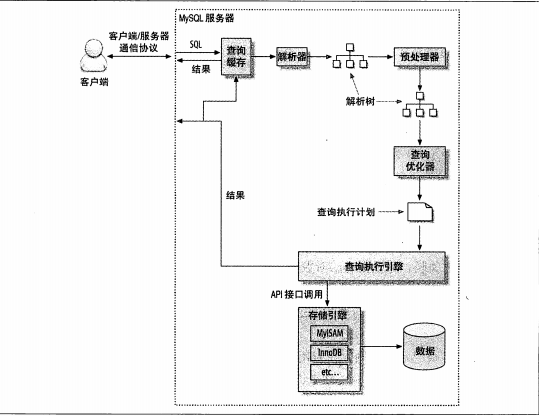
深化了解Mysql的四種隔離級別。本站提示廣大學習愛好者:(深化了解Mysql的四種隔離級別)文章只能為提供參考,不一定能成為您想要的結果。以下是深化了解Mysql的四種隔離級別正文
一、首先什麼是事務?
事務是使用順序中一系列緊密的操作,一切操作必需成功完成,否則在每個操作中所作的一切更改都會被吊銷。也就是事務具有原子性,一個事務中的一系列的操作要麼全部成功,要麼一個都不做。
事務的完畢有兩種,當事務中的所以步驟全部成功執行時,事務提交。假如其中一個步驟失敗,將發作回滾操作,吊銷吊銷之前到事務開端時的所以操作。
二、事務的 ACID
事務具有四個特征:原子性( Atomicity )、分歧性( Consistency )、隔離性( Isolation )和繼續性( Durability )。這四個特性簡稱為 ACID 特性。
1 、原子性。事務是數據庫的邏輯任務單位,事務中包括的各操作要麼都做,要麼都不做
2 、分歧性。事 務執行的後果必需是使數據庫從一個分歧性形態變到另一個分歧性形態。因而當數據庫只包括成功事務提交的後果時,就說數據庫處於分歧性形態。假如數據庫零碎 運轉中發作毛病,有些事務尚未完成就自願中綴,這些未完成事務對數據庫所做的修正有一局部已寫入物理數據庫,這時數據庫就處於一種不正確的形態,或許說是 不分歧的形態。
3 、隔離性。一個事務的執行不能其它事務攪擾。即一個事務外部的操作及運用的數據對其它並發事務是隔離的,並發執行的各個事務之間不能相互攪擾。
4 、繼續性。也稱永世性,指一個事務一旦提交,它對數據庫中的數據的改動就應該是永世性的。接上去的其它操作或毛病不應該對其執行後果有任何影響。
三、Mysql的四種隔離級別
SQL規范定義了4類隔離級別,包括了一些詳細規則,用來限定事務內外的哪些改動是可見的,哪些是不可見的。低級別的隔離級普通支持更高的並發處置,並擁有更低的零碎開支。
Read Uncommitted(讀取未提交內容)
在該隔離級別,一切事務都可以看到其他未提交事務的執行後果。本隔離級別很少用於實踐使用,由於它的功能也不比其他級別好多少。讀取未提交的數據,也被稱之為髒讀(Dirty Read)。
Read Committed(讀取提交內容)
這是大少數數據庫零碎的默許隔離級別(但不是MySQL默許的)。它滿足了隔離的復雜定義:一個事務只能看見曾經提交事務所做的改動。這種隔離級別 也支持所謂的不可反復讀(Nonrepeatable Read),由於同一事務的其他實例在該實例處置其間能夠會有新的commit,所以同一select能夠前往不同後果。
Repeatable Read(可重讀)
這是MySQL的默許事務隔離級別,它確保同一事務的多個實例在並發讀取數據時,會看到異樣的數據行。不過實際上,這會招致另一個順手的問題:幻讀 (Phantom Read)。復雜的說,幻讀指當用戶讀取某一范圍的數據行時,另一個事務又在該范圍內拔出了新行,當用戶再讀取該范圍的數據行時,會發現有新的“幻影” 行。InnoDB和Falcon存儲引擎經過多版本並發控制(MVCC,Multiversion Concurrency Control)機制處理了該問題。
Serializable(可串行化)
這是最高的隔離級別,它經過強迫事務排序,使之不能夠互相抵觸,從而處理幻讀問題。簡言之,它是在每個讀的數據行上加上共享鎖。在這個級別,能夠招致少量的超時景象和鎖競爭。
這四種隔離級別采取不同的鎖類型來完成,若讀取的是同一個數據的話,就容易發作問題。例如:
髒讀(Drity Read):某個事務已更新一份數據,另一個事務在此時讀取了同一份數據,由於某些緣由,前一個RollBack了操作,則後一個事務所讀取的數據就會是不正確的。
不可反復讀(Non-repeatable read):在一個事務的兩次查詢之中數據不分歧,這能夠是兩次查詢進程兩頭拔出了一個事務更新的原有的數據。
幻讀(Phantom Read):在一個事務的兩次查詢中數據筆數不分歧,例如有一個事務查詢了幾列(Row)數據,而另一個事務卻在此時拔出了新的幾列數據,先前的事務在接上去的查詢中,就會發現有幾列數據是它先前所沒有的。
在MySQL中,完成了這四種隔離級別,辨別有能夠發生問題如下所示:

四、測試Mysql的隔離級別
上面,將應用MySQL的客戶端順序,我們辨別來測試一下這幾種隔離級別。
測試數據庫為demo,表為test;表構造:

兩個命令行客戶端辨別為A,B;不時改動A的隔離級別,在B端修正數據。
(一)、將A的隔離級別設置為read uncommitted(未提交讀)

A:啟動事務,此時數據為初始形態

B:啟動事務,更新數據,但不提交
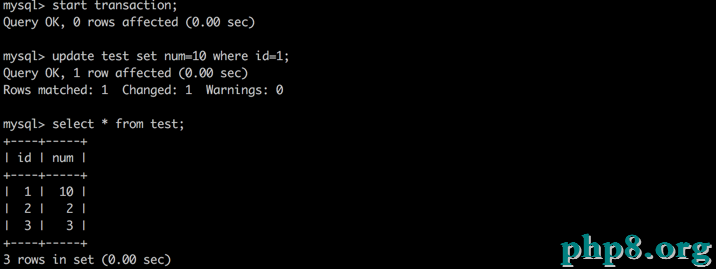
A:再次讀取數據,發現數據曾經被修正了,這就是所謂的“髒讀”

B:回滾事務

A:再次讀數據,發現數據變回初始形態

經過下面的實驗可以得出結論,事務B更新了一條記載,但是沒有提交,此時勢務A可以查詢出未提交記載。形成髒讀景象。未提交讀是最低的隔離級別。
(二)、將客戶端A的事務隔離級別設置為read committed(已提交讀)

A:啟動事務,此時數據為初始形態
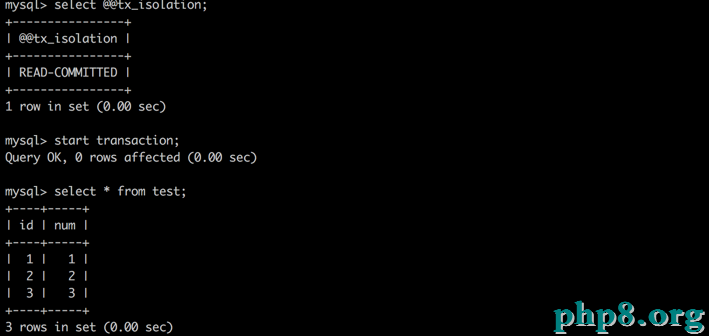
B:啟動事務,更新數據,但不提交
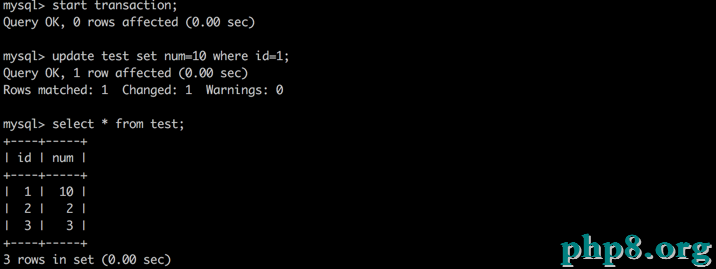
A:再次讀數據,發現數據未被修正

