如果你有兩個數據來源,如平面文件或表數據,並且要將他們合並在一起,你將怎麼做?如果他們有一個共同的屬性,如客戶ID,那麼該解決方案應該是很明顯:合並相關的屬性,在這個例子中,只需合並客戶ID就夠了。如果沒有任何共同之處該怎麼辦呢?唯一的要求就是,將數據源1中的記錄和數據源2中的記錄進行匹配 。並且,那個記錄去和另一個記錄匹配並沒有關系,那麼問題是,一個數據源中的每一個紀錄如何獲得從其他數據源記錄的標記。
上述問題可以被描述為向一個數據庫中加入了不同的或看似無關的數據。在先前的文章的文章中,涉及如何使用ROWNUM在無關的數據之間創造聯系。該合並方法的本質是利用甲骨文提供虛擬數據列來建立聯系。下面的查詢可以用來作為CREATE TABLE AS SELECT聲明的一部分或作為基於滿足加入條件既定目標表的插入。
SELECT * FROM
(SELECT , ROWNUM AS rownum_a
FROM TABLE_A
) ALIAS_A,
(SELECT , ROWNUM AS rownum_b
FROM TABLE_B
) ALIAS_B
WHERE ALIAS_A.rownum_a = ALIAS_B.rownum_b;
假設要合並的記錄的數目過大(如數以百萬計),這種方法潛在的缺點是什麼?那麼,當一行作為一個記錄時又如何了?我們沒有真正的控制權決定的查詢所返回結果行的順序,直到我們執行查詢之前,甲骨文是不知道記錄的行號的。換言之, ROWNUM是在這樣的事實上創建的。如果你要從兩個地方選擇數百萬行,你將支付甲骨文公司為每個記錄分配行號(只針對你的查詢,而不是永遠)的時間。
讓我們監測將兩個有100萬行的表合並到一起的一個會話。在這第一個例子中,這個數據源已經記錄可100萬個記錄。表A范圍從1到1000000及表B范圍從1000001至2000000 (即在第一個表中再加入100萬行) 。如果加入後能夠完美的保持行的順序,那麼有序對將像下面表格這個樣子:
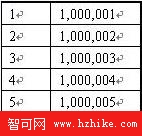
當我們查看數據時(通過Toad)發現Oracle數據庫並不執行一個完美的排序,並且相差甚遠。
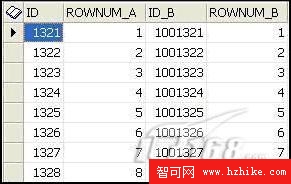
該ROWNUM_A和B值一個一個都匹配,因為這是我們匹配/合並的。注意:記錄1321 (和1001321 )是如何同ROWNUM 1標記在一起的 。所以我們可以推斷是,甲骨文以同樣的方式填補表格之間的空白區塊。這應該說服你一次甚至永遠(如果你至今還不知知道), ROWNUM虛擬數據列已沒有意義或與個表中記錄的實際順序無關。
創建表的聲明追蹤, 經過TKPROF 解析後,輸出結果如下:
CREATE TABLE TABLE_ROWNUM AS SELECT * FROM (SELECT ID, ROWNUM AS rownum_a FROM TABLE_A) ALIAS_A, (SELECT ID AS id_b, ROWNUM AS rownum_b FROM TABLE_B) ALIAS_B WHERE ALIAS_A.rownum_a = ALIAS_B.rownum_b call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ----------
Parse 1 0.01 0.00 0 0 0 0 Execute 1 4.41 5.63 1770 12324 5239 1000000 Fetch 0 0.00 0.00 0 0 0 0 ------- ------ -------- ---------- ---------- ----------
total 2 4.42 5.64 1770 12324 5239 1000000
我們知道一個事實,即每個表都有100萬行。在分析了表後, NUM_ROWS值顯示為1034591 。當與甲骨文本身將通過連續計數報告的值相比較時要小心依靠通過第三方工具檢查出的值(包括從USER_TABLES選擇NUM_ROWS )。為什麼會有差異呢?是否是因為分析是基於樣本或估算的數據,或根據檢查到的每個記錄?
現在,對於合並數據有一個可供選擇的辦法。那就是讓我們使用一個真正的列替代虛擬數據列,一個自然的選擇是創建(在某種意義上)基於序列替代關鍵字。這個辦法是為每個表添加一個命名為SEQ的列,並且在基於序列號對他們進行更新,並且保證每次更新使用相同的起點和相同的增量。對一個表更新操作如下所示。
SQL> create sequence tab_b; Sequence created. Elapsed: 00:00:00.05 SQL> update table_b set seq = tab_b.nextval; 1000000 rows updated. Elapsed: 00:05:00.05
有一件事應該可以立即脫穎而出:創造一個合並關鍵字所花費的時間剛剛超過五分鐘,或是ROWNUM采取的方法所花費時間的13倍,這只是對兩個表中的一個表所進行操作所花費的時間(第一張表格花費五分鐘進行更新) 。增加或創建一個合並關鍵字是必要的,如有可能,最好在創建表的時候就創建。那麼,比通過ROWNUM做同樣的事情所多花費的關鍵點是什麼?
