一、LRU鏈:
任何緩存的大小都是有限制的,並且總不如被緩存的數據多。就像Buffer cache用來緩存數據文件,數據文件的大小遠遠超過Buffer cache。因此,緩存總有被占滿的時候。當緩存中已經沒有空閒內存塊時,如果新的數據要求進入緩存,就只有從緩存中原來的數據中選出一個犧牲者,用新進入緩存的數據覆蓋這個犧牲者。這一點我們在共享池中曾提及過,這個犧牲者的選擇,是很重要的。緩存是為了數據可以重用,因此,通常應該挑選緩存中最沒有可能被重用的塊當作犧牲者。犧牲者的選擇,從CPU的L1、L2緩存,到共享池、Buffer cache池,絕大多數的緩存池都是采用著名的LRU算法,不過在Oracle中,Oracle采用了經過改進的LRU算法。具體的算法它沒有公布,不過LRU算法總的宗旨就是――“最近最少”,其意義是將最後被訪問的時間距現在最遠的內存塊作為犧牲者。比如說,現在有三個內存塊,分別是A、B、C,A被訪問過10次,最後一次訪問是在10:20,B被訪問過15次,最後一次訪問是10:18,C也被訪問10次,最後一次被訪問是在10:22。當需要選擇犧牲者時,B訪問次數最多,犧牲者肯定不是它。A、C訪問次數一樣,但A在10:20被訪問,而C在10:22被訪問,A最後被訪問的更早些,犧牲者就是A。注意,這就是LRU的宗旨,“將最後訪問時間距現在最遠的塊作為犧牲者”。
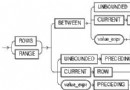
為了實現LRU的功能,Oracle在Buffer cache中創建了一個LRU鏈表,Oracle將Buffer cache中所有內存塊,按照訪問次數、訪問時間排序串在鏈表中。鏈表的兩頭我們分別叫做熱端與冷端, 如下圖

當你第一次訪問某個塊時,如果這個塊不在Buffer cache中,Oracle要選將它讀進Buffer cache。在Buffer cache中選擇犧牲者時,Oracle將從冷端頭開始選擇,在上圖的例子中,內存塊U將是犧牲者。

如上圖,新塊將會被讀入U,覆蓋U原來的內容。這裡,我們假設新塊是V。但是塊V不會被放在冷端頭,因為冷端頭的塊,會很快被當作犧牲者權覆蓋的。這不符合“將最後訪問時間距現在最遠的塊作為犧牲者”的宗旨。塊V是最後時間距當前時刻最近的,它不應該作為下一個犧牲者。Oracle是如何實驗LRU的,我們繼續看。

Oracle將LRU鏈從中間分為兩半,一半記錄熱端塊、一半記錄冷端塊。如上圖,而剛剛被訪問的塊V,如下圖:


如過再有新的塊進入Buffer cache,比如塊X被讀入Buffer cache,它將覆蓋T,並且會被移至塊V的前面,如下圖:

大家可以想像一下,如果按照這面的方式繼續下去,最右邊冷端頭處的塊,一定是最後一次訪問時間距現在最遠的塊。那麼,訪問次數多的塊是不會被選做犧牲者的,這一點Oracle是如何實現的?這很簡單,Oracle一般以2次為准,塊被訪問2次以上了,它就有機會進入熱端。
Oracle為內存中的每個塊都添加了一個記錄訪問次數的標志位,假設圖中每個塊的訪問次數如下:

如果現在又有新塊要被讀入Buffer cache,Oracle開始從冷端頭尋找犧牲者,冷端頭第一個塊S,它的訪問次數是2,那麼,它不能被覆蓋,只要訪問次數大於等於2的塊,Oracle會認為它可能會被經常訪問到,Oracle要把它移到熱端,它會選擇R做為本次的犧牲者:
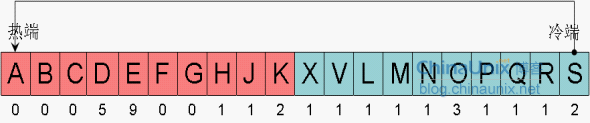

塊S會被從冷端移到熱端,並且它的訪問次數會被清零。此時,塊R就是犧牲者了,因為它的訪問次數不到兩次。

新塊Y覆蓋了塊R,並被移到了冷端塊開始處,它的訪問次數是1。如果塊Y再被訪問了一次,它的訪問次數變為了2:

