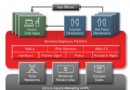
在Oracle不共享體系的結構下並行處理像分布式數據庫的運作是一樣的。我們都知道每個節點都以其獨占方式來擁有其數據的分區。沒有其它任何節點可以訪問此數據,而使節點成為單一的訪問點和故障點。
此方法具有一些基本缺點,無法解決今天高端環境對可伸縮性和高可用性要求:
(1)、首先,不共享方法在用於共享一切的SMP硬件時並不是最佳的。為了獲得並行處理的益處而要求對數據進行物理分區,在共享一切的SMP系統中很明顯是一種人工的、過時的要求。因為在SMP系統中每個處理器都可以對所有數據進行直接的、等同的訪問。
(2)、其次,在不共享方法中使用嚴格的基於分區的並行處理策略,通常會導致不正常的資源利用。例如以下兩種情況:在沒有必要訪問表的所有分區時;或當單一節點所擁有的更大的未分區表是操作的一部分時。在這些情況下,限制分區內並行處理的緊密所有權模式,無法利用所有可用的處理能力,因而不能提供最佳的處理能力使用方案。
(3)、第三,由於具有對節點對應物理數據分區的關系,不共享系統在適應變化的業務需求方面一點都不靈活。當業務增長時,無法方便地以增量方式擴充系統來適應增長的業務需求。可以升級所有現有的節點,保持它們對稱並避免數據重新分區。
在大多數情形下,升級所有節點費用太高;必須添加新節點並重組(進行物理重新分區)現有數據庫。一個不需要進行任何重組的方案總是比必須重組的方案要更好,即使可以利用到最復雜的重組工具。
(4)、最後,由於使用嚴格的受限制的訪問模式,不共享系統無法完全利用群集系統為保證系統高可靠性所提供的潛在的容錯能力。
毫無疑問,基於使用靜態數據分布的Oracle不共享體系結構,大量的並行處理可以在實驗室條件下並行化和擴展。然而,在每個現實環境中,必須正確地解決上面談到的問題才能滿足今天高端關鍵任務要求。
Oracle數據庫並行處理技術之執行時的動態並行——共享一切
使用Oracle 的動態並行處理框架,可以共享所有數據。並行化和將工作分成更小的單元的決策,並不受限於數據庫設置(創建)時所做的任何預先確定的靜態數據分布。
由於能夠為每個語句構造不受限制的、優化的數據子集,執行時動態並行可以提供與不共享體系結構等同的或甚至更好的可伸縮性。
每個查詢在訪問、連接和處理數據的不同部分時都有它自己的特征。因此,每個SQL語句在被解析時都要進行優化和並行化處理。數據更改時,如果有更加優化的並行執行計劃可用,或者系統中新添加了一個節點,那麼Oracle可以自動適應新的情況。這樣可為並行化任何種類的操作提供最高程度的靈活性:
(1)、在語句執行前,對於每個查詢要求,會動態地優化並行訪問的物理數據子集。
(2)、對於每個查詢,都會優化其並行度。與不共享環境不同,不存在必需的最小並行度來調用所有節點訪問所有數據,這是訪問所有數據的基礎要求。
(3)、操作可以根據當前工作負載、特征和查詢的重要性,使用一個、一些或全部Real Application Cluster 節點並行運行。
只要語句得到優化和並行化,就可以知道所有後續的並行子任務。原始進程變為查詢協調器;並行處理服務器(PX 服務器)從一個或多個節點上的並行處理服務器的公用緩沖池得到分配,並開始並行執行該操作。
與不共享體系結構相似,共享一切體系結構中的每個並行處理服務器在其個人數據子集上獨立工作。數據或功能在並行進程之間的傳送機制也與上述的Oracle不共享體系結構相似或者相同。確定請求的並行計劃之後,每個並行處理服務器都知道其數據集和任務,而進程間通信就像在不共享環境中一樣很少。
然而,與Oracle不共享體系結構不同,每個並行處理的SQL 語句不需要考慮任何物理數據庫布局限制就可以進行優化。這使得每個並行處理可以構造最佳的數據子集,從而提供與純不共享體系結構相比同等的,甚至在大多數情形下更好的可伸縮性和性能。只要有益,並行操作的後續步驟就會由一個並行處理服務器進行組合和處理,從而減少數據傳送或功能傳送的需求。