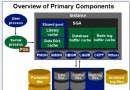
以下的文章主要介紹的是Oracle字符集相關的問題分析,如果你是Oracle字符集相關實際應用方面的新手,你就可以通過以下的文章對Oracle字符集是如何正確使用的方法有一個更好的了解,以下就是文章的詳細內容的介紹。
1、在UTF8環境下運行SQL語句報錯的問題:
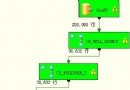
SQL*PLUS工具不提供編碼自動轉換的功能,當數據庫字符集為UTF8,客戶端的NLS_LANG如果也是UTF8,那麼在SQL*PLUS中運行SQL語句時,語句全是英文,不會出現問題,如果語句包含了中文或其它一些特殊字符,SQL語句運行時就會報錯。對於返回的含中文的結果,SQL*PLUS也會顯示亂碼。
造成此錯誤的原因在於當SQL語句中包含漢字等一些特殊字符時,由於這些字符的編碼屬於GBK,ORACLE沒有進行字符轉換,而是直接把SQL語句送到服務器上進行解析。此時服務器的Oracle字符集是UTF8,因此它按UTF8編碼格式對SQL語句中GBK編碼的字符解析時就會產生錯誤。
如果把客戶端的NLS_LANG設置為本地環境的字符集,如ZHS16GBK,此時可以直接在SQL*PLUS中輸入包含中文的SQL語句,Oracle在把SQL語句提交到服務器時會自動轉換成UTF8編碼格式,因此SQL語句可以正常運行。
對於英文字母,由於它在UTF8中的編碼數值采用的還是ASCII的編碼數值,因此英文字母可以直接使用而不需要轉換,這就是如果SQL語句或輸出結果全是英文時不會出現錯誤的原因。正確的做法是先把需要運行的SQL做成腳本文件,用代碼轉換工具把它轉換成UTF8編碼格式的文件。
(注意!XP中的記事本是提供了代碼轉換功能的,可以在保存文件或選擇文件另存為的時候,彈出的對話框最後一項,編碼,選擇UTF8,再保存,即可把文件轉換成UTF8編碼格式)。
完成後用IE打開這個腳本,選擇編碼-》UTF8,觀察此時SQL腳本是否含有亂碼或“?”符號。如果沒有,說明編碼格式已經是UTF8了,此時在SQL*PLUS中運行這個腳本就不會產生錯誤了。
運行結束後,輸出的結果中如果包含中文,需要把結果SPOOL輸出到一個文件中,然後用代碼轉換工具把這個結果文件由UTF8轉換成本地編碼格式,再用寫字板打開,才能看到正常顯示的漢字。由於IE具有代碼轉換功能,因此也可以不用代碼轉換工具,直接在IE中打開輸出的結果文件,選擇UTF8編碼,也能正常顯示含中文的結果文件。
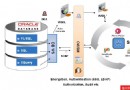
數據庫出現亂碼的問題:
數據庫出現亂碼的問題主要和客戶的本地化環境,客戶端NLS_LANG設置,服務器端的數據庫Oracle字符集設置這三者有關,如果它們的設置不一致或者某個設置錯誤,就會很容易出現亂碼,下面我們簡要介紹以下幾種情況:
1、數據庫字符集設置不當引起的亂碼:
例如:一個存儲簡體中文字符的數據庫,它的字符集選用了US7ASCII,當它的客戶端NLS_LANG也選用US7ASCII時,這個系統單獨使用是沒有問題的,因為兩者設置一致,因此Oracle不會進行字符集的轉換,客戶輸入的GBK碼被直接在數據庫中存儲起來,當查詢數據時,實際客戶端取出來的數據也是GBK的編碼,因此顯示也是正常的。
但當其它的系統需要從這個數據庫取數據,或者它的數據要EXP出來,IMP到其它數據庫時,問題就會開始出現了。其它系統的Oracle字符集一般是ZHS16GBK,或者其它系統客戶端的NLS_LANG設置為ZHS16GBK,此時必然會產生字符集的轉換。雖然數據庫字符集設置為US7ASCII,但我們知道,實際存儲的數據編碼是ZHS16GBK的。
可惜Oracle不會知道,它會把存儲的ZHS16GBK編碼數據當作US7ASCII編碼的數據,按照US7ASCII轉換成ZHS16GBK的轉換算法進行轉換,可以想象,這種情況下,亂碼的產生是必然的。
2、數據庫字符集與客戶端NLS_LANG設置不同引起的亂碼:
例如:對於一個需要存儲簡體文信息的數據庫來說,它的字符集設置和客戶端NLS_LANG設置一般可以使用ZHS16GBK編碼。但是如果數據庫字符集選用了UTF8的話,也是可以的,因為ZHS16GBK編碼屬於UTF8的子集。Oracle在數據庫與客戶端進行數據交換時自動進行編碼的轉換,在數據庫中實際存儲的也是UTF8編碼的數據。
此時其它數據庫和此數據庫也可以正常的進行數據交換,因為Oracle會自動進行數據的轉換。在實際使用中,遇到過繁體XP的字符集ZHT16MSWIN950轉換成AL32UTF8字符集時,一些特殊的字符和個別冷僻的漢字會變成亂碼。後來證實是XP需要安裝一個字庫補丁軟件,最後順利解決此問題。
3、客戶端NLS_LANG與本地化環境不同引起的亂碼:
一般情況下,客戶端NLS_LANG與本地化環境采用了不同的字符集會出現亂碼,除非本地化環境的字符集是客戶端NLS_LANG設置字符集的子集。如果把客戶端NLS_LANG設置為UTF8就屬於這種情況,由於目前還沒有可以直接使用UNICODE字符集的操作系統,因此客戶本地化環境使用的Oracle字符集只能是某種語言支持的字符集,它屬於UTF8的子集。下面我們就著重討論這種情況。
雖然目前WINDOWS的內核是支持UNICODE的,但是Windows並不支持直接顯示UNICODE編碼的字符,而且它並不知道目前的字符采用了何種字符集,所以默認情況下,它使用缺省的代碼頁來解釋字符。因此,對於其它類型的編碼,需要先進行轉換,變成系統目前的缺省代碼頁支持的字符集才能正常使用。
WINDOWS中的缺省代碼頁是由控制面板設置中的語言及區域的選擇所決定的,屬於客戶本地化的環境設置。簡體中文WINDOWS的字符編碼就是GBK,它的缺省代碼頁是936。對於其它非Windows的操作系統,我們可以把它們目前缺省使用的Oracle字符集作為用戶的本地化環境設置。
另外,我們使用的大部分工具,如寫字板,SQL*PLUS等,它們沒有提供編碼轉換功能,因此在客戶端直接輸入或查詢數據往往都會遇到亂碼的問題,必須由應用程序或一些工具去做編碼的轉換,才能保證正常的使用。