Oracle邏輯結構優化其實就是通過增加、減少或者調整邏輯相關結構,來提高其應用的效率,以下就是通過對其基本表的設計以及索引、聚簇的討論來分析Oracle邏輯結構的優化。以下就是文章的主要內容的介紹。
基本表擴展
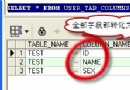
數據庫性能包括存儲空間需求量的大小和查詢響應時間的長短兩個方面。為了優化數據庫性能,需要對數據庫中的表進行規范化。一般來說,邏輯數據庫 設計滿足第三范式的表結構容易維護且基本滿足實際應用的要求。
所以,實際應用中一般都按照第三范式的標准進行規范化,從而保證了Oracle邏輯結構數據庫的一致性和完整性, 設計人員往往會設計過多的表間關聯,以盡可能地降低數據冗余。但在實際應用中這種做法有時不利於系統運行性能的優化:如過程從多表獲取數據時引發大量的連接操作,在需要部分數據時要掃描整個表等,這都消耗了磁盤的I/O 和CPU 時間。
為解決這一問題,在設計表時應同時考慮對某些表進行反規范化,方法有以下幾種:一是分割表。分割表可分為水平分割表和垂直分割表兩種:水平分割是按照行將一個表分割為多個表,這可以提高每個表的查詢速度,但查詢、更新時要選擇不同的表,統計時要匯總多個表,因此應用程序會更復雜。
垂直分割是對於 一個列很多的表,若某些列的訪問頻率遠遠高於其它列,就可以將主鍵和這些列作為一個表,將主鍵和其它列作為另外一個表。通過減少列的寬度,增加了每個數據頁的行數,一次I/O就可以掃描更多的行(同理於內存的頁式訪問),從而提高了訪問每一個表的速度。
但是由於造成了多表連接,所以應該在同時查詢或更新不同分割表中的列的情況比較 少的情況下使用。二是保留冗余列。當兩個或多個表在查詢中經常需要連接時,可以在其中一個表上增加若干冗余的列,以避免表之間的連接過於頻繁,一般在冗余列的數據不經常變動的情況下使用。
三是增加派生列。派生列是由表中的其它多個列的計算所得,增加派生列可以減少統計運算,在數據匯總時可以大大縮短運算時間(通過周期性結轉豈不是更好?)。
因此,在數據庫的設計中,數據應當按兩種類別進行組織:頻繁訪問的數據和頻繁修改的數據。對於頻繁訪問但是不頻繁修改的數據,內部設計應當物理不規范化。對於頻繁修改但並不頻繁訪問的數據,內部設計應當物理規范化。
有時還需將規范化的表作為Oracle邏輯結構數據庫設計的基礎,然後再根據整個應用系統的需要, 物理地非規范化數據。規范與反規范都是建立在實際的操作基礎之上的約束,脫離了實際兩者都沒有意義。只有把兩者合理地結合在一起,才能相互補充,發揮各自的優點。