以下的文章主要講述的是Oracle in 與 not in在實際應用中的區別,我們大家都知道在很多相關的軟件系統中,其系統的實際性能在很大程度上是由數據庫的相關性能所決定。以前也曾經做過很多次關於性能方面的各種測試。
特別是關於Oracle的,我想到也應該記錄下來一部分,為大家共享。
事情發生在我們的系統從sqlserver移植到Oracle,用戶在一個查詢的操作上等待的時間無法忍受了,我們關於這個查詢的處理與原來的方式一下,難道sqlserver 同Oracle有什麼地方不一樣麼,讓我們來看看Oracle有什麼地方有問題,或者是我們使用的有問題?
業務問題大概可以這樣描述,一個父表,一個子表,查詢的結果是找到子表中沒有使用父表id的記錄,這種情況估計很多系統都會牽涉得到。讓我們來舉一個例子:
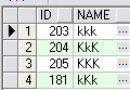
表一: 父表 parent
表二: 子表 childen
父表存儲父親,子表存儲孩子,然後通過pid和父表關聯,查詢需要的結果是找到尚未有孩子的父親。
我們來看一下查詢語句的寫法:
- select * from parent where id not in (select pid from childen)
這種標准的寫法在子表存在50萬條的記錄的時候,查詢時間超過了10秒,遠遠大於原來的SQL Server服務器的一秒。我在解決的時候想到了一個方法:
- select * from parent where id in
- ( select id from parent minus select pid from childen )
正常理解下,這個語句應該更加費時,但是事實完全出乎意料,這條語句不僅僅在子表存在大量記錄的情況下速度良好,在子表少量數據的情況下速度也非常的好,基本在1秒內完成。
這個結果可以很明顯的證明Oracle 在子查詢的內部處理的時候,使用 Oracle in 和 not in 的巨大區別,希望用到這種方式的用戶注意,也期待有人解釋其中的問題。