查找MySQL中查詢慢的SQL語句方法。本站提示廣大學習愛好者:(查找MySQL中查詢慢的SQL語句方法)文章只能為提供參考,不一定能成為您想要的結果。以下是查找MySQL中查詢慢的SQL語句方法正文
投稿:mdxy-dxy
這篇文章主要介紹了查找MySQL中查詢慢的SQL語句方法,需要的朋友可以參考下如何在mysql查找效率慢的SQL語句呢?這可能是困然很多人的一個問題,MySQL通過慢查詢日志定位那些執行效率較低的SQL 語句,用--log-slow-queries[=file_name]選項啟動時,mysqld 會寫一個包含所有執行時間超過long_query_time 秒的SQL語句的日志文件,通過查看這個日志文件定位效率較低的SQL 。下面介紹MySQL中如何查詢慢的SQL語句
一、MySQL數據庫有幾個配置選項可以幫助我們及時捕獲低效SQL語句
1,slow_query_log
這個參數設置為ON,可以捕獲執行時間超過一定數值的SQL語句。
2,long_query_time
當SQL語句執行時間超過此數值時,就會被記錄到日志中,建議設置為1或者更短。
3,slow_query_log_file
記錄日志的文件名。
4,log_queries_not_using_indexes
這個參數設置為ON,可以捕獲到所有未使用索引的SQL語句,盡管這個SQL語句有可能執行得挺快。
二、檢測mysql中sql語句的效率的方法
1、通過查詢日志
(1)、Windows下開啟MySQL慢查詢
MySQL在Windows系統中的配置文件一般是是my.ini找到[mysqld]下面加上
代碼如下
log-slow-queries = F:/MySQL/log/mysqlslowquery。log
long_query_time = 2
(2)、Linux下啟用MySQL慢查詢
MySQL在Windows系統中的配置文件一般是是my.cnf找到[mysqld]下面加上
代碼如下
log-slow-queries=/data/mysqldata/slowquery。log
long_query_time=2
說明
log-slow-queries = F:/MySQL/log/mysqlslowquery。
為慢查詢日志存放的位置,一般這個目錄要有MySQL的運行帳號的可寫權限,一般都將這個目錄設置為MySQL的數據存放目錄;
long_query_time=2中的2表示查詢超過兩秒才記錄;
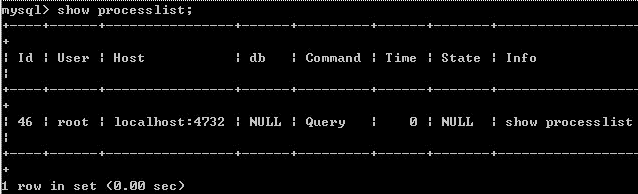
2.show processlist 命令
WSHOW PROCESSLIST顯示哪些線程正在運行。您也可以使用mysqladmin processlist語句得到此信息。
各列的含義和用途:
ID列
一個標識,你要kill一個語句的時候很有用,用命令殺掉此查詢 /*/mysqladmin kill 進程號。
user列
顯示單前用戶,如果不是root,這個命令就只顯示你權限范圍內的sql語句。
host列
顯示這個語句是從哪個ip的哪個端口上發出的。用於追蹤出問題語句的用戶。
db列
顯示這個進程目前連接的是哪個數據庫。
command列
顯示當前連接的執行的命令,一般就是休眠(sleep),查詢(query),連接(connect)。
time列
此這個狀態持續的時間,單位是秒。
state列
顯示使用當前連接的sql語句的狀態,很重要的列,後續會有所有的狀態的描述,請注意,state只是語句執行中的某一個狀態,一個 sql語句,以查詢為例,可能需要經過copying to tmp table,Sorting result,Sending data等狀態才可以完成
info列
顯示這個sql語句,因為長度有限,所以長的sql語句就顯示不全,但是一個判斷問題語句的重要依據。
這個命令中最關鍵的就是state列,mysql列出的狀態主要有以下幾種:
Checking table
正在檢查數據表(這是自動的)。
Closing tables
正在將表中修改的數據刷新到磁盤中,同時正在關閉已經用完的表。這是一個很快的操作,如果不是這樣的話,就應該確認磁盤空間是否已經滿了或者磁盤是否正處於重負中。
Connect Out
復制從服務器正在連接主服務器。
Copying to tmp table on disk
由於臨時結果集大於tmp_table_size,正在將臨時表從內存存儲轉為磁盤存儲以此節省內存。
Creating tmp table
正在創建臨時表以存放部分查詢結果。
deleting from main table
服務器正在執行多表刪除中的第一部分,剛刪除第一個表。
deleting from reference tables
服務器正在執行多表刪除中的第二部分,正在刪除其他表的記錄。
Flushing tables
正在執行FLUSH TABLES,等待其他線程關閉數據表。
Killed
發送了一個kill請求給某線程,那麼這個線程將會檢查kill標志位,同時會放棄下一個kill請求。MySQL會在每次的主循環中檢查kill標志位,不過有些情況下該線程可能會過一小段才能死掉。如果該線程程被其他線程鎖住了,那麼kill請求會在鎖釋放時馬上生效。