雖然Y的訪問次數達到了兩次,但它不會馬上被移到熱端,它仍然留在原來的位置,隨著不斷有新塊加入,被插入到它的前面,它會不斷的被向後推移。

如上圖,又加入了很多的新塊,Y又被推到了冷端頭,當再有新塊進入Buffer cache時,Y不會是犧牲者,它會被移到熱端頭S的前面,Y後面的Z,它的訪問次數沒有達到2,它將會是犧牲者。
好了,這就是Oracle中Buffer cache管理LRU的原理。按照這種方式運作,Oracle可以把常用的塊盡量長的保持在Buffer cache中。而且,每有新塊進入Buffer cache,Oracle都會從冷端頭處,從右向左搜索犧牲塊。因為越靠近冷端,塊的訪問次數有可能越少、最後的訪問時間離現在最遠。好了,LRU鏈還沒有講完,下面,我們再討論一下髒塊與髒LRU鏈的問題。
二、髒塊與髒LRU鏈:
Oracle中修改塊的規則是只對Buffer cache中的塊進行修改,並不直接修改磁盤中的塊。如果要修改的塊不在Buffer cache中,Oracle會先將它讀入Buffer cache,再在Buffer cache中進行修改。當Buffer cache中的塊被修改後,Oracle會把它標記為“髒”塊。髒塊含有髒數據,髒數據就是用戶修改過的數據。Oracle會定期的將髒塊寫到磁盤中。有一個專門的後台進程就是專門負責寫髒塊到磁盤的,它就是DBWn。我們也把DBWn寫髒塊到磁盤這個過程叫做刷新髒塊,刷新過後,髒塊就不髒了,又變成了干淨塊。其實,有一個塊A,如果Buffer cache中此塊的數據和磁盤上塊中數據不一致,那麼,這個塊就是髒塊。否則,就是干淨塊。當修改完成後,因為Oracle只修改Buffer cache,因此,塊中數據和磁盤肯定不一致,這時塊就是髒塊。當塊被刷新後,塊被寫到磁盤,那麼,磁盤中塊數據和Buffer cache中塊的數據又是一致的,此時,塊就又變成了干淨塊。
髒塊在被寫回磁盤前,也就是在它還是髒塊時,它是不能被覆蓋的,因為,髒塊含有用戶修改過的數據,而這些數據還沒被寫到磁盤,如果此時覆蓋了髒塊,用戶的修改結果將會丟失。

設當前LRU鏈如上圖所示,其中V、L、O、P、Q是髒塊。當新的塊要進入Buffer cache時,Oracle從冷端頭開始選擇犧牲塊,Q、P和O都不能做作犧牲塊,因為它們是髒塊,N是這一次的犧牲者,新進入的塊將會覆蓋N,然後將N插入到Y之前。然後呢,下一次有塊進入Buffer cache時,Oracle從冷端頭開始搜索,它還要檢查一邊Q、P和O,發現它們都不能覆蓋,再將M定為犧牲者。等等,每一次都要檢查一邊O、P、Q,這太浪費時間了,Oracle不會這麼傻,Oracle有准備了一個髒LRU鏈,專門保存髒塊。當塊變髒時,塊不會馬上被移到髒LRU中,只有當Oracle從冷端頭開始,尋找犧牲者時,才會將發現的髒塊移動到髒LRU鏈中。這樣做的目的我們剛才已經快要講到了,就是下次再尋找犧牲者時,可以不用再檢查這些髒塊。好,讓我們繼續看圖,接著上圖,有新塊Z要進入Buffer cache:

如上圖,O、P、Q將被移到髒LRU鏈中。
冷端頭變成了N,N的訪問次數小於2,它就是本次的犧牲者了。這樣當下一次再需要從冷端頭開始尋找犧牲者時,就不用再檢查O、P、Q這三個髒塊了。當髒LRU鏈的長度,也就是髒LRU鏈中的髒塊達到一定數目時,DBWn會開始刷新髒塊。
通過上面所講述的LRU鏈與髒LRU鏈的原理,我們可以發現Oracle把很多工作,都留到了在LRU的冷端搜索犧牲者時。當塊的訪問次數增加的超過2時,塊在LUR鏈的位置不變;當塊變髒時,塊的LRU鏈位置也不變。只有當從LRU的冷端搜索犧牲者時,才會將發現的髒塊移到髒LRU鏈,將訪問次數超過2的,插入到熱端,這就是Oracle改進了的LRU算法。Oracle這樣做的目的,是為了讓我們平時的查詢、修改所需完成的操作盡量的少。對於用戶的查詢、修改操作,LRU算法幾乎沒有任何的影響,額外所做的工作只是改變了幾個標志位而已,查詢時增加訪問次數標志位,修改塊時設置髒塊標志位。LRU算法大部分的工作,都是在尋找犧牲者時完成的。因此,有時尋找犧牲者這個過程有可能會出現等待,等待事件是free buffer waits。
訪問次數大於2的塊太多,或髒塊太多,反正這些塊都是不能覆蓋的,Oracle不得不移動它們到它們該去的位置。當碰到的這樣的塊超過LRU中總塊數的40%時,也就是說搜索了一小半LRU鏈,還是沒有發現可以覆蓋的犧牲者,Oracle就不在找了,它會喚醒DBWn刷新髒塊。在DBWn刷新期間的等待,就會被記入到free buffer waits事件中。另外,在資料視圖中有一個資料free buffer inspected,它記錄了Oracle在所有次的尋找犧牲者的過程中,共計碰到了多少個不可覆蓋的塊。
在尋找犧牲者過程中發現髒塊,Oracle將其移動到髒LRU鏈,但是髒LRU鏈中髒塊數目達到限制,DBWn被喚醒開始刷新髒塊,Oracle必須等待刷新髒塊完畢,才能再繼續尋找犧牲者,這其間的等待事件,也會被記入free buffer inspected。
總之,free buffer waits事件發生的主要原因就是在LRU中尋找犧牲者的時間過長。如果這個等待事件頻繁出現,說明Buffer cache中髒塊太了,這通常是DBWn寫刷新速度慢造成的。我們應該將DBWn更頻繁的被喚醒去刷新髒塊,好讓它們變干淨、可以被選為犧牲者。我們不應該讓髒塊從髒LRU鏈中被刷新,因為這時通常會出現free buffer inspected。髒LRU鏈並不是為了將髒塊集中到一起,讓DBWn去刷新的,我們上面的圖例中已經講過,將髒塊移動到髒LRU鏈中,是為了減少下一次尋找犧牲者時,所需搜尋的塊。Oracle中另有一個鏈表,專門用來記錄髒塊,好讓DBWn定期刷新,這個鏈表是檢查點隊列。