InnoDB的關鍵特性-插入緩存,兩次寫,自適應hash索引詳解。本站提示廣大學習愛好者:(InnoDB的關鍵特性-插入緩存,兩次寫,自適應hash索引詳解)文章只能為提供參考,不一定能成為您想要的結果。以下是InnoDB的關鍵特性-插入緩存,兩次寫,自適應hash索引詳解正文
InnoDB存儲引擎的關鍵特性包括插入緩沖、兩次寫(double write)、自適應哈希索引(adaptive hash index)。這些特性為InnoDB存儲引擎帶來了更好的性能和更高的可靠性。
插入緩沖
插入緩沖是InnoDB存儲引擎關鍵特性中最令人激動的。不過,這個名字可能會讓人認為插入緩沖是緩沖池中的一個部分。其實不然,InnoDB緩沖池中有Insert Buffer信息固然不錯,但是Insert Buffer和數據頁一樣,也是物理頁的一個組成部分。
主鍵是行唯一的標識符,在應用程序中行記錄的插入順序是按照主鍵遞增的順序進行插入的。因此,插入聚集索引一般是順序的,不需要磁盤的隨機讀取。
比如說我們按下列SQL定義的表:create table t(id int auto_increment,name varchar(30),primary key(id));
id列是自增長的,這意味著當執行插入操作時,id列會自動增長,頁中的行記錄按id執行順序存放。一般情況下,不需要隨機讀取另一頁執行記錄的存放。因此,在這樣的情況下,插入操作一般很快就能完成。但是,不可能每張表上只有一個聚集索引,在更多的情況下,一張表上有多個非聚集的輔助索引(secondary index)。比如,我們還需要按照name這個字段進行查找,並且name這個字段不是唯一的。
表是按如下的SQL語句定義的:create table t (id int auto_increment,name varchar(30),primary key(id),key(name));
這樣的情況下產生了一個非聚集的並且不是唯一的索引。在進行插入操作時,數據頁的存放還是按主鍵id的執行順序存放,但是對於非聚集索引,葉子節點的插入不再是順序的了。這時就需要離散地訪問非聚集索引頁,插入性能在這裡變低了。然而這並不是這個name字段上索引的錯誤,因為B+樹的特性決定了非聚集索引插入的離散性。
InnoDB存儲引擎開創性地設計了插入緩沖,對於非聚集索引的插入或更新操作,不是每一次直接插入索引頁中,而是先判斷插入的非聚集索引頁是否在緩沖池中。如果在,則直接插入;如果不在,則先放入一個插入緩沖區中,好似欺騙數據庫這個非聚集的索引已經插到葉子節點了,然後再以一定的頻率執行插入緩沖和非聚集索引頁子節點的合並操作,這時通常能將多個插入合並到一個操作中(因為在一個索引頁中),這就大大提高了對非聚集索引執行插入和修改操作的性能。
插入緩沖的使用需要滿足以下兩個條件:
1.索引是輔助索引。
2.索引不是唯一的。
當滿足以上兩個條件時,InnoDB存儲引擎會使用插入緩沖,這樣就能提高性能了。不過考慮一種情況,應用程序執行大量的插入和更新操作,這些操作都涉及了不唯一的非聚集索引,如果在這個過程中數據庫發生了宕機,這時候會有大量的插入緩沖並沒有合並到實際的非聚集索引中。如果是這樣,恢復可能需要很長的時間,極端情況下甚至需要幾個小時來執行合並恢復操作。
輔助索引不能是唯一的,因為在把它插入到插入緩沖時,我們並不去查找索引頁的情況。如果去查找肯定又會出現離散讀的情況,插入緩沖就失去了意義。
查看插入緩沖的信息:
show engine innodb status\G
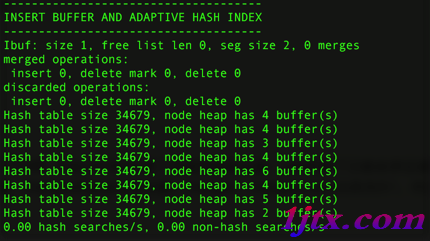
seg size顯示了當前插入緩沖的大小為2*16KB,free list len代表了空閒列表的長度,size代表了已經合並記錄頁的數量。
下面一行可能是我們真正關心的,因為它顯示了提高性能了。inserts代表插入的記錄數,merged recs代表合並的頁的數量,merges代表合並的次數。
merged recs:merges大約為3:1,代表插入緩沖將對於非聚集索引頁的IO請求大約降低了3倍。
問題:
目前插入緩沖存在一個問題是,在寫密集的情況下,插入緩沖會占用過多的緩沖池內存,默認情況下最大可以占用1/2的緩沖池內存。Percona已發布一些patch來修正插入緩沖占用太多緩沖池內存的問題,具體的可以到http://www.percona.com/percona-lab.html查找。簡單來說,修改IBUF_POOL_SIZE_PER_MAX_SIZE就可以對插入緩沖的大小進行控制,例如,將IBUF_POOL_SIZE_PER_MAX_SIZE改為3,則最大只能使用1/3的緩沖池內存。
兩次寫
如果說插入緩沖帶給InnoDB存儲引擎的是性能,那麼兩次寫帶給InnoDB存儲引擎的是數據的可靠性。當數據庫宕機時,可能發生數據庫正在寫一個頁面,而這個頁只寫了一部分(比如16K的頁,只寫前4K的頁)的情況,我們稱之為部分寫失效(partial page write)。在InnoDB存儲引擎未使用double write技術前,曾出現過因為部分寫失效而導致數據丟失的情況。
有人也許會想,如果發生寫失效,可以通過重做日志進行恢復。這是一個辦法。但是必須清楚的是,重做日志中記錄的是對頁的物理操作,如偏移量800,寫'aaaa'記錄。如果這個頁本身已經損壞,再對其進行重做是沒有意義的。這就是說,在應用(apply)重做日志前,我們需要一個頁的副本,當寫入失效發生時,先通過頁的副本來還原該頁,再進行重做,這就是doublewrite。
InnoDB存儲引擎doublewrite的體系架構如圖2-4所示
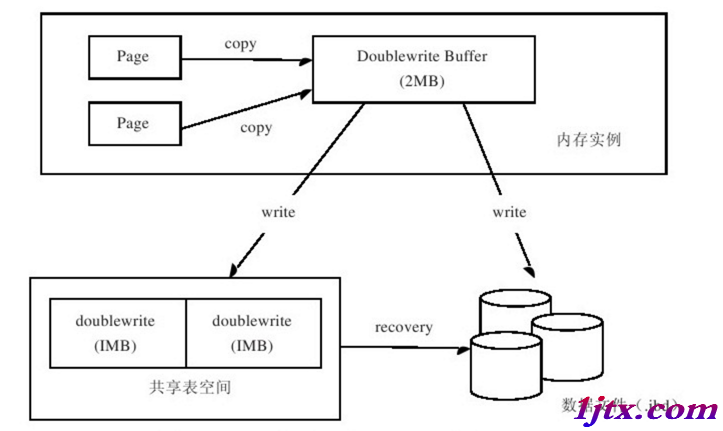
doublewrite由兩部分組成:一部分是內存中的doublewrite buffer,大小為2MB;另一部分是物理磁盤上共享表空間中連續的128個頁,即兩個區(extent),大小同樣為2MB(頁的副本)。當緩沖池的髒頁刷新時,並不直接寫磁盤,而是會通過memcpy函數將髒頁先拷貝到內存中的doublewrite buffer,之後通過doublewrite buffer再分兩次,每次寫入1MB到共享表空間的物理磁盤上,然後馬上調用fsync函數,同步磁盤,避免緩沖寫帶來的問題。在這個過程中,因為doublewrite頁是連續的,因此這個過程是順序寫的,開銷並不是很大。在完成doublewrite頁的寫入後,再將doublewrite buffer中的頁寫入各個表空間文件中,此時的寫入則是離散的。
可以通過以下命令觀察到doublewrite運行的情況: show global status like 'innodb_dblwr%'\G
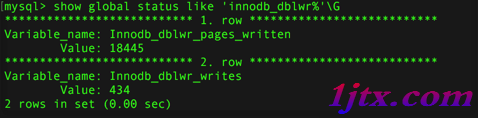
doublewrite一共寫了18 445個頁,但實際的寫入次數為434,(42:1) 基本上符合64:1。
如果發現你的系統在高峰時Innodb_dblwr_pages_written:Innodb_dblwr_writes遠小於64:1,那麼說明你的系統寫入壓力並不是很高。
如果操作系統在將頁寫入磁盤的過程中崩潰了,在恢復過程中,InnoDB存儲引擎可以從共享表空間中的doublewrite中找到改頁的一個副本,將其拷貝到表空間文件,再應用重做日志。下面顯示了由doublewrite進行恢復的一種情況:
090924 11:36:32 mysqld restarted 090924 11:36:33 InnoDB:Database was not shut down normally! InnoDB:Starting crash recovery. InnoDB:Reading tablespace information from the.ibd files…… InnoDB:Error:space id in fsp header 0,but in the page header 4294967295 InnoDB:Error:tablespace id 4294967295 in file./test/t.ibd is not sensible InnoDB:Error:tablespace id 0 in file./test/t2.ibd is not sensible 090924 