Locked
被其他查詢鎖住了。
Sending data
正在處理SELECT查詢的記錄,同時正在把結果發送給客戶端。
Sorting for group
正在為GROUP BY做排序。
Sorting for order
正在為ORDER BY做排序。
Opening tables
這個過程應該會很快,除非受到其他因素的干擾。例如,在執ALTER TABLE或LOCK TABLE語句行完以前,數據表無法被其他線程打開。正嘗試打開一個表。
Removing duplicates
正在執行一個SELECT DISTINCT方式的查詢,但是MySQL無法在前一個階段優化掉那些重復的記錄。因此,MySQL需要再次去掉重復的記錄,然後再把結果發送給客戶端。
Reopen table
獲得了對一個表的鎖,但是必須在表結構修改之後才能獲得這個鎖。已經釋放鎖,關閉數據表,正嘗試重新打開數據表。
Repair by sorting
修復指令正在排序以創建索引。
Repair with keycache
修復指令正在利用索引緩存一個一個地創建新索引。它會比Repair by sorting慢些。
Searching rows for update
正在講符合條件的記錄找出來以備更新。它必須在UPDATE要修改相關的記錄之前就完成了。
Sleeping
正在等待客戶端發送新請求.
System lock
正在等待取得一個外部的系統鎖。如果當前沒有運行多個mysqld服務器同時請求同一個表,那麼可以通過增加--skip-external-locking參數來禁止外部系統鎖。
Upgrading lock
INSERT DELAYED正在嘗試取得一個鎖表以插入新記錄。
Updating
正在搜索匹配的記錄,並且修改它們。
User Lock
正在等待GET_LOCK()。
Waiting for tables
該線程得到通知,數據表結構已經被修改了,需要重新打開數據表以取得新的結構。然後,為了能的重新打開數據表,必須等到所有其他線程關閉這個表。以下幾種情況下會產生這個通知:FLUSH TABLES tbl_name, ALTER TABLE, RENAME TABLE, REPAIR TABLE, ANALYZE TABLE,或OPTIMIZE TABLE。
waiting for handler insert
INSERT DELAYED已經處理完了所有待處理的插入操作,正在等待新的請求。
大部分狀態對應很快的操作,只要有一個線程保持同一個狀態好幾秒鐘,那麼可能是有問題發生了,需要檢查一下。
還有其他的狀態沒在上面中列出來,不過它們大部分只是在查看服務器是否有存在錯誤是才用得著。
例如如圖:
3、explain來了解SQL執行的狀態
explain顯示了mysql如何使用索引來處理select語句以及連接表。可以幫助選擇更好的索引和寫出更優化的查詢語句。
使用方法,在select語句前加上explain就可以了:
例如:
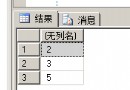
explain select surname,first_name form a,b where a.id=b.id
結果如圖

EXPLAIN列的解釋
table
顯示這一行的數據是關於哪張表的
type
這是重要的列,顯示連接使用了何種類型。從最好到最差的連接類型為const、eq_reg、ref、range、indexhe和ALL
possible_keys
顯示可能應用在這張表中的索引。如果為空,沒有可能的索引。可以為相關的域從WHERE語句中選擇一個合適的語句
key
實際使用的索引。如果為NULL,則沒有使用索引。很少的情況下,MYSQL會選擇優化不足的索引。這種情況下,可以在SELECT語句 中使用USE INDEX(indexname)來強制使用一個索引或者用IGNORE INDEX(indexname)來強制MYSQL忽略索引
key_len
使用的索引的長度。在不損失精確性的情況下,長度越短越好
ref
顯示索引的哪一列被使用了,如果可能的話,是一個常數
rows
MYSQL認為必須檢查的用來返回請求數據的行數
Extra
關於MYSQL如何解析查詢的額外信息。將在表4.3中討論,但這裡可以看到的壞的例子是Using temporary和Using filesort,意思MYSQL根本不能使用索引,結果是檢索會很慢
extra列返回的描述的意義
Distinct
一旦MYSQL找到了與行相聯合匹配的行,就不再搜索了
Not exists
MYSQL優化了LEFT JOIN,一旦它找到了匹配LEFT JOIN標准的行,就不再搜索了
Range checked for each Record(index map:#)
沒有找到理想的索引,因此對於從前面表中來的每一個行組合,MYSQL檢查使用哪個索引,並用它來從表中返回行。這是使用索引的最慢的連接之一
Using filesort
看到這個的時候,查詢就需要優化了。MYSQL需要進行額外的步驟來發現如何對返回的行排序。它根據連接類型以及存儲排序鍵值和匹配條件的全部行的行指針來排序全部行
