order by 從英文裡理解就是行的排序方式,默認的為升序。 order by 後面必須列出排序的字段名,可以是多個字段名。
group by 從英文裡理解就是分組。必須有“聚合函數”來配合才能使用,使用時至少需要一個分組標志字段。
什麼是“聚合函數”?
像sum()、count()、avg()等都是“聚合函數”
使用group by 的目的就是要將數據分類匯總。
一般如:
select 單位名稱,count(職工id),sum(職工工資) form [某表]
group by 單位名稱
這樣的運行結果就是以“單位名稱”為分類標志統計各單位的職工人數和工資總額。
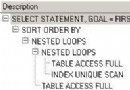
在sql命令格式使用的先後順序上,group by 先於 order by。
select 命令的標准格式如下:
SELECT select_list
[ INTO new_table ]
FROM table_source
[ WHERE search_condition ]
[ GROUP BY group_by_expression ]
[ HAVING search_condition ]
1. GROUP BY 是分組查詢, 一般 GROUP BY 是和聚合函數配合使用
group by 有一個原則,就是 select 後面的所有列中,沒有使用聚合函數的列,必須出現在 group by 後面(重要)
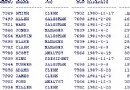
例如,有如下數據庫表:
列A 列B
1 abc
1 bcd
1 asdfg
如果有如下查詢語句(該語句是錯誤的,原因見前面的原則)
select A,B from table group by A
該查詢語句的意圖是想得到如下結果(當然只是一相情願)
列A 列B
abc
1 bcd
asdfg
右邊3條如何變成一條,所以需要用到聚合函數,如下(下面是正確的寫法):
select A,count(B) as 數量 from table group by A
這樣的結果就是
A 數量
1 3
2. Having
where 子句的作用是在對查詢結果進行分組前,將不符合where條件的行去掉,即在分組之前過濾數據,條件中不能包含聚組函數,使用where條件顯示特定的行。
having 子句的作用是篩選滿足條件的組,即在分組之後過濾數據,條件中經常包含聚組函數,使用having 條件顯示特定的組,也可以使用多個分組標准進行分組。
having 子句被限制子已經在SELECT語句中定義的列和聚合表達式上。通常,你需要通過在HAVING子句中重復聚合函數表達式來引用聚合值,就如你在SELECT語句中做的那樣。例如:
SELECT A COUNT(B) FROM TABLE GROUP BY A HAVING COUNT(B)>2