分區更改跟蹤:不需要 MV 日志
要了解此增強功能,首先必須了解物化視圖 (MV) 刷新過程中的分區修整概念。
假設基於列 ACC_MGR_ID 對表 ACCOUNTS 進行了分區,每個 ACC_MGR_ID 值一個分區。您根據 ACCOUNTS 創建了一個名為 ACC_VIEW 的 MV,該 MV 也根據列 ACC_MGR_ID 進行了分區,每個 ACC_MGR_ID 一個分區,如下圖所示:
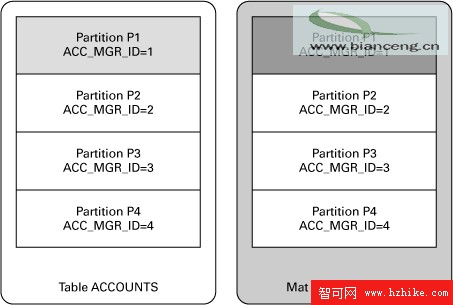
假設已經更新了表 ACCOUNTS 中的記錄,但只在分區 P1 中進行了此更新。要快速刷新此 MV,您只需刷新分區 P1 而非整個表,這裡正是與 ACC_MGR_ID 相關的數據所在的分區。Oracle 自動執行此任務,通過一個名為分區更改跟蹤 (PCT) 的特性跟蹤對分區的更改。但有一個問題需稍加注意:要在快速刷新的過程中啟用 PCT,必須創建 MV 日志,當表中的行發生變化會填充這些日志。發出刷新命令後,刷新進程將讀取 MV 日志以識別這些更改。
不用說,該要求增加了操作的總執行時間。此外,附加的插入操作將消耗 CPU 周期和 I/O 帶寬。
幸好,在 Oracle 數據庫 10g 第 2 版中,PCT 不需要 MV 日志即可工作。讓我們看一看它的作用方式。首先,確認表 ACCOUNTS 中沒有 MV 日志。SQL> select *
2 from dba_mvIEw_logs
3 where master = 'ACCOUNTS';
no rows selected
現在,更新該表中的某個記錄。update accounts set last_name = '...'
where acc_mgr_id = 3;
該記錄位於分區 P3 中。
現在,您就可以刷新此 MV 了。但首先記錄表 ACCOUNTS 所有段的段級統計信息。稍後,您將使用這些統計信息了解使用了哪些段。select SUBOBJECT_NAME, value from v$segment_statistics
where owner = 'ARUP'
and OBJECT_NAME = 'ACCOUNTS'
and STATISTIC_NAME = 'logical reads'
order by SUBOBJECT_NAME
/
SUBOBJECT_NAME VALUE
------------------------------ ----------
P1 8320
P10 8624
P2 12112
P3 11856
P4 8800
P5 7904
P6 8256
P7 8016
P8 8272
P9 7840
PMAX 256
11 rows selected.
使用快速刷新刷新物化視圖 ACC_VIEW。
execute dbms_mview.refresh('ACC_VIEW','F')
'F' 參數指示快速刷新。但如果表沒有 MV 日志,它是否可以起作用?
