一、歷史背景
Oracle數據庫的全文檢索技術已經非常完美,Oracle Text使Oracle9i具備了強大的文本檢索能力和智能化的文本管理能力。Oracle Text是Oracle9i采用的新名稱,在Oracle8/8i中它被稱作Oracle interMedia Text,在Oracle8以前它的名稱是Oracle ConText Cartridge。
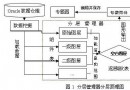
二、Oracle Text 索引文檔時所使用的主要邏輯步驟如下:
(1) 數據存儲邏輯搜索表的所有行,並讀取列中的數據。通常,這只是列數據,但有些數據存儲使用列數據作為文檔數據的指針。
(2) 過濾器提取文檔數據並將其轉換為文本表示方式。存儲二進制文檔 (如 Word 或 Acrobat 文件) 時需要這樣做。過濾器的輸出不必是純文本格式 -- 它可以是 XML 或 Html 之類的文本格式。
(3) 分段器提取過濾器的輸出信息,並將其轉換為純文本。包括 XML 和 Html 在內的不同文本格式有不同的分段器。轉換為純文本涉及檢測重要文檔段標記、移去不可見的信息和文本重新格式化。
(4) 詞法分析器提取分段器中的純文本,並將其拆分為不連續的標記。既存在空白字符分隔語言使用的詞法分析器,也存在分段復雜的亞洲語言使用的專門詞法分析器。
(5) 索引引擎提取詞法分析器中的所有標記、文檔段在分段器中的偏移量以及被稱為非索引字的低信息含量字列表,並構建反向索引。倒排索引存儲標記和含有這些標記的文檔。
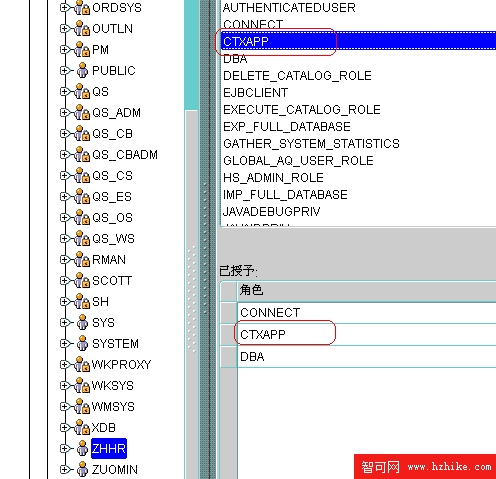
三、需要的權限
要使用Oracle Text,必須具有CTXAPP角色或者是CTXSYS用戶。Oracle Text為系統管理員提供CTXSYS用戶,為應用程序開發人員提供CTXAPP角色。具有CTXAPP角色的用戶可執行以下任務:創建索引,管理 Oracle Text 數據字典,包括創建和刪除首選項,進行Oracle Text 查詢,使用 Oracle Text PL/SQL程序包。
如圖所示:
四、具體的實現
文本裝入文本列後,就可以創建Oracle Text索引。文檔以許多不同方案、格式和語言存儲。因此,每個 Oracle Text 索引有許多需要設置的選項,以針對特定情況配置索引。創建索引時,Oracle Text可使用若干個默認值,但在大多數情況下要求用戶通過指定首選項來配置索引。
每個索引的許多選項組成功能組,稱為"類",每個類集中體現配置的某一方面,可以認為這些類就是與文檔數據庫有關的一些問題。例如:數據存儲、過濾器、詞法分析器、相關詞表、存儲等。
每個類具有許多預定義的行為,稱之為對象。每個對象是類問題可能具有的答案,並且大多數對象都包含有屬性。通過屬性來定制對象,從而使對索引的配置更加多變以適應於不同的應用。
(1)存儲(Storage)類
存儲類指定構成Oracle Text索引的數據庫表和索引的表空間參數和創建參數。它僅有一個基本對象:BASIC_STORAGE,其屬性包括:I_Index_Clause、I_Table_Clause、K_Table_Clause、N_Table_Clause、P_Table_Clause、R_Table_Clause。
(2)數據存儲(Datastore)類
數據存儲:關於列中存儲文本的位置和其他信息。默認情況下,文本直接存儲到列中,表中的每行都表示一個單獨的完整文檔。其他數據存儲位置包括存儲在單獨文件中或以其 URL 標識的 Web 頁上。七個基本對象包括:Default_Datastore、Detail_Datastore、Direct_Datastore、File_Datastore、Multi_Column_Datastore 、URL_Datastore、User_Datastore。
(3)文檔段組(Section Group)類
文檔段組是用於指定一組文檔段的對象。必須先定義文檔段,然後才能使用索引通過 WITHIN 運算符在文檔段內進行查詢。文檔段定義為文檔段組的一部分。包含七個基本對象:AUTO_SECTION_GROUP、BASIC_SECTION_GROUP、Html_SECTION_GROUP、NEWS_SECTION_GROUP、NULL_SECTION_GROUP、XML_SECTION_GROUP、PATH_SECTION_GROUP。
(4)相關詞表(Wordlist)類
