基於sql語句的一些經常使用語法積聚總結。本站提示廣大學習愛好者:(基於sql語句的一些經常使用語法積聚總結)文章只能為提供參考,不一定能成為您想要的結果。以下是基於sql語句的一些經常使用語法積聚總結正文
1.當某一字段的值願望經由過程其它字值顯示出來時(記載轉換),可經由過程上面的語句完成:
case Type when '1' then '通俗通道' when '2' then '高端通道' end as Type
個中“Type"是字段名,”1“,”2“是字段值
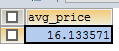
2.前往數據庫頂用戶表的表單名:
select name from table where type = 'u' and status >=2
3.按拼音首字母排序:
select * from table order by 列名 Collate Chinese_PRC_CS_AS_KS_WS
起首,在這裡的collate是一個子句,重要是界說排序規矩,可運用於數據庫界說或列界說;或運用於字符串表達式以運用排序規矩投影。
語法是collate collation_name。參數collate_name是運用於表達式、列界說或數據庫界說的排序規矩的稱號。
•collation_name 可以只是指定的 Windows_collation_name 或 SQL_collation_name。
1.Windows_collation_name 是 Windows 排序規矩的排序規矩稱號。拜見 Windows 排序規矩稱號。
2.SQL_collation_name 是 SQL 排序規矩的排序規矩稱號。拜見 SQL 排序規矩稱號。
注:SQL SERVER的排序規矩日常平凡應用不是許多,或許很多初學者還比擬生疏,但有 一個毛病年夜家應是常常碰著: SQL SERVER數據庫,在跨庫多表銜接查詢時,若兩數據 庫默許字符集分歧,體系就會前往如許的毛病:“沒法處理 equal to 操作的排序規矩抵觸。”
4.按姓氏筆劃排序:
Select * From table Order By CustomerName Collate Chinese_PRC_Stroke_ci_as
正文如上。
5.指定值的規模查詢:
1.stockname like ‘%[a-zA-Z]%'
2.stockname like '[^F-M]‘
個中
[]指定值的規模
^ 消除指定規模
6.對查詢成果隨機排序:
SELECT * FROM table Orders ORDER BY NEWID()
7.前往兩個表中共有的一切記載:
select tableA.a tableB.b from tableA inner join tableB as b ontableA.a= b.b
個中sql中as的用法這裡就不做熬述。
8.期待時光再履行語句:
waitfor delay '00:00:05‘
select * from studentinfowaitfor time '23:08:00
9.向一個表A中拔出記載,而且拔出的記載在A中不存在(經由過程一個字段來斷定):
insert into tableA (tracekey,muteSMS,CreateTime,traceuser,tracetime,traceSlot,traceduration)
Select 'TRACE_TIMER',0,getdate(),mobileid,getdate(),'30','0' from tableB where corpid = 10001
and not exists (select traceuser from tableA ) and mobileid like '13' and len(mobileid) = 11