根據新的設置,如何進行合並?
CREATE TABLE TABLE_SEQ AS SELECT * FROM (SELECT ID, SEQ AS seq_a FROM TABLE_A) ALIAS_A, (SELECT ID AS id_b, SEQ AS seq_b FROM TABLE_B) ALIAS_B WHERE ALIAS_A.seq_a = ALIAS_B.seq_b call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- Parse 1 0.00 0.06 0 0 0 0 Execute 1 10.64 24.43 12186 12370 5677 1000000 Fetch 0 0.00 0.00 0 0 0 0 ------- ------ -------- ---------- ---------- ----------
total 2 10.64 24.49 12186 12370 5677 1000000
有趣的是,既然數據並非如此不同,性能也只是略差。那麼解釋計劃展示的是什麼?使用ROWNUM原始測試,我們有:
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------
Plan hash value: 1354216904
------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
------------------------------------------------------------------------
| 0 | CREATE TABLE STATEMENT | | 10G| 496G| | 15M (2)| 50:40:43 |
| 1 | LOAD AS SELECT | TABLE_ROWNUM | | | | | |
|* 2 | HASH JOIN | | 10G| 496G| 36M| 186K (97)| 00:37:19 |
| 3 | VIEW | | 1009K| 25M| | 1597 (10)| 00:00:20 |
| 4 | COUNT | | | | | | |
| 5 | TABLE ACCESS FULL | TABLE_B | 1009K| 4930K| | 1381 (11)| 00:00:17 |
| 6 | VIEW | | 1016K| 25M| | 1475 (10)| 00:00:18 |
| 7 | COUNT | | | | | | |
| 8 | TABLE ACCESS FULL | TABLE_A | 1016K| 3969K| | 1285 (12)| 00:00:16 |
-------------------------------------------------------------------------
Predicate Information (identifIEd by Operation id):
---------------------------------------------------
2 - Access("ALIAS_A"."ROWNUM_A"="ALIAS_B"."ROWNUM_B")
基於序列的合並似乎是一個更好的計劃。
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------
Plan hash value: 1354216904
-------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
-------------------------------------------------------------------------
| 0 | CREATE TABLE STATEMENT | | 10G| 496G| | 15M (2)| 50:40:43 |
| 1 | LOAD AS SELECT | TABLE_ROWNUM | | | | | |
|* 2 | HASH JOIN | | 10G| 496G| 36M| 186K (97)| 00:37:19 |
| 3 | VIEW | | 1009K| 25M| | 1597 (10)| 00:00:20 |
| 4 | COUNT | | | | | | |
| 5 | TABLE ACCESS FULL | TABLE_B | 1009K| 4930K| | 1381 (11)| 00:00:17 |
| 6 | VIEW | | 1016K| 25M| | 1475 (10)| 00:00:18 |
| 7 | COUNT | | | | | | |
| 8 | TABLE ACCESS FULL | TABLE_A | 1016K| 3969K| | 1285 (12)| 00:00:16 |
-------------------------------------------------------------------------
Predicate Information (identifIEd by Operation id):
---------------------------------------------------
2 - Access("ALIAS_A"."ROWNUM_A"="ALIAS_B"."ROWNUM_B")
雖然這是一個相對較小的數據集,你可以明白為什麼執行該計劃的花費可能會引起誤解。如果基於序列的表在同一會話中被刪除和重新建立,創建表重新刪除的時間到剛剛超過2秒。在表面上看,第二輪創建的表似乎要快得多,但真正要證明的是什麼呢?
所要證明的是,數據塊已經讀入緩存,從緩存中讀取數據塊的速度將遠遠超過從磁盤雙方讀取的速度(這我們已經知道的事實) 。它實際意義是:你創建表需要多少時間?這通常是一次性完成。如果原始表被刪除和重創,它的創建時間將大大加快。
通過清除共享池和緩存來恢復性能, 在ROWNUM和基於序的列情況下所花費的時間分別 14秒和10秒的。在這一點上,它可能看起來像是混為一談。但在運行期間,其性能級別交換了。這也許是事實,但不要忘記設置了序列為基礎的表格的費用(按時間)。
總結
從某種意義上說,最為相似的數據集,操作系統和平台依賴性(多少行,內存和I / O等) ,他們可以更快地在不同數據集之間添加一個共同的屬性,然後在進行合並操作。對於較小的數據集,也許略高於100萬行,我冒昧地說,使用ROWNUM這將永遠是比新增一個合並關鍵字更快,即使使用常見的關鍵創建表的速度更快。那麼,什麼時候適當使用ROWNUM ?當在沒有共同關鍵字的情況時,你不關心表之間的特殊關聯,即使是正好就存在這樣的事實。如果你正在處理相關表,他們基於一個共同的屬性,並且這些關聯必須排序,你一定不能依賴ROWNUM保持合並表之間的順序。它事關,在一個表中具體行是否與第二個表中特定行匹配。