相關詞表標識用於索引的詞干和模糊匹配查詢選項的語言,只有一個基本對象BASIC_WordLIST,其屬性有:Fuzzy_Match、Fuzzy_Numresults、Fuzzy_Score、Stemmer、Substring_Index、Wildcard_Maxterms、Prefix_Index、Prefix_Max_Length、Prefix_Min_Length。
(5)索引集(Index Set)
索引集是一個或多個Oracle 索引 (不是Oracle Text索引) 的集合,用於創建 CTXCAT類型的Oracle Text索引,只有一個基本對象BASIC_INDEX_SET。
(6)詞法分析器(Lexer)類
詞法分析器類標識文本使用的語言,還確定在文本中如何標識標記。默認的詞法分析器是英語或其他西歐語言,用空格、標准標點和非字母數字字符標識標記,同時禁用大小寫。包含8個基本對象:BASIC_LEXER、CHINESE_LEXER、CHINESE_VGRAM_LEXER、JAPANESE_LEXER、JAPANESE_VGRAM_LEXER、KOREAN_LEXER、KOREAN__MORPH_ LEXER、MULTI_LEXER。
(7)過濾器(Filter)類
過濾器確定如何過濾文本以建立索引。可以使用過濾器對文字處理器處理的文檔、格式化的文檔、純文本和 Html 文檔建立索引,包括5個基本對象:CHARSET_FILTER、INSO_FILTER INSO、NULL_FILTER、PROCEDURE_FILTER、USER_FILTER。
(8)非索引字表(Stoplist)類
非索引字表類是用以指定一組不編入索引的單詞 (稱為非索引字)。有兩個基本對象:BASIC_STOPLIST (一種語言中的所有非索引字) 、 MULTI_STOPLIST (包含多種語言中的非索引字的多語言非索引字表)。
具體操作實踐
1、 創建詞法分析器及相關詞表
Begin-- 定義一個詞法分析器
ctx_ddl.drop_preference('cnlex');
ctx_ddl.create_preference('cnlex','CHINESE_LEXER'); --針對中文
-- 定義一個相關詞表
ctx_ddl.create_preference('mywordlist', 'BASIC_WordLIST');
ctx_ddl.set_attribute('myWordlist','PREFIX_INDEX','TRUE');
ctx_ddl.set_attribute('myWordlist','PREFIX_MIN_LENGTH',1);
ctx_ddl.set_attribute('myWordlist','PREFIX_MAX_LENGTH', 5);
ctx_ddl.set_attribute('myWordlist','SUBSTRING_INDEX', 'YES');
end;
// 上面的語句中,如果是針對英語語種則可以采用下面的語句來定義詞法分析器
ctx_ddl.create_preference('mylex','BASIC_LEXER');
ctx_ddl.set_attribute('mylex','printjoins','_-');
2、 在需要創建全文索引的表中創建索引(索引類型必須是 ctxsys.context,即應用上下文索引)
create index idx_person_desc on personinfo(persondesc)indextype is ctxsys.context
parameters (
'DATASTORE CTXSYS.DIRECT_DATASTORE FILTER
CTXSYS.NULL_FILTER LEXER cnlex WORDLIST myWordlist');
-- 請注意此處采用的是NULL_FILTER過濾器,如果采用INSO_FILTER則不能對中文進行全文索引
3、進行全文索引的同步
exec ctx_ddl.sync_index('idx_user_info', '20M');
具體理解
Oracle實現全文檢索,其機制其實很簡單。即通過Oracle專利的詞法分析器(lexer),將文章中所有的表意單元(Oracle 稱為 term,此處我理解為單詞或者一些有意義的詞語) 找出來,記錄在一組以 dr$開頭的表中,同時記下該term出現的位置、次數、hash 值等信息。檢索時,Oracle 從這組表中查找相應的 term,並計算其出現頻率,根據某個算法來計算每個文檔的得分(score),即所謂的‘匹配率’。而lexer則是該機制的核心,它決定了全文檢索的效率。Oracle 針對不同的語言提供了不同的 lexer, 而我們通常能用到其中的三個:
basic_lexer: 針對英語。它能根據空格和標點來將英語單詞從句子中分離,還能自動將一些出現頻率過高已經失去檢索意義的單詞作為‘垃圾’處理,如if , is 等,具有較高的處理效率。但該lexer應用於漢語則有很多問題,由於它只認空格和標點,而漢語的一句話中通常不會有空格,因此,它會把整句話作為一個term,事實上失去檢索能力。以‘中國人民站起來了’這句話為例,basic_lexer 分析的結果只有一個term ,就是‘中國人民站起來了’。此時若檢索‘中國’,將檢索不到內容。
chinese_vgram_lexer: 專門的漢語分析器,支持所有漢字字符集。該分析器按字為單元來分析漢語句子。‘中國人民站起來了’這句話,會被它分析成如下幾個term: ‘中’,‘中國’,‘國人’,‘人民’,‘民站’,‘站起’,起來’,‘來了’,‘了’。可以看出,這種分析方法,實現算法很簡單,並且能實現‘一網打盡’,但效率則是差強人意。
chinese_lexer: 這是一個新的漢語分析器,只支持utf8字符集。上面已經看到,chinese vgram lexer這個分析器由於不認識常用的漢語詞匯,因此分析的單元非常機械,像上面的‘民站’,‘站起’在漢語中根本不會單獨出現,因此這種term是沒有意義的,反而影響效率。chinese_lexer的最大改進就是該分析器能認識大部分常用漢語詞匯,因此能更有效率地分析句子,像以上兩個愚蠢的單元將不會再出現,極大提高了效率。但是它只支持 utf8, 如果你的數據庫是zhs16gbk字符集,則只能使用笨笨的那個Chinese vgram lexer。
--以上的說法是針對於Oracle8i或者是更低級版本的,在Oracle 9.2中采用 Chinese_lexer 分析器測試是沒有這個問題的。
如果不做任何設置,Oracle 缺省使用basic_lexer這個分析器。要指定使用哪一個lexer, 可以這樣操作:
第一,在ctxsys用戶下建立一個preference:
ctx_ddl.create_preference('cnlex','CHINESE_LEXER');
第二,在建立intermedia索引時,指明所用的lexer:
create index idx_person_desc on personinfo(persondesc)indextype is ctxsys.context
parameters (
'DATASTORE CTXSYS.DIRECT_DATASTORE FILTER
CTXSYS.NULL_FILTER LEXER cnlex WORDLIST myWordlist')
這樣建立的全文檢索索引,就會使用CHINESE_LEXER作為分析器。
使用job定時同步和優化
在intermedia索引建好後,如果表中的數據發生變化,比如增加或修改了記錄,怎麼辦?由於對表所發生的任何dml語句,都不會自動修改索引,因此,必須定時同步(sync)和優化(optimize)索引,以正確反映數據的變化。
在索引建好後,我們可以在該用戶下查到Oracle自動產生了以下幾個表:(假設索引名為myindex):
DR$myindex$I,DR$myindex$K,DR$myindex$R,DR$myindex$N
其中以I表最重要,可以查詢一下該表,看看有什麼內容:
select token_text, token_count from DR$I_RSK1$I where rownum<=20;
可以看到,該表中保存的其實就是Oracle 分析你的文檔後,生成的term記錄在這裡,包括term出現的位置、次數、hash值等。當文檔的內容改變後,可以想見這個I表的內容也應該相應改變,才能保證Oracle在做全文檢索時正確檢索到內容(因為所謂全文檢索,其實核心就是查詢這個表)。那麼如何維護該表的內容呢?總不能每次數據改變都重新建立索引吧!這就用到sync 和 optimize了。
同步(sync):將新的term 保存到I表。
優化(optimize):清除I表的垃圾,主要是將已經被刪除的term從I表刪除。
檢查全文索引是否創建成功
1、檢查DR$myindex$I是否存在,其中的 myindex 代表建立的索引名稱;
2、檢查全文索引是否創建成功,最好采用 Contains來檢查,具體的語法為
Contains(ColumnName,SearcherKey) > 0// ColumnName為所需要檢查的列名,也即創建了全文索引的列名
// SearcherKey 為你需要查找的內容,為字符型
列如,按上面創建的全文索引,可以使用如下的語句:
Select * From PERSONINFO Where Containts(PERSONDESC, 'abcd',1) > 0Select * From PERSONINFO Where Containts(PERSONDESC, 'abcd',1) > 0
