MySQL索引面前的之應用戰略及優化(高機能索引戰略)。本站提示廣大學習愛好者:(MySQL索引面前的之應用戰略及優化(高機能索引戰略))文章只能為提供參考,不一定能成為您想要的結果。以下是MySQL索引面前的之應用戰略及優化(高機能索引戰略)正文
示例數據庫
為了評論辯論索引戰略,須要一個數據量不算小的數據庫作為示例。本文選用MySQL官方文檔中供給的示例數據庫之一:employees。這個數據庫關系龐雜度適中,且數據量較年夜。下圖是這個數據庫的E-R關系圖(援用自MySQL官方手冊):

圖12
MySQL官方文檔中關於此數據庫的頁面為http://dev.mysql.com/doc/employee/en/employee.html。外面具體引見了此數據庫,並供給了下載地址和導入辦法,假如有興致導入此數據庫到本身的MySQL可以參考文中內容。
最左前綴道理與相干優化
高效應用索引的重要前提是曉得甚麼樣的查詢會應用到索引,這個成績和B+Tree中的“最左前綴道理”有關,上面經由過程例子解釋最左前綴道理。
這裡先說一下結合索引的概念。在上文中,我們都是假定索引只援用了單個的列,現實上,MySQL中的索引可以以必定次序援用多個列,這類索引叫做結合索引,普通的,一個結合索引是一個有序元組,個中各個元素均為數據表的一列,現實上要嚴厲界說索引須要用到關系代數,然則這裡我不想評論辯論太多關系代數的話題,由於那樣會顯得很死板,所以這裡就不再做嚴厲界說。別的,單列索引可以算作結合索引元素數為1的特例。
以employees.titles表為例,上面先檢查其上都有哪些索引:
SHOW INDEX FROM employees.titles;
+--------+------------+----------+--------------+-------------+-----------+-------------+------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Null | Index_type |
+--------+------------+----------+--------------+-------------+-----------+-------------+------+------------+
| titles | 0 | PRIMARY | 1 | emp_no | A | NULL | | BTREE |
| titles | 0 | PRIMARY | 2 | title | A | NULL | | BTREE |
| titles | 0 | PRIMARY | 3 | from_date | A | 443308 | | BTREE |
| titles | 1 | emp_no | 1 | emp_no | A | 443308 | | BTREE |
+--------+------------+----------+--------------+-------------+-----------+-------------+------+------------+
從成果中可以到titles表的主索引為
ALTER TABLE employees.titles DROP INDEX emp_no;
如許便可以專心剖析索引PRIMARY的行動了。
情形一:全列婚配。
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND title='Senior Engineer' AND from_date='1986-06-26';
+----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
| 1 | SIMPLE | titles | const | PRIMARY | PRIMARY | 59 | const,const,const | 1 | |
+----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
很顯著,當依照索引中一切列停止准確婚配(這裡准確婚配指“=”或“IN”婚配)時,索引可以被用到。這裡有一點須要留意,實際上索引對次序是敏感的,但 是因為MySQL的查詢優化器會主動調劑where子句的前提次序以應用合適的索引,例如我們將where中的前提次序倒置:
EXPLAIN SELECT * FROM employees.titles WHERE from_date='1986-06-26' AND emp_no='10001' AND title='Senior Engineer';
+----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
| 1 | SIMPLE | titles | const | PRIMARY | PRIMARY | 59 | const,const,const | 1 | |
+----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
後果是一樣的。
情形二:最左前綴婚配。
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001';
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------+
| 1 | SIMPLE | titles | ref | PRIMARY | PRIMARY | 4 | const | 1 | |
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------+
當查詢前提准確婚配索引的右邊持續一個或幾個列時,如
情形三:查詢前提用到了索引中列的准確婚配,然則中央某個前提未供給。
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND from_date='1986-06-26';
