MySQL分表完成上百萬上萬萬記載散布存儲的批量查詢設計形式詳解。本站提示廣大學習愛好者:(MySQL分表完成上百萬上萬萬記載散布存儲的批量查詢設計形式詳解)文章只能為提供參考,不一定能成為您想要的結果。以下是MySQL分表完成上百萬上萬萬記載散布存儲的批量查詢設計形式詳解正文
我們曉得可以將一個海量記載的 MySQL 年夜表依據主鍵、時光字段,前提字段等分紅若干個表乃至保留在若干辦事器中。
獨一的成績就是跨辦事器批量查詢費事,只能經由過程運用法式來處理。談談在Java中的處理思緒。其他說話道理相似。
這裡說的分表不是 MySQL 5.1 的 partition,而是工資把一個表離開存在若干表或分歧的辦事器。
1. 運用法式級別完成
見教意圖
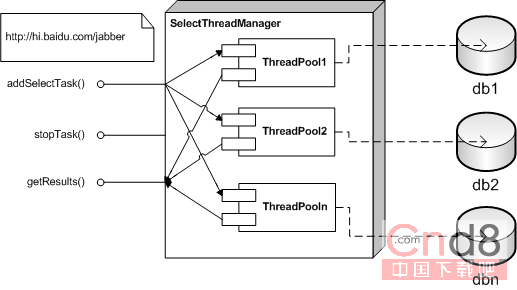
electThreadManager 分表數據查詢治理器
它為分表的每一個database or server 樹立一個 thread pool
addTask() - 添加義務
stopTask() - 停滯義務
getResult() - 獲得履行成果
最快的履行時光 = 最慢的 MySQL 節點查詢消費時光
最慢的履行時光 = 超不時間
某個 ThreadPool 忙時刻處置流程
1. 假設 ThreadPoolN 異常忙,(也意味 DB N 異常忙);
2. 新的查詢義務到來,addTask(), 新的義務的一個thread加到ThreadPoolN義務列隊中
3. 外層運用曾經取得其他 thread 前往成果,持續期待
4. 外層運用期待超時的時光到,挪用 stopTask() 設置該義務全體 thread 中的停滯標記, 外層運用前往。
5. 若干時光後,ThreadPoolN取到該列隊 Thread, 由於設置了停滯位,線程直接運轉完成。
2. JDBC 層完成
做一個 JDBC Driver 的包裝,攔阻 PreparedStatement, Statement 的 executeQuery()
然後挪用 SelectThreadManager 完成
3. MySQL partition
MySQL 5.1 的 partition 功效因為單張表的數據跨文件,批量查詢時刻異樣存在上述成績,不外它是在 MySQL 外部完成的,不須要內部挪用者關懷。其查詢完成的道理應當年夜致相似。
但 partition 只處理了 IO 的瓶頸,其實不能處理 CPU 盤算的瓶頸,是以沒法取代傳統的手工分表方法。