刷新完成後,再次檢查表 ACCOUNTS 的段統計信息。結果如下所示:
SUBOBJECT_NAME VALUE
------------------------------ ----------
P1 8320
P10 8624
P2 12112
P3 14656
P4 8800
P5 7904
P6 8256
P7 8016
P8 8272
P9 7840
PMAX 256
這些段統計信息顯示了在一個邏輯讀取過程中選擇的段。由於這些統計信息是累積的,因此您必須查看值(而非絕對值)中的更改。如果仔細查看以上值,您便會發現只有分區 P3 的值發生了變化。因此,在刷新過程中只選擇了分區 P3 而非整個表,確認 PCT 能否在表即使沒有 MV 日志的情況下工作。
即使在基表沒有 MV 日志的情況下也可以快速刷新 MV 的能力是一個強大而有用的特性,從而允許您可以在已分區的 MV 中執行快速刷新而不會增加性能開銷。我認為,該特性是 Oracle 數據庫 10g 第 2 版中最有用的數據倉庫增強功能。
使用多個 MV 進行查詢重寫
Oracle8i 中引入的查詢重寫特性在數據倉庫開發人員和 DBA 中轟動一時。從本質上而言,它將用戶查詢重寫為從 MV 而非表中進行選擇以利用現成的摘要。例如,請考慮以下一家大型連鎖酒店的數據庫中的三個表。
SQL> DESC HOTELS
Name Null?Type
----------------------------------------- -------- -------------
HOTEL_ID NOT NULL NUMBER(10)
CITY VARCHAR2(20)
STATE CHAR(2)
MANAGER_NAME VARCHAR2(20)
RATE_CLASS CHAR(2)
SQL> DESC RESERVATIONS
Name Null?Type
----------------------------------------- -------- -------------
RESV_ID NOT NULL NUMBER(10)
HOTEL_ID NUMBER(10)
CUST_NAME VARCHAR2(20)
START_DATE DATE
END_DATE DATE
RATE NUMBER(10)
SQL> DESC TRANS
Name Null?Type
----------------------------------------- -------- -------------
TRANS_ID NOT NULL NUMBER(10)
RESV_ID NOT NULL NUMBER(10)
TRANS_DATE DATE
ACTUAL_RATE NUMBER(10)
表 HOTELS 保存酒店的相關信息。當顧客預訂酒店時,將在表 RESERVATIONS(包含房間價格報價)中創建一個記錄。當顧客在酒店結帳時,將在另一個表 TRANS 中記錄現金交易。
但在結帳前,酒店可能決定根據訂房情況、升級、優惠等因素向顧客提供不同的房價。因此,最終的房價可能與預訂時的報價不同,而且可以每天都各不相同。為正確記錄這些價格變化,表 TRANS 有一行專門用來保存每天的房價信息。
為縮短查詢響應時間,您可能決定根據用戶發出的不同查詢構建 MV,如:create materialized vIEw mv_hotel_resv
refresh complete
enable query rewrite
as
select city, resv_id, cust_name
from hotels h, reservations r
where r.hotel_id = h.hotel_id;
和create materialized vIEw mv_actual_sales
refresh complete
enable query rewrite
as
select resv_id, sum(actual_rate) from trans group by resv_id;
因此,如果設置了某些參數(如 query_rewrite_enabled = true),則類似如下所示的查詢
select city, cust_name
from hotels h, reservations r
where r.hotel_id = h.hotel_id;
將重寫為select city, cust_name
from mv_hotel_resv;
您可以通過運行該查詢並啟用自動跟蹤來確認 MV。
SQL> set autot traceonly explain
SQL> select city, cust_name
2> from hotels h, reservations r
3> where r.hotel_id = h.hotel_id;
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=3 Card=80 Bytes=2480)
1 0 MAT_VIEW Access (FULL) OF 'MV_HOTEL_RESV' (MAT_VIEW) (Cost=3 Card=80 Bytes=2480)