Using index
列數據是從僅僅使用了索引中的信息而沒有讀取實際的行動的表返回的,這發生在對表的全部的請求列都是同一個索引的部分的時候
Using temporary
看到這個的時候,查詢需要優化了。這裡,MYSQL需要創建一個臨時表來存儲結果,這通常發生在對不同的列集進行ORDER BY上,而不是GROUP BY上
Where used
使用了WHERE從句來限制哪些行將與下一張表匹配或者是返回給用戶。如果不想返回表中的全部行,並且連接類型ALL或index,這就會發生,或者是查詢有問題不同連接類型的解釋(按照效率高低的順序排序)
const
表中的一個記錄的最大值能夠匹配這個查詢(索引可以是主鍵或惟一索引)。因為只有一行,這個值實際就是常數,因為MYSQL先讀這個值然後把它當做常數來對待
eq_ref
在連接中,MYSQL在查詢時,從前面的表中,對每一個記錄的聯合都從表中讀取一個記錄,它在查詢使用了索引為主鍵或惟一鍵的全部時使用
ref
這個連接類型只有在查詢使用了不是惟一或主鍵的鍵或者是這些類型的部分(比如,利用最左邊前綴)時發生。對於之前的表的每一個行聯合,全部記錄都將從表中讀出。這個類型嚴重依賴於根據索引匹配的記錄多少—越少越好
range
這個連接類型使用索引返回一個范圍中的行,比如使用>或<查找東西時發生的情況
index
這個連接類型對前面的表中的每一個記錄聯合進行完全掃描(比ALL更好,因為索引一般小於表數據)
ALL
這個連接類型對於前面的每一個記錄聯合進行完全掃描,這一般比較糟糕,應該盡量避免
MySQL - 查看慢SQL
查看MySQL是否啟用了查看慢SQL的日志文件
(1) 查看慢SQL日志是否啟用
mysql> show variables like 'log_slow_queries';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| log_slow_queries | ON |
+------------------+-------+
1 row in set (0.00 sec)
(2) 查看執行慢於多少秒的SQL會記錄到日志文件中
mysql> show variables like 'long_query_time';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| long_query_time | 1 |
+-----------------+-------+
1 row in set (0.00 sec)
這裡value=1, 表示1秒
2. 配置my.ini文件(inux下文件名為my.cnf), 查找到[mysqld]區段,增加日志的配置,如下示例:
[mysqld]
log="C:/temp/mysql.log"
log_slow_queries="C:/temp/mysql_slow.log"
long_query_time=1
log指示日志文件存放目錄;
log_slow_queries指示記錄執行時間長的sql日志目錄;
long_query_time指示多長時間算是執行時間長,單位s。
Linux下這些配置項應該已經存在,只是被注釋掉了,可以去掉注釋。但直接添加配置項也OK啦。
查詢到效率低的 SQL 語句 後,可以通過 EXPLAIN 或者 DESC 命令獲取 MySQL 如何執行 SELECT 語句的信息,包括在 SELECT 語句執行過程中表如何連接和連接的順序,比如我們想計算 2006 年所有公司的銷售額,需要關聯 sales 表和 company 表,並且對 profit 字段做求和( sum )操作,相應 SQL 的執行計劃如下:
mysql> explain select sum(profit) from sales a,company b where a.company_id = b.id and a.year = 2006\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: a
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 12
Extra: Using where
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: b
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 12
Extra: Using where
2 rows in set (0.00 sec)
每個列的解釋如下:
•select_type :表示 SELECT 的 類型,常見的取值有 SIMPLE (簡單表,即不使用表連接或者子查詢)、 PRIMARY (主查詢,即外層的查詢)、 UNION ( UNION 中的第二個或者後面的查詢語句)、 SUBQUERY (子查詢中的第一個 SELECT )等。
•table :輸出結果集的表。
