mysql 無窮級分類完成思緒。本站提示廣大學習愛好者:(mysql 無窮級分類完成思緒)文章只能為提供參考,不一定能成為您想要的結果。以下是mysql 無窮級分類完成思緒正文
第一種計劃:
應用遞歸算法,也是應用頻率最多的,年夜部門開源法式也是這麼處置,不外普通都只用到四級分類。這類算法的數據庫構造設計最為簡略。category表中一個字段id,一個字段fid(父id)。如許可以依據WHERE id = fid來斷定上一級內容,應用遞歸至最頂層。
剖析:經由過程這類數據庫設計出的無窮級,可以說讀取的時刻相當費力,所以年夜部門的法式最多3-4級分類,這就足以知足需求,從而一次性讀出一切的數據,再對獲得數組或許對象停止遞歸。自己負荷照樣沒太年夜成績。然則假如分類到更多級,那是弗成取的方法。
如許看來這類分類有個利益,就是增刪改的時刻輕松了…但是就二級分類而言,采取這類算法就應當算最優先了。
第二種計劃:
設置fid字段類型為varchar,將父類id都集中在這個字段裡,用符號離隔,好比:1,3,6
如許可以比擬輕易獲得各下級分類的ID,並且在查詢分類下的信息的時刻,
可使用:SELECT * FROM category WHERE pid LIKE “1,3%”。
剖析:比擬於遞歸算法,在讀取數據方面優勢異常年夜,然則若查找該分類的一切 父分類 或許 子分類 查詢的效力也不是很高,至多也要二次query,從某種意義看上,小我認為不太相符數據庫范式的設計。倘使遞增到無窮級,還需斟酌字段能否到達請求,並且在修正分類和轉移分類的時刻操作將異常費事。
臨時,在本身項目頂用的就是相似第二種計劃的處理方法。就該計劃在我的項目中存在如許的成績, 假如當一切數據記載到達上萬乃至10W以上後,一次性將所以分類,有序分級的實際出來,效力很低。極有能夠是項目處置數據代碼效力低帶來的。如今正在改進。
第三種計劃:
無窮級分類----改良前序遍歷樹
那末幻想中的樹型構造應具有哪些特色呢?數據存儲冗余小、直不雅性強;便利前往全部樹型構造數據;可以很輕松的前往某一子樹(便利分層加載);快整獲以某節點的祖譜途徑;拔出、刪除、挪動節點效力高級等。帶著這些需求我查找了許多材料,發明了一種幻想的樹型構造數據存儲及操作算法,改良的前序遍歷樹范型(The Nested Set Model)。
道理:
我們先把樹依照程度方法擺開。從根節點開端(“Food”),然後他的右邊寫上1。然後依照樹的次序(從上到下)給“Fruit”的右邊寫上2。如許,你沿著樹的界限走啊走(這就是“遍歷”),然後同時在每一個節點的右邊和左邊寫上數字。最初,我們回到了根節點“Food”在左邊寫上18。上面是標上了數字的樹,同時把遍歷的次序用箭頭標出來了。
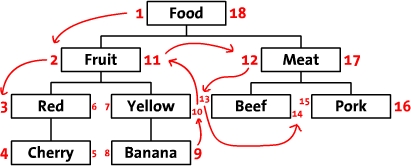
我們稱這些數字為左值和右值(如,“Food”的左值是1,右值是18)。正如你所見,這些數字按時了每一個節點之間的關系。由於“Red”有3和6兩個值,所以,它是有具有1-18值的“Food”節點的後續。異樣的,我們可以揣摸一切左值年夜於2而且右值小於11的節點,都是有2-11的“Fruit” 節點的後續。如許,樹的構造就經由過程左值和右值貯存上去了。這類數遍整棵樹算節點的辦法叫做“改良前序遍歷樹”算法。
表構造設計:
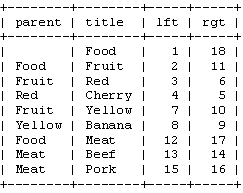
那末我們如何能力經由過程一個SQL語句把一切的分類都查詢出來呢,並且請求假如是子類的話後面要打幾個空格以表示是子分類。要想查詢出一切分類很好辦:SELECT * FROM category WHERE lft>1 AND lft<18 ORDER BY lft如許的話一切的分類都出來了,然則誰是誰的子類卻分不清,那末怎樣辦呢?我們細心看圖不難發明假如相鄰的兩筆記錄的右值第一條的右值比第二條的年夜那末就是他的父類,好比food的右值是18而fruit的右值是11 那末food是fruit的父類,然則又要斟酌到多級目次。因而有了如許的設計,我們用一個數組來存儲上一筆記錄的右值,再把它和本筆記錄的右值比擬,假如前者比後者小,解釋不是父子關系,就用array_pop彈出數組,不然就保存,以後依據數組的年夜小來打印空格。如許就處理了這個成績。代碼以下
表構造:
--
-- 表的構造 `category`
--
CREATE TABLE IF NOT EXISTS `category` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`type` int(11) NOT NULL COMMENT '1為文章類型2為產物類型3為下載類型',
`title` varchar(50) NOT NULL,
`lft` int(11) NOT NULL,
`rgt` int(11) NOT NULL,
`lorder` int(11) NOT NULL COMMENT '排序',
`create_time` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=10 ;
--
-- 導出表中的數據 `category`
--
INSERT INTO `category` (`id`, `type`, `title`, `lft`, `rgt`, `lorder`, `create_time`) VALUES
(1, 1, '頂級欄目', 1, 18, 1, 1261964806),
(2, 1, '公司簡介', 14, 17, 50, 1264586212),
(3, 1, '消息', 12, 13, 50, 1264586226),