注意,查詢是如何從物化視圖 MV_HOTEL_RESV 而非表 HOTELS 和 RESERVATIONS 中進行選擇的。這正是您所需要的。同樣,當您編寫一個查詢來匯總每個預訂編號的實際價格時,將使用物化視圖 MV_ACTUAL_SALES 而非表 TRANS。
我們來采用一個不同的查詢。如果要查明每個城市的實際銷售額,則將發出
select city, sum(actual_rate)
from hotels h, reservations r, trans t
where t.resv_id = r.resv_id
and r.hotel_id = h.hotel_id
group by city;
注意此查詢結構:從 MV_ACTUAL_SALES 中,您可以獲得 RESV_ID 和預訂的總銷售額。從 MV_HOTEL_RESV 中,您可以獲得 CITY 和 RESV_ID。
您能將這兩個 MV 連接在一起嗎?當然可以,但在 Oracle 數據庫 10g 第 2 版之前,查詢重寫機制只使用兩個 MV 中的一個(而非兩個)自動重寫用戶查詢。
以下是 Oracle9i 數據庫中的執行計劃輸出。您可以看到,只使用了 MV_HOTEL_RESV 和 TRANS 的整表掃描。
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=8 Card=6 Bytes=120)
1 0 SORT (GROUP BY) (Cost=8 Card=6 Bytes=120)
2 1 HASH JOIN (Cost=7 Card=516 Bytes=10320)
3 2 MAT_VIEW REWRITE Access (FULL) OF 'MV_HOTEL_RESV' (MAT_VIEW REWRITE)
(Cost=3 Card=80 Bytes=1040)
4 2 TABLE Access (FULL) OF 'TRANS' (TABLE)
(Cost=3 Card=516 Bytes=3612)
即使 MV 可用,該方法也將生成一個非最優的執行計劃。唯一的救濟就是創建另一個將所有三個表連接在一起的 MV。但該方法將導致 MV 的增多,從而大大增加刷新 MV 所需的時間。
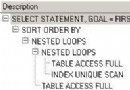
Oracle 數據庫 10g 第 2 版解決了此問題。現在,以上查詢將重寫為使用兩個 MV,如執行計劃中所示。
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=8 Card=6 Bytes=120)
1 0 SORT (GROUP BY) (Cost=8 Card=6 Bytes=120)
2 1 HASH JOIN (Cost=7 Card=80 Bytes=1600)
3 2 MAT_VIEW REWRITE Access (FULL) OF 'MV_ACTUAL_SALES' (MAT_VIEW REWRITE)
(Cost=3 Card=80 Bytes=560)
4 2 MAT_VIEW REWRITE Access (FULL) OF 'MV_HOTEL_RESV' (MAT_VIEW REWRITE)
(Cost=3 Card=80 Bytes=1040)
注意,該執行計劃是如何只使用了 MV 而未使用任何其他基表的。
該增強功能在數據倉庫中具有顯著的優點,這是因為您不必為每個可能的查詢創建和刷新 MV。相反,你可以在關鍵地方創建幾個沒有太多連接和聚合的 MV,Oracle 將使用它們來重寫查詢。
通過備份實現可傳輸表空間
Oracle8i 中引入的可傳輸表空間為實現更快的跨數據庫數據傳輸提供了迫切需要的支持。使用此特性,您可以只導出表空間的元數據、傳輸數據文件並將轉儲文件導出到目標數據庫主機以及導入元數據以將表空間“插入”到目標數據庫中。該表空間中的數據在目標數據庫中隨即可用。該方法解決了數據倉庫中曾一度存在的一個很棘手的問題:快速、高效地跨數據庫移動數據。
但在 OLTP 數據庫中,該條件通常是不可能存在的,因此傳輸表空間也是不可能的。如果 OLTP 數據庫是數據倉庫的數據源,則您可能始終無法使用可傳輸表空間加載它。
在 Oracle 數據庫 10g 第 2 版中,可以傳輸表空間並從另一個數據源(即備份)中插入它。例如,如果要傳輸表空間 ACCDATA,則可以發出 RMAN 命令
RMAN> transport tablespace accdata
2> TABLESPACE DESTINATION = '/home/Oracle'
3> auxiliary destination = '/home/Oracle';
該命令在位置 /home/Oracle 中創建一個輔助實例,並從其中的備份恢復文件。此輔助實例的名稱是隨機生成的。創建實例後,該過程將基於目錄創建一個目錄對象,並恢復表空間 ACCDATA(我們正在傳輸的表空間)的文件 - 所有操作均自動完成,您不必發出任何命令!