•type :表示表的連接類型,性能由好到差的連接類型為 system (表中僅有一行,即常量表)、 const (單表中最多有一個匹配行,例如 primary key 或者 unique index )、 eq_ref (對於前面的每一行,在此表中只查詢一條記錄,簡單來說,就是多表連接中使用 primary key 或者 unique index )、 ref (與 eq_ref 類似,區別在於不是使用 primary key 或者 unique index ,而是使用普通的索引)、 ref_or_null ( 與 ref 類似,區別在於條件中包含對 NULL 的查詢 ) 、 index_merge ( 索引合並優化 ) 、 unique_subquery ( in 的後面是一個查詢主鍵字段的子查詢)、 index_subquery ( 與 unique_subquery 類似,區別在於 in 的後面是查詢非唯一索引字段的子查詢)、 range (單表中的范圍查詢)、 index (對於前面的每一行,都通過查詢索引來得到數據)、 all (對於前面的每一行,都通過全表掃描來得到數據)。
•possible_keys :表示查詢時,可能使用的索引。
•key :表示實際使用的索引。
•key_len :索引字段的長度。
•rows :掃描行的數量。
•Extra :執行情況的說明和描述。
在上面的例子中,已經可以確認是 對 a 表的全表掃描導致效率的不理想,那麼 對 a 表的 year 字段創建索引,具體如下:
mysql> create index idx_sales_year on sales(year);
Query OK, 12 rows affected (0.01 sec)
Records: 12 Duplicates: 0 Warnings: 0
創建索引後,這條語句的執行計劃如下:
mysql> explain select sum(profit) from sales a,company b where a.company_id = b.id and a.year = 2006\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: a
type: ref
possible_keys: idx_sales_year
key: idx_sales_year
key_len: 4
ref: const
rows: 3
Extra:
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: b
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 12
Extra: Using where
2 rows in set (0.00 sec)
可以發現建立索引後對 a 表需要掃描的行數明顯減少(從全表掃描減少到 3 行),可見索引的使用可以大大提高數據庫的訪問速度,尤其在表很龐大的時候這種優勢更為明顯,使用索引優化 sql 是優化問題 sql 的一種常用基本方法,在後面的章節中我們會具體介紹如何使索引來優化 sql 。
本文主要介紹的是MySQL慢查詢分析方法,前一段日子,我曾經設置了一次記錄在MySQL數據庫中對慢於1秒鐘的SQL語句進行查詢。想起來有幾個十分設置的方法,有幾個參數的名稱死活回憶不起來了,於是重新整理一下,自己做個筆記。
對於排查問題找出性能瓶頸來說,最容易發現並解決的問題就是MySQL慢查詢以及沒有得用索引的查詢。
OK,開始找出MySQL中執行起來不“爽”的SQL語句吧。
MySQL慢查詢分析方法一:
這個方法我正在用,呵呵,比較喜歡這種即時性的。
MySQL5.0以上的版本可以支持將執行比較慢的SQL語句記錄下來。
MySQL> show variables like 'long%';
注:這個long_query_time是用來定義慢於多少秒的才算“慢查詢”
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
1 row in set (0.00 sec)
MySQL> set long_query_time=1;
注: 我設置了1, 也就是執行時間超過1秒的都算慢查詢。
Query OK, 0 rows affected (0.00 sec)
MySQL> show variables like 'slow%';
+---------------------+---------------+
| Variable_name | Value |
+---------------------+---------------+
| slow_launch_time | 2 |
| slow_query_log | ON |
注:是否打開日志記錄
| slow_query_log_file | /tmp/slow.log |
注: 設置到什麼位置
+---------------------+---------------+
3 rows in set (0.00 sec)
MySQL> set global slow_query_log='ON'
注:打開日志記錄
