql技能之select count的差別剖析。本站提示廣大學習愛好者:(mysql技能之select count的差別剖析)文章只能為提供參考,不一定能成為您想要的結果。以下是mysql技能之select count的差別剖析正文
1.測試情況
OS:Linux
DB:mysql-5.5.18
table:innodb存儲引擎
表界說以下:

2. 測試場景與剖析【統計表group_message的記載數量】
(1)select count(*)方法

(2)select count(1)方法

(3)select count(col_name)方法
分離應用
select count(group_id)
select count(user_id)
select count(col_null)

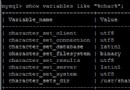
經由過程上述測試成果可以看到,select count(*)和select count(1)都應用了group_id這個最短的二級索引。能夠有人會問為啥不消更短的主鍵索引【int類型】呢,這重要是由於innodb存儲引擎下,主鍵索引本質包括了索引和數據,掃描主鍵索引現實是掃描物理記載,價值本質是最年夜的。再來看看幾種select count(col_name), count(group_id)應用了最短二級索引,由於該列就是索引列;而count(user_id)則應用了組合索引,因為user_id本質不克不及應用該索引,但掃描索引也能獲得記載數,並且比掃描物理記載價值小,這裡應當是mysql的一個優化;count(col_null)則不克不及應用索引,由於該列含有null值,所以效力最低。別的,關於含有null值的行,count(col_null)現實不會統計,這會與你想統計表記載數量的初志不符,好比測試表有852226筆記錄,但col_null列只要1行非空,則統計成果以下:

3.測試結論
mysql中,須要經由過程selct count 統計表記載數量時,應用count(*)或count(1)就好。