目錄 /home/Oracle 將包含表空間 ACCDATA 的所有數據文件、表空間元數據的轉儲文件以及腳本 impscrpt.sql(最重要的)。該腳本包含將此表空間插入目標表空間所必需的所有命令。該表空間並非由 impdp 命令進行傳輸,而是通過對 dbms_streams_tablespace_adm.attach_tablespaces 程序包的調用進行傳輸。可以在該腳本中找到所有必要的命令。
您可能會問,如果出現錯誤該怎麼辦?這種情況下,可以輕松地進行診斷。首先,該輔助實例在 $Oracle_HOME/rdbms/log 中創建警報日志文件,以便您可以檢查該日志以查明潛在的問題。其次,在提供 RMAN 命令時,您可以通過發出 RMAN 命令(該命令將所有輸出置於文件 tts.log 中)將命令和輸出重定向到日志文件rman target=/ log=tts.log
然後,您便可以檢查該文件來查明故障的確切原因。
最後,將把這些文件恢復到 /home/Oracle 的 TSPITR_<SourceSID>_<AuxSID> 目錄中。例如,如果主數據庫的 SID 為 ACCT,RMAN 創建的輔助實例的 SID 為 KYED,則目錄名為 TSPITR_ACCT_KYED。該目錄還包含兩個其他子目錄:datafile(用於數據文件)和 onlinelog(用於重做日志)。在完成新表空間的創建之前,可以查看該目錄以了解恢復了哪些文件。(這些文件在該過程結束時會被刪除。)
長期以來,DBA 一直期待著能夠通過 RMAN 備份創建一個可傳輸的表空間。但請注意,您是從備份(而不是從聯機表空間)中插入傳輸的表空間。因此,它將不是最新的。
對已分區的按索引組織的表實現快速的分區分割
考慮這樣一種情況:假設您擁有一個已分區的表。月末到了,但您忘了為下一個月定義分區。您現在有哪些選擇呢?
您唯一的救濟方法就是將最大值分區分割為兩個部分:一個用於新月份的分區和一個新的最大值分區。但將該方法用於已分區的按索引組織的表時將遇到一個小問題。這種情況下,將先創建物理分區,並將行從最大值分區移動到該分區,這樣將消耗 I/O 和 CPU 周期。
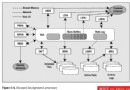
在 Oracle 數據庫 10g 第 2 版中,該過程得到顯著簡化。如下圖所示,假設您將分區一直定義到 5 月份,然後已經將 PMAX 分區定義為一個通用分區。由於 6 月份沒有特定分區,因此 6 月份數據進入 PMAX 分區。灰顯的方框顯示了填充到該段中的數據。由於只填充了部分 PMAX 分區,因此您只看到一部分灰色區域。
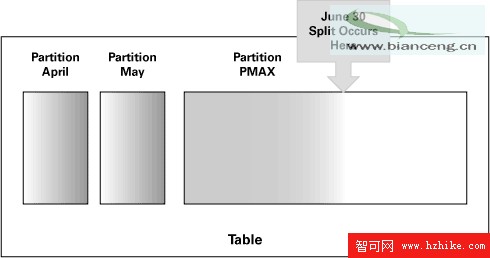
現在,在 6 月 30 日對分區 PMAX 進行分割,以創建 6 月分區和新的 PMAX 分區。由於當前 PMAX 中的所有數據都將進入新的 6 月分區,因此 Oracle 數據庫 10g 第 2 版只創建新的最大值分區,並使現有分區成為新創建的月分區。這就導致了根本不會發生數據移動(因此沒有“空”的 I/O 和 CPU 周期)。而最好之處在於,ROWID 不會發生變化。
通過聯機重新定義將 LONG 轉換為 LOB
如果數據倉庫數據庫已經存在一段時間,並且您要處理大型文本數據,則您可能擁有大量數據類型為 LONG 的列。毋庸質疑,LONG 數據類型在大多數數據操作環境(如通過 SUBSTR 進行搜索)中是沒有用處的。您肯定需要將它們轉換為 LOB 列。
可以使用 DBMS_REDEFINITION 程序包聯機執行該操作。但在 Oracle 數據庫 10g 第 2 之前,有一個很大的限制。
將 LONG 列轉換為 LOB 列時,您很希望獲得高性能;您需要使該過程盡可能地快。如果將表進行了分區,則該過程將跨分區並行執行。但如果未將表進行分區,則該過程將串行執行,從而可能持續很長時間。