一旦slow_query_log變量被設置為ON,MySQL會立即開始記錄。
/etc/my.cnf 裡面可以設置上面MySQL全局變量的初始值。
long_query_time=1 slow_query_log_file=/tmp/slow.log
MySQL慢查詢分析方法二:
MySQLdumpslow命令
/path/MySQLdumpslow -s c -t 10 /tmp/slow-log
這會輸出記錄次數最多的10條SQL語句,其中:
-s, 是表示按照何種方式排序,c、t、l、r分別是按照記錄次數、時間、查詢時間、返回的記錄數來排序,ac、at、al、ar,表示相應的倒敘;
-t, 是top n的意思,即為返回前面多少條的數據;
-g, 後邊可以寫一個正則匹配模式,大小寫不敏感的;
比如
/path/MySQLdumpslow -s r -t 10 /tmp/slow-log
得到返回記錄集最多的10個查詢。
/path/MySQLdumpslow -s t -t 10 -g “left join” /tmp/slow-log
得到按照時間排序的前10條裡面含有左連接的查詢語句。
簡單點的方法:
打開 my.ini ,找到 [mysqld] 在其下面添加 long_query_time = 2 log-slow-queries = D:/mysql/logs/slow.log #設置把日志寫在那裡,可以為空,系統會給一個缺省的文件 #log-slow-queries = /var/youpath/slow.log linux下host_name-slow.log log-queries-not-using-indexes long_query_time 是指執行超過多長時間(單位是秒)的sql會被記錄下來,這裡設置的是2秒。
以下是mysqldumpslow常用參數說明,詳細的可應用mysqldumpslow -help查詢。 -s,是表示按照何種方式排序,c、t、l、r分別是按照記錄次數、時間、查詢時間、返回的記錄數來排序(從大到小),ac、at、al、ar表示相應的倒敘。 -t,是top n的意思,即為返回前面多少條數據。 www.jb51.net -g,後邊可以寫一個正則匹配模式,大小寫不敏感。 接下來就是用mysql自帶的慢查詢工具mysqldumpslow分析了(mysql的bin目錄下 ),我這裡的日志文件名字是host-slow.log。 列出記錄次數最多的10個sql語句 mysqldumpslow -s c -t 10 host-slow.log 列出返回記錄集最多的10個sql語句 mysqldumpslow -s r -t 10 host-slow.log 按照時間返回前10條裡面含有左連接的sql語句 mysqldumpslow -s t -t 10 -g "left join" host-slow.log 使用mysqldumpslow命令可以非常明確的得到各種我們需要的查詢語句,對MySQL查詢語句的監控、分析、優化起到非常大的幫助
在日常開發當中,經常會遇到頁面打開速度極慢的情況,通過排除,確定了,是數據庫的影響,為了迅速查找具體的SQL,可以通過Mysql的日志記錄方法。
-- 打開sql執行記錄功能
set global log_output='TABLE'; -- 輸出到表
set global log=ON; -- 打開所有命令執行記錄功能general_log, 所有語句: 成功和未成功的.
set global log_slow_queries=ON; -- 打開慢查詢sql記錄slow_log, 執行成功的: 慢查詢語句和未使用索引的語句
set global long_query_time=0.1; -- 慢查詢時間限制(秒)
set global log_queries_not_using_indexes=ON; -- 記錄未使用索引的sql語句
-- 查詢sql執行記錄
select * from mysql.slow_log order by 1; -- 執行成功的:慢查詢語句,和未使用索引的語句
select * from mysql.general_log order by 1; -- 所有語句: 成功和未成功的.
-- 關閉sql執行記錄
set global log=OFF;
set global log_slow_queries=OFF;
-- long_query_time參數說明
-- v4.0, 4.1, 5.0, v5.1 到 5.1.20(包括):不支持毫秒級別的慢查詢分析(支持精度為1-10秒);
-- 5.1.21及以後版本 :支持毫秒級別的慢查詢分析, 如0.1;
-- 6.0 到 6.0.3: 不支持毫秒級別的慢查詢分析(支持精度為1-10秒);
-- 6.0.4及以後:支持毫秒級別的慢查詢分析;
通過日志中記錄的Sql,迅速定位到具體的文件,優化sql看一下,是否速度提升了呢?
本文針對MySQL數據庫服務器查詢逐漸變慢的問題, 進行分析,並提出相應的解決辦法,具體的分析解決辦法如下:會經常發現開發人員查一下沒用索引的語句或者沒有limit n的語句,這些沒語句會對數據庫造成很大的影...
