Oracle的性能分析在過去的20年裡已經走了很長的一段路。這裡首先提出“僅僅添加更多的資源”的方式,然後涉及比率分析,最後是等待事件分析的出現。但是那些方式都不完整或者足夠廣泛,所以在2001年我發表了一篇名為《Oracle響應時間分析(RTA)》的論文。RTA的文章同時提出並且詳細描述了響應時間中的兩個元素:服務時間和排隊時間。有關RTA的一個更加微妙的方面就是理解服務時間和排隊時間之間的關系,以及它們與操作系統之間是如何聯系的。
用戶感覺到的響應時間是許多個相關系統的結果。Oracle服務器只是這些系統中的一個。花費在每個系統上的時間都可以劃分為服務時間和排隊時間。我們只能把所有的服務時間和所有的排隊時間加起來,來判斷最終用戶的響應時間。但是在現實生活中,有時候這些努力相對於結果來說並不值得……不是說完成起來極端困難。但是肯定值得我們去做的最小的努力就是從Oracle的角度獲取服務時間和排隊時間。此外,我們還可以獲得有關它如何與數據庫服務器的CPU子系統相聯系的細節。
讓我們看看基本的基於Oracle的響應時間公式:
Rt = 終端用戶響應時間 = Ts + Tw
Ts = 服務時間 = CPU 時間= Oracle 內核代碼執行時間
Tw = 排隊時間 = ORAt + TIERt
ORAt = Oracle等待時間 (包括從服務器進程到Oracle客戶端進程的時間,以及Oracle客戶端進程的時間)
TIERt = 從Oracle客戶端進程到終端用戶的時間。其中包括網絡服務器、網絡時間、浏覽器時間等。
從分析響應時間中我們可以穴道很多東西,其中一件就是服務時間有限,但是等待時間卻無限。每個CPU子系統都有一個最大的固定的可以提供的CPU能力。如果你的機器是一個CPU的,這個機器就可以提供每分鐘60個CPU秒的最大量。如果你的機器中有10個CPU,它就可以提供每分鐘600個CPU秒。這個環境對排隊時間來說絕對是不同的。
排隊時間是不固定的,並且只被工作負載所限制。如果工作負荷相對比較小,排隊時間就可能接近於0。但是當工作負載不斷增加,排隊時間就會達到無限——它沒有限制。
有關排隊時間無限的說法提出了兩個我們需要思考的概念。首先,如果Oracle消耗了所有可用的CPU,那麼要求更多的CPU就需要增加服務時間,同時也有可能增加Oracle等待時間。結果就是響應時間的增加。這是不好的,非常不好。這意味著我們的解決方案需要仔細權衡它們是如何影響CPU子系統的。(這個概念在我的新論文《Oracle等待接口詳解》中有詳細的解釋。)第二個概念就是我們現在有另一種方式來查看一個非常動態的系統。這不僅可以幫助我們理解系統,還可以讓我們幫助其他人來理解潛在的非常復雜的基於Oracle的系統。
例如,考慮下面的圖。數據是從實際生活中的Oracle系統上收集到的。每個小時、響應時間組件都會被收集並且總結。排隊時間從v$system_event中收集,服務時間是從v$sysstat中收集。通過查看這幅圖,如果性能是糟糕的,所有的非Oracle服務器體系組件都表明不是瓶頸,瓶頸就應該是在Oracle服務器中了。通過以下的圖,我們可以推斷,IO子系統有很嚴重的瓶頸,或者鎖定/阻塞問題。也許2200左右就是CPU的瓶頸,但是剩余的時間肯定是IO瓶頸或者鎖定/阻塞問題。
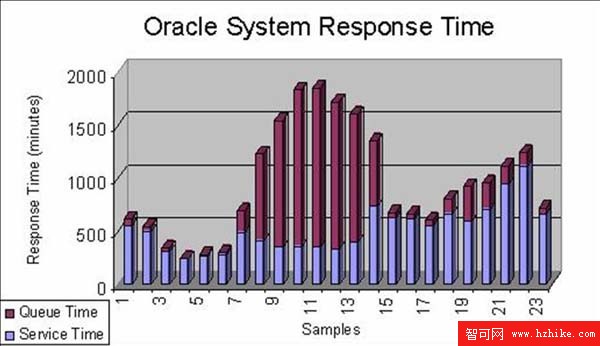
讓我們更仔細地看一下。問題都集中在可用的Oracle消耗的操作系統的CPU能力百分比。仔細查看上述的圖形。我們從CPU子系統開始。因為在一個小時裡面大概消耗了大約1000分鐘的最大CPU時間,我們知道那肯定至少有17個CPU。最糟糕的情況就是使用的CPU資源相當於可用的CPU資源。這一點可以結合從上述圖形中的數字得到:
可用的CPU = 使用的CPU
X CPUs * 60 分鐘/小時 = 1000分鐘/小時
X CPUs = 1000分鐘/小時 / 60分鐘/小時
X CPUs = 16.67
所以,數據庫服務器上至少有17個CPU。如果我們從對操作系統的監控中發現,CPU的利用率在50%左右,大概是2200,我們還可以推斷出大概有34個CPU(16.67 X 2)。
現在讓我們把信息放在一起,這樣它們就有用了。請注意在午餐時間附近,Oracle每小時消耗的CPU時間達到1000分鐘。我們知道服務器可以每小時提供1000個CPU分鐘,在午餐時間,它提供的時間少於每小時500個CPU分鐘,用戶並不滿意這樣的性能。因此,我們可以推斷出排隊時間(例如,Oracle等待事件)並不是CPU相關的, 而是與I/O有關的,或者是相關鎖定/阻塞(例如排隊等待)。有力的信息!
我們知道理解和應用Oracle響應時間組件可以增加我們的性能威力。但是理解了Oracle服務時間是如何與CPU的操作系統相關聯的,就是另一個級別的了。在沒有理解Oracle從操作系統中消耗的可用的CPU的百分比的時候,我們就無法了解是否有足夠的CPU可用。對CPU百分比的了解可以讓我們的性能診斷更加准確,可以得出更加有力的解決方案。理解了時間的有限和無限,不僅僅可以幫助你,還有你的同事,以及你需要影響的人們。他們越好的理解這個情況,他們就越同意你的行動建議。換句話說,它使得你的性能分析更加有力,構建了信任。這也是所有的數據庫管理員們都用得最多的。