如果你創建的全文索引不成功,則返回失敗,其內容為:
ORA-20000: Oracle Text error: DRG-10599: 列沒有編制索引
當然,如果你創建成功,則會正確返回數據。還有一個檢查全文索引是否創建成功的方法是感覺創建全文索引後的查詢速度。
測試數據
下面是對一個表進行操作時,在同一台機器中獲得的測試數據。
PersonInfo表中共有 182263 條記錄,其中persondesc不為null的記錄數為180187 條記錄,
其中,persondesc 包括 “大學”兩個漢字的記錄數為 21579 條記錄
persondesc 包括 “1999”兩個漢字的記錄數為 10889條記錄
測試一、直接用like 來查詢中文“大學”
SQL: Select count(*) From personinfo Where persondesc like '%大學%'
時間開銷:耗時 40秒 688 毫秒
測試二、直接用like 來查詢英文“1999”
SQL: Select count(*) From personinfo Where persondesc like '%1999%'
時間開銷:耗時 47秒 218毫秒
測試三、未創建全文索引時,直接用dbms_lob.instr 來查詢中文“大學”
SQL: Select count(*) From personinfo Where dbms_lob.instr(persondesc,'大學',1,1)>0
時間開銷:耗時 47秒 031毫秒
測試四、未創建全文索引時,直接用dbms_lob.instr 來查詢英文“1999”
SQL: Select count(*) From personinfo Where dbms_lob.instr(persondesc,'1999',1,1)>0
時間開銷:耗時 44秒 360毫秒
測試五、未創建全文索引時,直接用Contains 來查詢中文“大學”
SQL: Select count(*) From personinfo Where Contains(persondesc,'大學',1)>0";
執行失敗: ORA-20000: Oracle Text error: DRG-10599: 列沒有編制索引
測試六、未創建全文索引時,直接用Contains 來查詢英文“1999”
SQL: Select count(*) From personinfo Where Contains(persondesc,'1999',1)>0";
執行失敗: ORA-20000: Oracle Text error: DRG-10599: 列沒有編制索引
測試七、采用CHINESE_LEXER詞法分析器創建全文索引後,直接用Contains 來查詢英文“1999”
SQL: Select count(*) From personinfo Where Contains(persondesc,'1999',1)>0";
時間開銷:第一次查詢耗時 469毫秒,後面的多次查詢耗時 210毫秒左右
***查詢出來的記錄數比在未建立索引時用like、dbms_lob.instr方式查詢出來的記錄數要少一些
測試八、采用CHINESE_LEXER詞法分析器創建全文索引後,直接用Contains 來查詢中文“大學”
SQL: Select count(*) From personinfo Where Contains(persondesc,'大學',1)>0";
時間開銷:第一次查詢耗時 9秒359毫秒,後面的多次查詢耗時 210毫秒左右
***查詢出來的記錄數比在未建立索引時用like、dbms_lob.instr方式查詢出來的記錄數要少一些
測試九、采用CHINESE_LEXER詞法分析器創建全文索引後,用dbms_lob.instr 來查詢中文“大學”
SQL: Select count(*) From personinfo Where dbms_lob.instr(persondesc,'大學',1,1)>0
時間開銷:耗時 54秒 953毫秒
測試十、采用CHINESE_LEXER詞法分析器創建全文索引後,直接用dbms_lob.instr 來查詢英文“1999”
SQL: Select count(*) From personinfo Where dbms_lob.instr(persondesc,'1999',1,1)>0
時間開銷:耗時 52秒 652毫秒
總體感覺Oracle的中文全文索引不是很好。後續版本或許會有所改進吧。