本文針對MySQL數據庫服務器查詢逐漸變慢的問題, 進行分析,並提出相應的解決辦法,具體的分析解決辦法如下:
會經常發現開發人員查一下沒用索引的語句或者沒有limit n的語句,這些沒語句會對數據庫造成很大的影響,例如一個幾千萬條記錄的大表要全部掃描,或者是不停的做filesort,對數據庫和服務器造成io影響等。這是鏡像庫上面的情況。
而到了線上庫,除了出現沒有索引的語句,沒有用limit的語句,還多了一個情況,mysql連接數過多的問題。說到這裡,先來看看以前我們的監控做法
1. 部署zabbix等開源分布式監控系統,獲取每天的數據庫的io,cpu,連接數
2. 部署每周性能統計,包含數據增加量,iostat,vmstat,datasize的情況
3. Mysql slowlog收集,列出top 10
以前以為做了這些監控已經是很完美了,現在部署了mysql節點進程監控之後,才發現很多弊端
第一種做法的弊端: zabbix太龐大,而且不是在mysql內部做的監控,很多數據不是非常准備,現在一般都是用來查閱歷史的數據情況
第二種做法的弊端:因為是每周只跑一次,很多情況沒法發現和報警
第三種做法的弊端: 當節點的slowlog非常多的時候,top10就變得沒意義了,而且很多時候會給出那些是一定要跑的定期任務語句給你。。參考的價值不大
那麼我們怎麼來解決和查詢這些問題呢
對於排查問題找出性能瓶頸來說,最容易發現並解決的問題就是MYSQL的慢查詢以及沒有得用索引的查詢。
OK,開始找出mysql中執行起來不“爽”的SQL語句吧。
方法一: 這個方法我正在用,呵呵,比較喜歡這種即時性的。
Mysql5.0以上的版本可以支持將執行比較慢的SQL語句記錄下來。
mysql> show variables like 'long%'; 注:這個long_query_time是用來定義慢於多少秒的才算“慢查詢”
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
1 row in set (0.00 sec)
mysql> set long_query_time=1; 注: 我設置了1, 也就是執行時間超過1秒的都算慢查詢。
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like 'slow%';
+---------------------+---------------+
| Variable_name | Value |
+---------------------+---------------+
| slow_launch_time | 2 |
| slow_query_log | ON | 注:是否打開日志記錄
| slow_query_log_file | /tmp/slow.log | 注: 設置到什麼位置
+---------------------+---------------+
3 rows in set (0.00 sec)
mysql> set global slow_query_log='ON' 注:打開日志記錄
一旦slow_query_log變量被設置為ON,mysql會立即開始記錄。
/etc/my.cnf 裡面可以設置上面MYSQL全局變量的初始值。
long_query_time=1
slow_query_log_file=/tmp/slow.log
方法二:mysqldumpslow命令
/path/mysqldumpslow -s c -t 10 /tmp/slow-log
這會輸出記錄次數最多的10條SQL語句,其中:
-s, 是表示按照何種方式排序,c、t、l、r分別是按照記錄次數、時間、查詢時間、返回的記錄數來排序,ac、at、al、ar,表示相應的倒敘;
-t, 是top n的意思,即為返回前面多少條的數據;
-g, 後邊可以寫一個正則匹配模式,大小寫不敏感的;
比如
/path/mysqldumpslow -s r -t 10 /tmp/slow-log
得到返回記錄集最多的10個查詢。
/path/mysqldumpslow -s t -t 10 -g “left join” /tmp/slow-log
得到按照時間排序的前10條裡面含有左連接的查詢語句。
最後總結一下節點監控的好處
1. 輕量級的監控,而且是實時的,還可以根據實際的情況來定制和修改
2. 設置了過濾程序,可以對那些一定要跑的語句進行過濾
3. 及時發現那些沒有用索引,或者是不合法的查詢,雖然這很耗時去處理那些慢語句,但這樣可以避免數據庫掛掉,還是值得的
4. 在數據庫出現連接數過多的時候,程序會自動保存當前數據庫的processlist,DBA進行原因查找的時候這可是利器
5. 使用mysqlbinlog 來分析的時候,可以得到明確的數據庫狀態異常的時間段
有些人會建義我們來做mysql配置文件設置
調節tmp_table_size 的時候發現另外一些參數
Qcache_queries_in_cache 在緩存中已注冊的查詢數目
Qcache_inserts 被加入到緩存中的查詢數目
Qcache_hits 緩存采樣數數目
Qcache_lowmem_prunes 因為缺少內存而被從緩存中刪除的查詢數目
Qcache_not_cached 沒有被緩存的查詢數目 (不能被緩存的,或由於 QUERY_CACHE_TYPE)
Qcache_free_memory 查詢緩存的空閒內存總數
Qcache_free_blocks 查詢緩存中的空閒內存塊的數目
Qcache_total_blocks 查詢緩存中的塊的總數目
Qcache_free_memory 可以緩存一些常用的查詢,如果是常用的sql會被裝載到內存。那樣會增加數據庫訪問速度