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
| 1 | SIMPLE | titles | ref | PRIMARY | PRIMARY | 4 | const | 1 | Using where |
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
此時索引應用情形和情形二雷同,由於title未供給,所以查詢只用到了索引的第一列,爾後面的from_date固然也在索引中,然則因為 title不存在而沒法和左前綴銜接,是以須要對成果停止掃描過濾from_date(這裡因為emp_no獨一,所以不存在掃描)。假如想讓 from_date也應用索引而不是where過濾,可以增長一個幫助索引
起首我們看下title一共有幾種分歧的值:
SELECT DISTINCT(title) FROM employees.titles;
+--------------------+
| title |
+--------------------+
| Senior Engineer |
| Staff |
| Engineer |
| Senior Staff |
| Assistant Engineer |
| Technique Leader |
| Manager |
+--------------------+
只要7種。在這類成為“坑”的列值比擬少的情形下,可以斟酌用“IN”來彌補這個“坑”從而構成最左前綴:
EXPLAIN SELECT * FROM employees.titles
WHERE emp_no='10001'
AND title IN ('Senior Engineer', 'Staff', 'Engineer', 'Senior Staff', 'Assistant Engineer', 'Technique Leader', 'Manager')
AND from_date='1986-06-26';
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 59 | NULL | 7 | Using where |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
此次key_len為59,解釋索引被用全了,然則從type和rows看出IN現實上履行了一個range查詢,這裡檢討了7個key。看下兩種查詢的機能比擬:
SHOW PROFILES;
+----------+------------+-------------------------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+-------------------------------------------------------------------------------+
| 10 | 0.00058000 | SELECT * FROM employees.titles WHERE emp_no='10001' AND from_date='1986-06-26'|
| 11 | 0.00052500 | SELECT * FROM employees.titles WHERE emp_no='10001' AND title IN ... |
+----------+------------+-------------------------------------------------------------------------------+
“填坑”後機能晉升了一點。假如經由emp_no挑選後余下許多數據,則後者機能優勢會加倍顯著。固然,假如title的值許多,用填坑就不適合了,必需樹立幫助索引。
情形四:查詢前提沒有指定索引第一列。
EXPLAIN SELECT * FROM employees.titles WHERE from_date='1986-06-26';
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
| 1 | SIMPLE | titles | ALL | NULL | NULL | NULL | NULL | 443308 | Using where |
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
因為不是最左前綴,索引如許的查詢明顯用不到索引。
情形五:婚配某列的前綴字符串。
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND title LIKE 'Senior%';
view sourceprint?
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 56 | NULL | 1 | Using where |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
此時可以用到索引,然則假如通配符不是只湧現在末尾,則沒法應用索引。
情形六:規模查詢。
EXPLAIN SELECT * FROM employees.titles WHERE emp_no<'10010' and title='Senior Engineer';
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 4 | NULL | 16 | Using where |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
規模列可以用到索引(必需是最左前綴),然則規模列前面的列沒法用到索引。同時,索引最多用於一個規模列,是以假如查詢前提中有兩個規模列則沒法全用到索引。
EXPLAIN SELECT * FROM employees.titles
WHERE emp_no<'10010'