B:提交事務

A:再次讀取數據,發現數據已發作變化,闡明B提交的修正被事務中的A讀到了,這就是所謂的“不可反復讀”

經過下面的實驗可以得出結論,已提交讀隔離級別處理了髒讀的問題,但是呈現了不可反復讀的問題,即事務A在兩次查詢的數據不分歧,由於在兩次查詢之間事務B更新了一條數據。已提交讀只允許讀取已提交的記載,但不要求可反復讀。
(三)、將A的隔離級別設置為repeatable read(可反復讀)

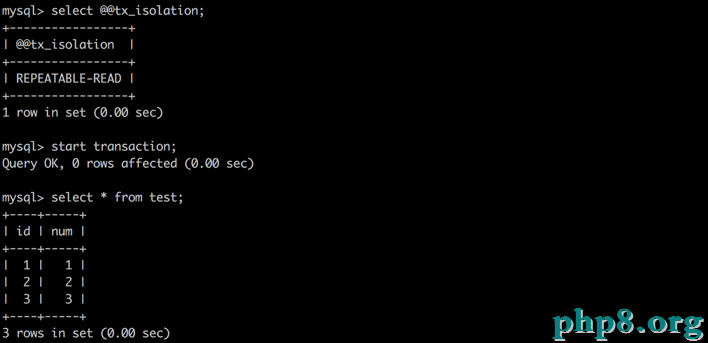
A:啟動事務,此時數據為初始形態
B:啟動事務,更新數據,但不提交
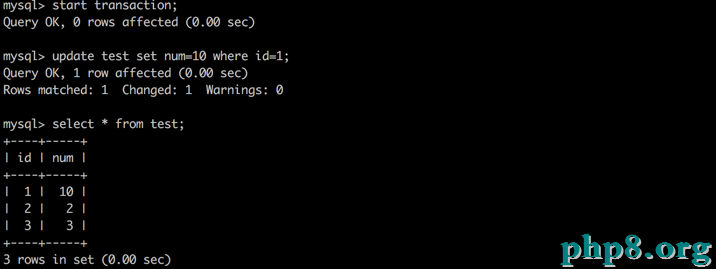
A:再次讀取數據,發現數據未被修正

B:提交事務

A:再次讀取數據,發現數據仍然未發作變化,這闡明這次可以反復讀了

B:拔出一條新的數據,並提交
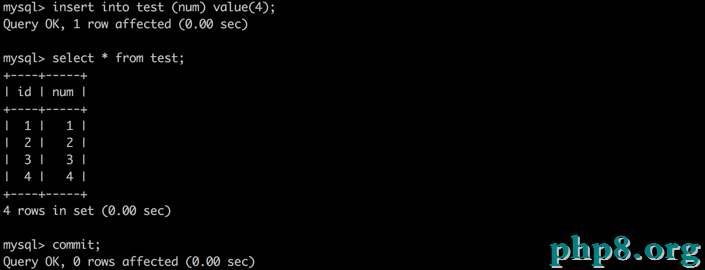
A:再次讀取數據,發現數據仍然未發作變化,雖然可以反復讀了,但是卻發現讀的不是最新數據,這就是所謂的“幻讀”

A:提交本次事務,再次讀取數據,發現讀取正常了
由以上的實驗可以得出結論,可反復讀隔離級別只允許讀取已提交記載,而且在一個事務兩次讀取一個記載時期,其他事務部的更新該記載。但該事務不要求與其他事務可串行化。例如,當一個事務可以找到由一個已提交事務更新的記載,但是能夠發生幻讀問題(留意是能夠,由於數據庫對隔離級別的完成有所差異)。像以上的實驗,就沒有呈現數據幻讀的問題。
(四)、將A的隔離級別設置為可串行化(Serializable)

A:啟動事務,此時數據為初始形態
B:發現B此時進入了等候形態,緣由是由於A的事務尚未提交,只能等候(此時,B能夠會發作等候超時)

A:提交事務

B:發現拔出成功

serializable完全鎖定字段,若一個事務來查詢同一份數據就必需等候,直到前一個事務完成並解除鎖定為止。是完好的隔離級別,會鎖定對應的數據表格,因此會無效率的問題。
總結
以上就是這篇文章全部內容了,希望本文的內容對大家的學習或許能有所協助,假如有疑問大家可以留言交流。