導讀:當數據庫管理員不知道該如何對表進行分區時,但確實有分區的必要時,可以使用散列分區。不過筆者需要提醒的是,散列分區其有一個重大的限制。在使用散列分區的時候,僅僅支持本地索引,而不支持其他的索引方式。
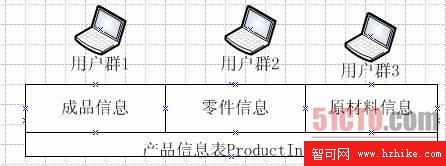
現在某家企業的Oracle數據庫中有一張產品信息表。這張表中的記錄已經超過了500萬條。其中成品信息大概30萬條。零件記錄有300萬條左右。剩余的都是包裝信息。數據庫工程師通過相關的分析與監測,用戶訪問這張表的時候,會有嚴重的等待現象。這主要是因為這張表中的數據存放在同一塊硬盤上。當不同的用戶並發訪問這張表時,會因為磁盤I/O性能的瓶頸,而導致等待。如下圖所示。當各位讀者遇到這種情況,該如何采取措施來優化性能呢?筆者這裡的建議是采用Oracle分區表減少磁盤的I/O沖突,改善數據庫的性能。
一、分區表的原理與優勢。
分區表對於提高大表的訪問性能會有很大的幫助。如上圖所示,可以將一張產品信息表分按產品類別分為三個部分,分別為成品信息、零件信息和原材料信息。然後將這三部分對應一個單獨的分區,並將它們存放在不同的硬盤上。此時當不同的用戶訪問不同的信息時,就可以有效的降低磁盤的I/O沖突。即使是同一個用戶,需要同時訪問這三部分信息,如產品的物料清單時,由於其分別從不同的硬盤中讀取數據,為此也可以明顯的降低磁盤I/O沖突。
所以分區的基本原理就是通過訪問一個表或者索引的較小片斷,而不是訪問整個表和索引,以提高數據庫的性能。當然這有一個前提條件,需要將一個表的不同分區放置在不同的磁盤上,此時磁盤整體的吞吐量就會成倍上升。
采取分區,不僅可以提高用戶訪問時的性能,而且還可以提高備份時的靈活性。如上面這個例子,將產品信息根據其類別分為不同的區,並將它們保存在不同的硬盤上。此時就可以對各自的分區進行單獨的備份。如最近因為國家環保的要求,原材料信息進行了大規模的調整。此時就可以對原材料信息所在的分區數據進行單獨的備份。這不僅可以減少備份的時間,而且可以降低備份作業過程中出現的I/O沖突問題。
一般來說,分區表的優勢有一個前提,就是需要將分區數據放置在不同的磁盤上。如果不這麼做的話,那麼分區往往很難起到降低磁盤I/O的效果。所以為了最大程度的降低一個大表的磁盤I/O(特別是經常會有並發行的訪問),此時應該將表分割到多個分區上。然後再將這些分區存放在不同的磁盤上。
二、分區表模式的選擇。
那麼該如何對表進行分區呢?這又是一個比較關鍵的問題。根據經驗,筆者認為要讓分區取得更好的效果,分區表模式的選擇至關重要。也就是說,按什麼內容對表進行分區管理。有時候,先同的數據,采取不同的分區表模式,往往會有不同的效果。在下面的內容中,筆者會結合企業實際應用的情景,對分區表模式的選擇進行舉例。希望這些內容能夠幫助各位讀者,更好的維護分區表。
第一種模式:按行來進行分區。
上面這個例子中,筆者談到有一張產品信息表,其包括成品信息、零件信息和原材料信息。當這張表的記錄比較多,並且當用戶訪問這張表時已經出現了嚴重的I/O沖突的時候,則就可以根據行記錄來進行分區。如在產品信息表中有一個產品類別的字段。數據庫管理員就可以根據這個字段對標進行分區。具體的分區方法也比較簡單。在建立表的時候,在產品類別字段後加上Partion關鍵字,然後指定按字段的內容進行分區。這個操作比較簡單,筆者就不過多展開了。筆者這裡需要強調的是,分區完之後一定要將數據存放在不同的磁盤上,即不同的表空間。否則的話,不能夠起到改善磁盤I/O的效果。
第二種模式:按列來進行分區。
