mysql explain的用法(運用explain優化查詢語句)。本站提示廣大學習愛好者:(mysql explain的用法(運用explain優化查詢語句))文章只能為提供參考,不一定能成為您想要的結果。以下是mysql explain的用法(運用explain優化查詢語句)正文
首先我來給一個復雜的例子,然後再來解釋explain列的信息。
表一:catefory 文章分類表:
CREATE TABLE IF NOT EXISTS `category` ( `id` smallint(5) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(50) NOT NULL DEFAULT '', PRIMARY KEY (`id`) ) ENGINE=MyISAM INSERT INTO `test`.`category` VALUES (NULL , '分類1'); INSERT INTO `test`.`category` VALUES (NULL , '分類2'); INSERT INTO `test`.`category` VALUES (NULL , '分類3');
表二:article文章表:
CREATE TABLE IF NOT EXISTS `article` (
`aid` int(11) NOT NULL,
`cid` int(11) NOT NULL,
`content` text NOT NULL,
PRIMARY KEY (`aid`),
KEY `cid` (`cid`)
) ENGINE=MyISAM
INSERT INTO `test`.`article` (`aid`, `cid`, `content`) VALUES ('', '7', '(jb51.net)教程');
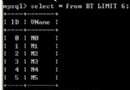
執行explain:
EXPLAIN SELECT name, content FROM category, article WHERE category.id = article.cid
失掉後果:

EXPLAIN列的解釋:
id:選定的執行方案中查詢的序列號。表示查詢中執行select子句或操作表的順序,id值越大優先級越高,越先被執行。id相反,執行順序由上至下。
select_type:查詢類型 闡明
1、SIMPLE:復雜的select查詢,不運用union及子查詢
2、PRIMARY:最外層的select查詢
3、UNION:UNION中的第二個或隨後的select查詢,不依賴於內部查詢的後果集
4、DEPENDENT UNION:UNION中的第二個或隨後的select查詢,依賴於內部查詢的後果集
5、UNION RESULT: UNION查詢的後果集SUBQUERY子查詢中的第一個select查詢,不依賴於內部查詢的後果集
6、DEPENDENT SUBQUERY:子查詢中的第一個select查詢,依賴於內部查詢的後果集DERIVED用於from子句裡有子查詢的狀況。
MySQL會遞歸執行這些子查詢,把後果放在暫時表裡。
7、UNCACHEABLE SUBQUERY:後果集不能被緩存的子查詢,必需重新為外層查詢的每一行停止評價
8、UNCACHEABLE UNION:UNION中的第二個或隨後的select查詢,屬於不可緩存的子查詢
table:顯示這一行的數據是關於哪張表的
type:這是重要的列,顯示銜接運用了何品種型。從最好到最差的銜接類型為const、eq_reg、ref、range、index和ALL
all: full table scan ;mysql將遍歷全表以找到婚配的行;
index : index scan; index 和 all的區別在於index類型只遍歷索引;
range:索引范圍掃描,對索引的掃描開端於某一點,前往婚配值的行,罕見與between ,< ,>等查詢;
ref:非獨一性索引掃描,前往婚配某個獨自值的一切行,罕見於運用非獨一索引即獨一索引的非獨一前綴停止查找;
eq_ref:獨一性索引掃描,關於每個索引鍵,表中只要一條記載與之婚配,常用於主鍵或許獨一索引掃描;
const,system:當mysql對某查詢某局部停止優化,並轉為一個常量時,運用這些訪問類型。假如將主鍵置於where列表中,mysql就能將該查詢轉化為一個常量。
possible_keys:顯示能夠使用在這張表中的索引。假如為空,沒有能夠的索引。可以為相關的域從WHERE語句中選擇一個適宜的語句
key: 實踐運用的索引。假如為NULL,則沒有運用索引。很少的狀況下,MYSQL會選擇優化缺乏的索引。這種狀況下,可以在SELECT語句中運用USE INDEX(indexname)來強迫運用一個索引或許用IGNORE INDEX(indexname)來強迫MYSQL疏忽索引
key_len:運用的索引的長度。在不損失准確性的狀況下,長度越短越好
ref:顯示索引的哪一列被運用了,假如能夠的話,是一個常數
rows:MYSQL以為必需反省的用來前往懇求數據的行數
Extra:關於MYSQL如何解析查詢的額定信息。將在表4.3中討論,但這裡可以看到的壞的例子是Using temporary和Using filesort,意思MYSQL基本不能運用索引,後果是檢索會很慢。
由於真正的優化會思索到大數據,我會在前面寫更詳細的優化教程,明天累了!分享一個詳細的mysql explain語法及運用教程(Mysql_Explain_語法詳細解析.pdf)!