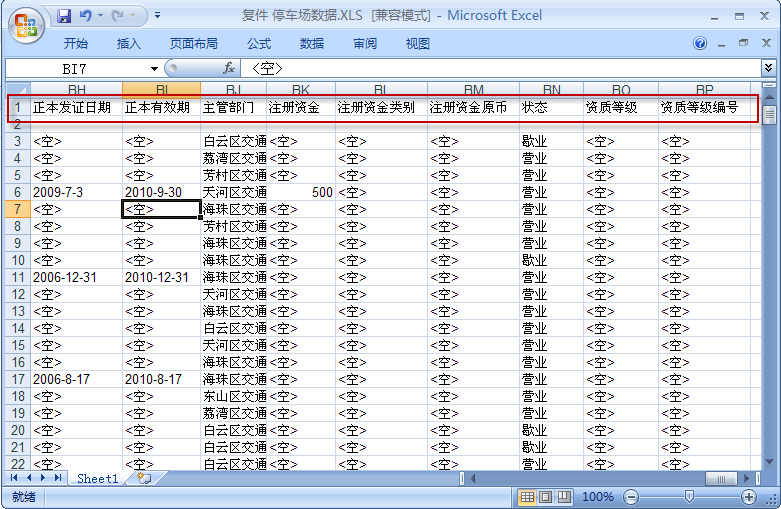
當表的數據量大些時,對表作分析之後,使用count(1)還要比使用count(*)用時多了!從執行計劃來看,count(1)和count(*)的效果是一樣的。
但是在表做過分析之後,count(1)會比count(*)的用時少些(1w以內數據量),不過差不了多少。
這個也與表的記錄數多少有關!如果1w以外的數據量,做過表分析之後,反而count(1)的用時比count(*)多了。另外,當數據量達到10w多的時候,使用count(1)要比使用count(*)的用時稍微少點!如果你的數據表沒有主鍵,那麼count(1)比count(*)快
如果有主鍵的話,那主鍵(聯合主鍵)作為count的條件也比count(*)要快
如果你的表只有一個字段的話那count(*)就是最快的啦
count(*) count(1) 兩者比較。主要還是要count(1)所相對應的數據字段。
如果count(1)是聚索引,id,那肯定是count(1)快。但是差的很小的。
因為count(*),自動會優化指定到那一個字段。所以沒必要去count(1),用count(*),sql會幫你完成優化的
因此:count(1)和count(*)基本沒有差別!sql調優,主要是考慮降低:consistent gets和physical reads的數量。
如果null參與聚集運算,則除count(*)之外其它聚集函數都忽略null.
如:select count(DD) from table ---結果是1
也可以Tom的網站討論的結果:
http://asktom.Oracle.com/pls/asktom/f?p=100:11:0::::P11_QUESTION_ID:1156151916789
結論是不相上下。
個人認為count(*)好些。