AND title='Senior Engineer'
AND from_date BETWEEN '1986-01-01' AND '1986-12-31';
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 4 | NULL | 16 | Using where |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
可以看到索引對第二個規模索引力所不及。這裡特殊要解釋MySQL一個成心思的處所,那就是僅用explain能夠沒法辨別規模索引和多值婚配,由於在type中這二者都顯示為range。同時,用了“between”其實不意味著就是規模查詢,例以下面的查詢:
EXPLAIN SELECT * FROM employees.titles
WHERE emp_no BETWEEN '10001' AND '10010'
AND title='Senior Engineer'
AND from_date BETWEEN '1986-01-01' AND '1986-12-31';
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 59 | NULL | 16 | Using where |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
看起來是用了兩個規模查詢,但感化於emp_no上的“BETWEEN”現實上相當於“IN”,也就是說emp_no現實是多值准確婚配。可以看到這個查詢用到了索引全體三個列。是以在MySQL中要謹嚴地域分多值婚配和規模婚配,不然會對MySQL的行動發生迷惑。
情形七:查詢前提中含有函數或表達式。
很不幸,假如查詢前提中含有函數或表達式,則MySQL不會為這列應用索引(固然某些在數學意義上可使用)。例如:
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND left(title, 6)='Senior';
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
| 1 | SIMPLE | titles | ref | PRIMARY | PRIMARY | 4 | const | 1 | Using where |
+----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
固然這個查詢和情形五中功效雷同,然則因為應用了函數left,則沒法為title列運用索引,而情形五頂用LIKE則可以。再如:
EXPLAIN SELECT * FROM employees.titles WHERE emp_no - 1='10000';
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
| 1 | SIMPLE | titles | ALL | NULL | NULL | NULL | NULL | 443308 | Using where |
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
明顯這個查詢等價於查詢emp_no為10001的函數,然則因為查詢前提是一個表達式,MySQL沒法為其應用索引。看來MySQL還沒有智能到主動優化常量表達式的水平,是以在寫查詢語句時盡可能防止表達式湧現在查詢中,而是先手工暗裡代數運算,轉換為無表達式的查詢語句。
索引選擇性與前綴索引
既然索引可以加速查詢速度,那末是否是只需是查詢語句須要,就建上索引?謎底能否定的。由於索引固然加速了查詢速度,但索引也是有價值的:索引文件自己要消費存儲空間,同時索引會減輕拔出、刪除和修正記載時的累贅,別的,MySQL在運轉時也要消費資本保護索引,是以索引其實不是越多越好。普通兩種情形下不建議建索引。
第一種情形是表記載比擬少,例如一兩千條乃至只要幾百筆記錄的表,沒需要建索引,讓查詢做全表掃描就行了。至於若干筆記錄才算多,這個小我有小我的意見,我小我的經歷是以2000作為分界限,記載數不跨越 2000可以斟酌不建索引,跨越2000條可以酌情斟酌索引。
另外一種不建議建索引的情形是索引的選擇性較低。所謂索引的選擇性(Selectivity),是指不反復的索引值(也叫基數,Cardinality)與表記載數(#T)的比值:
Index Selectivity = Cardinality / #T
明顯選擇性的取值規模為(0, 1],選擇性越高的索引價值越年夜,這是由B+Tree的性質決議的。例如,上文用到的employees.titles表,假如title字段常常被零丁查詢,能否須要建索引,我們看一下它的選擇性:
SELECT count(DISTINCT(title))/count(*) AS Selectivity FROM employees.titles;
+-------------+
| Selectivity |
+-------------+
| 0.0000 |
+-------------+
title的選擇性缺乏0.0001(准確值為0.00001579),所以其實沒有甚麼需要為其零丁建索引。
有一種與索引選擇性有關的索引優化戰略叫做前綴索引,就是用列的前綴取代全部列作為索引key,以後綴長度適合時,可以做到既使得前綴索引的選擇性 接近全列索引,同時由於索引key變短而削減了索引文件的年夜小和保護開支。上面以employees.employees表為例引見前綴索引的選擇和使 用。
從圖12可以看到employees表只要一個索引
EXPLAIN SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido';
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
