我們都知道Oracle是通過Redo來確保Oracle數據庫的相關事務能被重演,只有這樣才使出現故障之後,相關數據才可以被恢復。Redo對於Oracle數據庫來說至關重要。在數據庫中,Redo的功能主要通過3個組件來實現:
Redo Log Buffer、LGWR後台進程和Redo Log File(在歸檔模式下,Redo Log File最終會寫出為歸檔日志文件)。在Oracle的SGA中,存在一塊共享內存,稱為Redo Log Buffer,
Redo Log Buffer位於SGA之中,是一塊循環使用的內存區域,其中保存Oracle數據庫變更的相關信息。這些信息以重做條目(Redo EntrIEs)形式存儲(Redo Entries也經常被稱為Redo Records)。Redo Entries包含重構、重做數據庫變更的重要信息,這些變更包括INSERT、UPDATE、DELETE、CREATE、ALTER或者DROP等。在必要的時候Redo EntrIEs被用於數據庫恢復。
Redo EntrIEs的內容被Oracle數據庫進程從用戶的內存空間復制到SGA中的Redo Log Buffer之中。Redo EntrIEs在內存中占用連續的順序空間,由於Redo Log Buffer是循環使用的,Oracle通過一個後台進程LGWR不斷地把Redo Log Buffer的內容寫出到Redo Log File中。
當用戶在Buffer Cache中修改數據時,Oracle並不會立即將修改數據寫出到數據文件上,因為那樣做效率會很低,到目前為止,計算機系統中最繁忙的部分是磁盤的I/O操作,Oracle這樣做的目的是為了減少IO的次數,當修改過的數據達到一定數量之後,可以進行高效地批量寫出。
大部分傳統數據庫(當然包括Oracle)在處理數據修改時都遵循no-force-at-commit策略。也就是說,在提交時並不強制寫。那麼為了保證數據在數據庫發生故障時(例如斷電)可以恢復,Oracle引入了Redo機制,通過連續的、順序的日志條目的寫出將隨機的、分散的數據塊的寫出推延。
這個推延使得數據的寫出可以獲得批量效應的性能提升。同Redo Log Buffer類似,Redo Log File也是循環使用的,Oracle允許使用最少兩個日志組。缺省情況下,Oracle數據庫創建時會建立3個日志組。
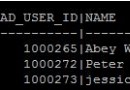
- SQL> select group#,members,status from v$log;
- GROUP# MEMBERS STATUS
- INACTIVE
- CURRENT
- INACTIVE
當一個日志文件寫滿之後,會切換到另外一個日志文件,這個切換過程稱為Log Switch。Log Switch會觸發一個檢查點,促使DBWR進程將寫滿的日志文件保護的變更數據寫回到數據庫。在檢查點完成之前,日志文件是不能夠被重用的。
由於Redo機制對於數據的保護,當數據庫發生故障時,Oracle就可以通過Redo重演進行數據恢復。那麼一個非常重要的問題是,恢復應該從何處開始呢?
如果讀取的Redo過多,那麼必然導致恢復的時間過長,在生產環境中,我們必需保證恢復時間要盡量得短。Oracle通過檢查點(Checkpoint)來縮減恢復時間。回顧一下第1章中所提到的內容:檢查點只是一個數據庫事件,它存在的根本意義在於減少恢復時間。
當檢查點發生時(此時的SCN被稱為Checkpoint SCN)Oracle會通知DBWR進程,把修改過的數據,也就是此Checkpoint SCN之前的髒數據(Dirty Buffer)從Buffer Cache寫入磁盤,在檢查點完成後CKPT進程會相應地更新控制文件和數據文件頭,記錄檢查點信息,標識變更。
在檢查點完成之後,此檢查點之前修改過的數據都已經寫回磁盤,重做日志文件中的相應重做記錄對於崩潰/實例恢復不再有用。如果此後數據庫崩潰,那麼恢復只需要從最後一次完成的檢查點開始恢復即可。如果Oracle數據庫運行在歸檔模式(所有生產數據庫,都建議運行在歸檔模式),日志文件在重用之前必須寫出到歸檔日志文件,歸檔日志在介質恢復時可以用來恢復數據庫故障。