(4, 2, '公司產物', 10, 11, 50, 1264586249),
(5, 1, '聲譽天資', 8, 9, 50, 1264586270),
(6, 3, '材料下載', 6, 7, 50, 1264586295),
(7, 1, '人才網job.vhao.net雇用', 4, 5, 50, 1264586314),
(8, 1, '留言板', 2, 3, 50, 1264586884),
(9, 1, '總裁', 15, 16, 50, 1267771951);
/**
* 顯示樹,把一切的節點都顯示出來。
* 1、先獲得根結點的閣下值(默許根節點的title為“頂級目次”)。
* 2、查詢閣下值在根節點的閣下值規模內的記載,而且依據左值排序。
* 3、假如本次記載右值年夜於上次記載的右值則為子分類,輸入時刻加空格。
* @return array
**/
function display_tree(){
//取得root右邊和左邊的值
$arr_lr = $this->category->where("title = '頂級欄目'")->find();
//print_r($arr_lr);
if($arr_lr){
$right = array();
$arr_tree = $this->category->query("SELECT id, type, title, rgt FROM category WHERE lft >= ". $arr_lr['lft'] ." AND lft <=".$arr_lr['rgt']." ORDER BY lft");
foreach($arr_tree as $v){
if(count($right)){
while ($right[count($right) -1] < $v['rgt']){
array_pop($right);
}
}
$title = $v['title'];
if(count($right)){
$title = '|-'.$title;
}
$arr_list[] = array('id' => $v['id'], 'type' => $type, 'title' => str_repeat(' ', count($right)).$title, 'name' =>$v['title']);
$right[] = $v['rgt'];
}
return $arr_list;
}
}
好了 只需如許一切的分類都可以一次性查詢出來了,而不消經由過程遞歸了。
上面的成績是如何停止拔出、刪除和修正操作
拔出:拔出操作很簡略找到其父節點,以後把左值和右值年夜於父節點左值的節點的閣下值加上2,以後再拔出本節點,閣下值分離為父節點左值加一和加二,可以用一個存儲進程來操作:
CREATE PROCEDURE `category_insert_by_parent`(IN pid INT,IN title VARCHAR(20), IN type INT, IN l_order INT, IN pubtime INT)
BEGIN
DECLARE myLeft INT;
SELECT lft into myLeft FROM category WHERE id= pid;
UPDATE qy_category SET rgt = rgt + 2 WHERE rgt > myLeft;
UPDATE qy_category SET lft = lft + 2 WHERE lft > myLeft;
INSERT INTO qy_category(type, title, lft, rgt, lorder, create_time) VALUES(type ,title, myLeft + 1, myLeft + 2, l_order, pubtime);
commit;
END
刪除操作:
刪除的道理:1.獲得要刪除節點的閣下值,並獲得他們的差再加一,@mywidth = @rgt - @lft + 1;
2.刪除閣下值在本節點之間的節點
3.修正前提為年夜於本節點右值的一切節點,操作為把他們的閣下值都減去@mywidth
存儲進程以下:
CREATE PROCEDURE `category_delete_by_key`(IN id INT)
BEGIN
SELECT @myLeft := lft, @myRight := rgt, @myWidth := rgt - lft + 1
FROM category
WHERE id = id;
DELETE FROM category WHERE lft BETWEEN @myLeft AND @myRight;
UPDATE nested_category SET rgt = rgt - @myWidth WHERE rgt > @myRight;
UPDATE nested_category SET lft = lft - @myWidth WHERE lft > @myRight;
修正:
要命的修正操作,自己看了良久也沒有看出甚麼紀律出來,只需出此下策,先刪除再拔出,只需挪用下面2個存儲進程便可以了!
總結:查詢便利,然則增刪改操作有點繁瑣,然則普通分類此類操作不是許多,照樣查詢用的多,再說弄個存儲進程也便利!
下面第三種計劃詳細講授類容是從http://home.phpchina.com/space.php?uid=45095&do=blog&id=184675拷貝過去,便利今後本身檢查。 臨時從各方面及實際上斟酌 傾向於第三計劃。不外還沒有做過測試,究竟效力怎樣樣。
等待更好的處理計劃!