| 1 | SIMPLE | employees | ALL | NULL | NULL | NULL | NULL | 300024 | Using where |
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
假如頻仍按名字搜刮員工,如許明顯效力很低,是以我們可以斟酌建索引。有兩種選擇,建
SELECT count(DISTINCT(first_name))/count(*) AS Selectivity FROM employees.employees;
+-------------+
| Selectivity |
+-------------+
| 0.0042 |
+-------------+
SELECT count(DISTINCT(concat(first_name, last_name)))/count(*) AS Selectivity FROM employees.employees;
+-------------+
| Selectivity |
+-------------+
| 0.9313 |
+-------------+
<first_name>明顯選擇性太低,<first_name, last_name>選擇性很好,然則first_name和last_name加起來長度為30,有無統籌長度和選擇性的方法?可以斟酌用 first_name和last_name的前幾個字符樹立索引,例如<first_name, left(last_name, 3)>,看看其選擇性:
SELECT count(DISTINCT(concat(first_name, left(last_name, 3))))/count(*) AS Selectivity FROM employees.employees;
+-------------+
| Selectivity |
+-------------+
| 0.7879 |
+-------------+
選擇性還不錯,但離0.9313照樣有點間隔,那末把last_name前綴加到4:
SELECT count(DISTINCT(concat(first_name, left(last_name, 4))))/count(*) AS Selectivity FROM employees.employees;
+-------------+
| Selectivity |
+-------------+
| 0.9007 |
+-------------+
這時候選擇性曾經很幻想了,而這個索引的長度只要18,比
ALTER TABLE employees.employees
ADD INDEX `first_name_last_name4` (first_name, last_name(4));
此時再履行一遍按名字查詢,比擬剖析一下與建索引前的成果:
SHOW PROFILES;
+----------+------------+---------------------------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+---------------------------------------------------------------------------------+
| 87 | 0.11941700 | SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido' |
| 90 | 0.00092400 | SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido' |
+----------+------------+---------------------------------------------------------------------------------+
機能的晉升是明顯的,查詢速度進步了120多倍。
前綴索引統籌索引年夜小和查詢速度,然則其缺陷是不克不及用於ORDER BY和GROUP BY操作,也不克不及用於Covering index(即當索引自己包括查詢所需全體數據時,不再拜訪數據文件自己)。
InnoDB的主鍵選擇與拔出優化
在應用InnoDB存儲引擎時,假如沒有特殊的須要,請永久應用一個與營業有關的自增字段作為主鍵。
常常看到有帖子或博客評論辯論主鍵選擇成績,有人建議應用營業有關的自增主鍵,有人認為沒有需要,完整可使用如學號或身份證號這類獨一字段作為主鍵。豈論支撐哪一種論點,年夜多半論據都是營業層面的。假如從數據庫索引優化角度看,應用InnoDB引擎而不應用自增主鍵相對是一個蹩腳的主張。
上文評論辯論過InnoDB的索引完成,InnoDB應用集合索引,數據記載自己被存於主索引(一顆B+Tree)的葉子節點上。這就請求統一個葉子節點內(年夜小為一個內存頁或磁盤頁)的各條數據記載按主鍵次序寄存,是以每當有一條新的記載拔出時,MySQL會依據其主鍵將其拔出恰當的節點和地位,假如頁面到達裝載因子(InnoDB默許為15/16),則開拓一個新的頁(節點)。
假如表應用自增主鍵,那末每次拔出新的記載,記載就會次序添加到以後索引節點的後續地位,當一頁寫滿,就會主動開拓一個新的頁。以下圖所示:
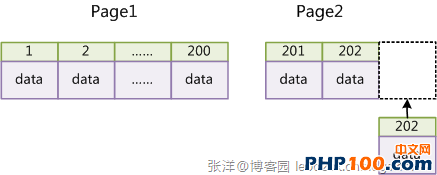
圖13
如許就會構成一個緊湊的索引構造,近似次序填滿。因為每次拔出時也不須要挪動已稀有據,是以效力很高,也不會增長許多開支在保護索引上。
假如應用非自增主鍵(假如身份證號或學號等),因為每次拔出主鍵的值近似於隨機,是以每次新記載都要被插到現有索引頁得中央某個地位:

圖14
此時MySQL不能不為了將新記載插到適合地位而挪動數據,乃至目的頁面能夠曾經被回寫到磁盤上而從緩存中清失落,此時又要從磁盤上讀回來,這增長了許多開支,同時頻仍的挪動、分頁操作形成了年夜量的碎片,獲得了不敷緊湊的索引構造,後續不能不經由過程OPTIMIZE TABLE來重建表並優化填充頁面。
是以,只需可以,請盡可能在InnoDB上采取自增字段做主鍵。