在實際工作中,還有這麼一種情況。如現在有一張員工信息表。這這張表中除了包含員工的基本信息,如身份證號碼、姓名、籍貫等內容,還包括員工的身份證復印件或者照片等圖片信息。大家都知道,圖片信息的數據流量是很大的。有可能一張身份證復印件的數據流量相當於幾千條的員工基本信息。而且,當用戶訪問員工信息表的時候,並不是每個時候都需要查看身份證復印件。大部分時候他們可能只是查詢員工的聯系方式或者住址等等。另外,一般身份證復印件等照片不會隨意更改,而員工的聯系方式或這住址等等,則更改比較頻繁。此時如果需要更改員工信息,卻將不需要更改的員工身份證復印件也查詢出來,顯然那這會加重磁盤的I/O沖突。
當企業存在這種情況時,也可以對這個表進行分區。此時分區並不是對行進行分區,而是對列進行分區。如可以將身份證復印件信息或者照片信息分為一個獨立的分區,並將其保存在另外一個硬盤上。這麼做,能夠帶來如下的好處。
一是在數據訪問時,可以指定是否需要查詢身份證信息所在的分區。在查詢員工信息的時候,在語句中可以指定從哪個分區中查詢信息。當用戶平時只是查詢員工的聯系方式或者住址時,就不需要訪問身份證復印件所在的分區。如可以使用如下語句查詢:
Select * from ad_user partition(uinfo) –假設員工的基本信息存放在分區Unifo中。
在查詢語句中,使用Partition關鍵字可以指定其查詢的是哪個分區。如果不特指的話,則系統會查詢這個表所對應的全部分區。而指定的話,就只訪問某個特定分區的內容。上面這條語句,就只讀取Uinfo分區中的信息。而不會讀取身份證復印件等相關信息。如此的話,就可以降低磁盤的I/O沖突,減少不必要的數據流量,提高查詢的性能。
二是方便對數據的備份。根據使用習慣,一般身份證復印件或者員工照片等信息不怎麼會更改。為此對這些數據的備份頻率可以比較低一點。況且這些信息的容量往往會很大。如果經常對其進行備份,顯然會增加磁盤的I/O負擔。而對於員工的聯系信息或者住址等等,其變化的頻率就會高許多。對這些信息就需要進行經常性的備份。對大表進行分區管理,還有一個很大的優勢就在於可以對各個分區中的數據采取獨立的備份。為此就可以對身份證復印件所在的分區進行單獨的備份,如一個月或者有大的變動時進行備份。而對於其他的信息則可以每天進行備份。這就可以實現在性能與安全方面的均衡。一般來說,在訪問某個表時,如果經常需要訪問的信息只是特定的幾列,而不需要訪問的信息容量比較大,此時就可以采用按列分區的模式。在這種情況下,用戶就可以在查看某個分區內容的時候避免訪問其他分區。同時還可以在不妨礙其它分區的情況下對某個分區的數據進行獨立的備份。
第三種分區模式:散列分區。
有時候某個表可能沒有明顯的分區特征,即不符合上面提到的這些情況。但是表中的記錄又非常的多。在這種情況下,也有必要進行分區。不過此時我們可以讓系統進行隨機的分區。這種分區模式就叫做散列分區。通常情況下,為了提高散列分區的效果,即得到一個比較均勻的分布,往往可以將2的N次方指定為散列分區數。一般來說,N越大,其分布的越均勻。
也就是說,當數據庫管理員不知道該如何對表進行分區時,但確實有分區的必要時,可以使用散列分區。不過筆者需要提醒的是,散列分區其有一個重大的限制。在使用散列分區的時候,僅僅支持本地索引,而不支持其他的索引方式。這一點需要特別的注意。在實際工作中不能夠因為采取了散列分區,而降低或者取消了索引。這往往是得不償失的,不可行。
希望通過上文的學習,大家能夠掌握好利用Oracle分區表來減少磁盤I/O沖突的知識,便於大家在以後的工作中靈活運用。