如果按照本文方法優化後數據庫執行時間由191秒縮減到189秒,也就是單位時間少1%的能量消耗。那麼在一天裡將減少0.03kw電能消耗,約合0.023kg二氧化碳排放,按我們的計算是一天減少0.05棵樹二氧化碳吸收量。
本文引用一套實驗室信息管理系統(LIS)使用的數據庫,假設我們要查詢2008年11月做檢驗的患者記錄,條件是大於80歲,姓周的患者,最終結果按檢查日期進行倒序排列。要使用的表有三個:
◆lis_report:報告主表,我們要用到的字段包括i_checkno(檢查號),d_checkdate(檢查日期),i_patIEntid(患者ID);
◆comm_patient:患者信息表,我們要用到的字段包括i_patIEntid(患者ID),s_name(患者姓名),s_code(患者住院號),i_age(患者年齡),i_dept(患者所在病區);
◆lis_code_dept:病區信息表,我們要用到的字段包括i_id(病區ID,主鍵,與comm_patIEnt中的i_dept關聯),s_name(病區名)。
最終我們構造的SQL如下:
- select a.i_checkno, a.d_checkdate, b.s_name, b.s_code, b.i_age, c.s_name
- from lis_report a
- inner join comm_patIEnt b on a.i_patientid = b.i_patIEntid
- inner join lis_code_dept c on b.i_dept = c.i_id
- where a.d_checkdate > '2008-11-01'
- and a.d_checkdate < '2008-11-30'
- and b.i_age>=80
- and b.s_name like '周%'
- order by a.d_checkdate desc
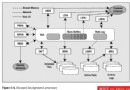
我們的SQL使用的這三張表除了創建主鍵時自動創建的索引外,均未創建其它索引,下圖是無索引時的執行計劃。
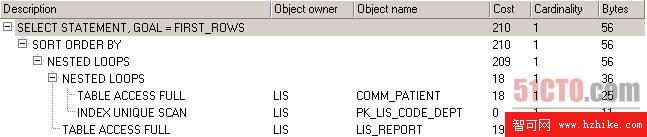
圖 1 無索引時的執行計劃
從圖1可以看出,表comm_patient和lis_report都使用了全表掃描,comm_patient全表掃描的成本是18,lis_report全表掃描的成本是191,只有表lis_code_dept因關聯時使用的是其主鍵,因此這裡使用了主鍵索引,從而避免了全表掃描,它的成本是0。我們知道提高查詢性能的目標之一就是消滅掉全表掃描,因此我們應該給表comm_patient和lis_report加上適當的索引,在SQL代碼的where子句中,對comm_patient表,我們引用了i_age和s_name字段,對lis_report表,我們引用了d_checkdate字段,通常給這些條件中引用的字段加上索引會提高查詢速度,我們先給comm_patIEnt的i_gae字段加上索引,下面是對應的執行計劃。
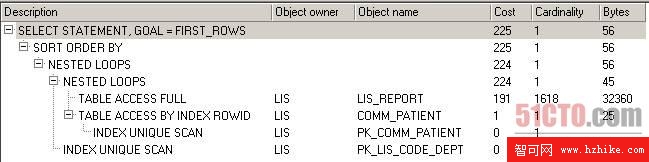
圖 2 給comm_patIEnt的i_age加上索引後的執行計劃
從圖2可以看出,表comm_patIEnt的全表掃描消失了,取而代之的是索引唯一性掃描,成本從18一下子降低到1了,注意這裡並未使用我們給i_age增加的索引,但卻靠它觸發了使用表主鍵對應的索引。但表lis_report仍然是全表掃描,由於where子句中引用了該表的d_checkdate字段,因此我們給該字段加上索引看看效果。
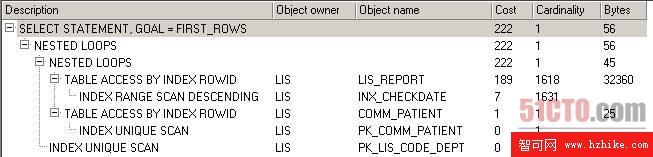
圖 3 給lis_report的d_checkdate字段加上索引後的執行計劃
從上圖可以看出,表lis_report的全表掃描消失了,取而代之的是索引范圍降序掃描(INDEX RANGE SCAN DESCENDING),成本也從191下降到189。注意這裡的索引范圍降序掃描的來歷,因為我的where子句中引用d_checkdate是介於2008-11-01至2008-11-30的一個范圍,這時引用的這種字段上建立的索引通常都是執行范圍掃描,因為這種條件返回的值往往不止一行。使用降序掃描的原因是order by子句使用了降序排序,如果我們將SQL代碼中的“order by a.d_checkdate desc”改為“order by a.d_checkdate”,則變為索引范圍掃描(INDEX RANGE SCAN)。
至此我們全部消除了全表掃描,我們看到加上索引後,查詢執行的成本開銷也有所降低,因為數據庫表中的記錄數不大,因此效果不太明顯,如果有上百萬條記錄則會更直觀。
雖然索引能提高查詢性能,但索引也不能濫用,一是因為索引會降低寫入性能,二是索引過多給索引管理帶來麻煩,有些索引根本就沒有使用,這樣的索引只會帶來負面影響,基於這些弊端的考慮,在設計數據庫結構時應綜合考慮表的使用頻率(使用次數越多越應重點考慮是否建立索引),表中字段的使用頻率(字段使用次數越多越應建立索引),字段類型(數值型字段越應建立索引),值的唯一性(最應建立索引的字段),值的重復性(值重復度越高,建立索引的必要性越低),值是否可為空(允許為空的字段一般不建立索引),表中記錄數(記錄數很少時一般不宜建立索引),表是讀操作多一些還是寫操作多一些(讀操作越多的表越應建立索引,寫操作越多的表越應避免建立索引)等,創建索引的一般原則是:在大表的常用且值重復幾率小的字段上創建索引。
數據庫性能優化是無止境的,無論哪種優化技術只是一種手段,但最重要的不是技術,而是思想,掌握了索引優化技術僅僅剛入門,只有融會貫通,舉一反三才能成為高手。