11:36:33 InnoDB:Operating system error number 40 in a file operation. InnoDB:Error number 40 means'Too many levels of symbolic links'. InnoDB:Some operating system error numbers are described at InnoDB:http://dev.mysql.com/doc/refman/5.0/en/operating-system-error-codes.html InnoDB:File name./now/member InnoDB:File operation call:'stat'. InnoDB:Error:os_file_readdir_next_file()returned-1 in InnoDB:directory./now InnoDB:Crash recovery may have failed for some.ibd files! InnoDB:Restoring possible half-written data pages from the doublewrite InnoDB:buffer……
參數skip_innodb_doublewrite可以禁止使用兩次寫功能,這時可能會發生前面提及的寫失效問題。不過,如果你有多台從服務器(slave server),需要提供較快的性能(如slave上做的是RAID0),也許啟用這個參數是一個辦法。不過,在需要提供數據高可靠性的主服務器(master server)上,任何時候我們都應確保開啟兩次寫功能。
注意:有些文件系統本身就提供了部分寫失效的防范機制,如ZFS文件系統。在這種情況下,我們就不要啟用doublewrite了。
自適應哈希索引
哈希(hash)是一種非常快的查找方法,一般情況下查找的時間復雜度為O(1)。常用於連接(join)操作,如SQL Server和Oracle中的哈希連接(hash join)。但是SQL Server和Oracle等常見的數據庫並不支持哈希索引(hash index)。MySQL的Heap存儲引擎默認的索引類型為哈希,而InnoDB存儲引擎提出了另一種實現方法,自適應哈希索引(adaptive hash index)。
InnoDB存儲引擎會監控對表上索引的查找,如果觀察到建立哈希索引可以帶來速度的提升,則建立哈希索引,所以稱之為自適應(adaptive)的。自適應哈希索引通過緩沖池的B+樹構造而來,因此建立的速度很快。而且不需要將整個表都建哈希索引,InnoDB存儲引擎會自動根據訪問的頻率和模式來為某些頁建立哈希索引。
根據InnoDB的官方文檔顯示,啟用自適應哈希索引後,讀取和寫入速度可以提高2倍;對於輔助索引的連接操作,性能可以提高5倍。自適應哈希索引是非常好的優化模式,其設計思想是數據庫自優化(self-tuning),即無需DBA對數據庫進行調整。
查看當前自適應哈希索引的使用狀況:show engine innodb status\G
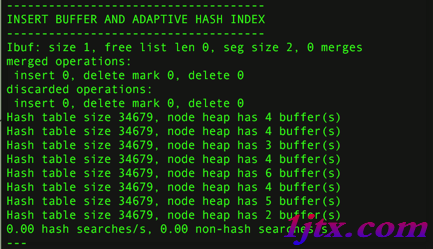
現在可以看到自適應哈希索引的使用信息了,包括自適應哈希索引的大小、使用情況、每秒使用自適應哈希索引搜索的情況。值得注意的是,哈希索引只能用來搜索等值的查詢,如select * from table where index_col='xxx',而對於其他查找類型,如范圍查找,是不能使用的。因此,這裡出現了non-hash searches/s的情況。用hash searches:non-hash searches命令可以大概了解使用哈希索引後的效率。
由於自適應哈希索引是由InnoDB存儲引擎控制的,所以這裡的信息只供我們參考。不過我們可以通過參數innodb_adaptive_hash_index來禁用或啟動此特性,默認為開啟。
以上這篇InnoDB的關鍵特性-插入緩存,兩次寫,自適應hash索引詳解就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持。