幸好,在 Oracle 數據庫 10g 第 2 版中,即使表未分區也可以在 DBMS_REDEFINITION 程序包內部執行從 LONG 到 LOB 的聯機轉換。我們通過一個示例來了解該轉換的過程。以下是一個用於保存發送給客戶的電子郵件的表。由於郵件正文(存儲在 MESG_TEXT 中)通常是較長的文本數據,因此已將該列定義為 LONG。
SQL> desc acc_mesg
Name Null?Type
----------------------------------------- -------- ---------
ACC_NO NOT NULL NUMBER
MESG_DT NOT NULL DATE
MESG_TEXT LONG
您需要將該列轉換為 CLOB。首先,創建一個結構相同的(最後一列除外,它被定義為 CLOB)空臨時表。create table ACC_MESG_INT
(
acc_no number,
mesg_dt date,
mesg_text clob
);
現在,啟動重新定義過程。
1 begin
2 dbms_redefinition.start_redef_table (
3 UNAME => 'ARUP',
4 ORIG_TABLE => 'ACC_MESG',
5 INT_TABLE => 'ACC_MESG_INT',
6 COL_MAPPING => 'acc_no acc_no, mesg_dt mesg_dt, to_lob(MESG_TEXT) MESG_TEXT'
7 );
8* end;
注意第 6 行,該行已經對列進行了映射。前兩列保持不變,但第三列 MESG_TEXT 已被映射,以便通過對源表的列應用函數 TO_LOB 來填充目標表的 MESG_TEXT 列。
如果要重新定義的表很大,則需要定期對源表和目標表之間的數據進行同步。該方法加快了最終同步的速度。
begin
dbms_redefinition.sync_interim_table(
uname => 'ARUP',
orig_table => 'ACC_MESG',
int_table => 'ACC_MESG_INT'
);
end;
/
根據表的大小,您可能需要多次執行以上命令。最後,使用以下代碼完成重新定義過程
begin 表 ACC_MESG 已經發生了變化:
dbms_redefinition.finish_redef_table (
UNAME => 'ARUP',
ORIG_TABLE => 'ACC_MESG',
INT_TABLE => 'ACC_MESG_INT'
);
end;
/
SQL> desc acc_mesg
Name Null?Type
----------------------------------------- -------- ---------
ACC_NO NOT NULL NUMBER
MESG_DT NOT NULL DATE
MESG_TEXT
注意,MESG_TEXT 列現在為 CLOB 而非 LONG。
該特性對於將錯誤定義的數據結構或原先遺留的數據結構轉換為更容易管理的數據類型非常有用。
聯機重組單個分區
假設您有一個包含事務歷史的表 TRANS。該表基於 TRANS_DATE 進行分區,每個季度作為一個分區。在正常的業務過程中,最新的分區經常更新。某個季度過後,該分區上可能沒有很多活動了,因此可以將它移動到其他位置。但移動本身將需要對表進行鎖定,從而拒絕對分區的公共訪問。如何在不影響其可用性的情況下移動分區?
在 Oracle 數據庫 10g 第 2 版中,可以對單個分區使用聯機重新定義。您可以像對整個表執行重新定義(使用 DBMS_REDEFINITION 程序包)一樣執行此任務,但底層機制並不相同。常規表是通過對源表創建物化視圖重新定義的,而單個分區是通過交換分區方法重新定義的。
我們來看一下它的工作原理。以下是 TRANS 表的結構:
SQL> desc trans 該表已經按如下所示進行了分區:
Name Null?Type
--------------------------------- -------- -------------------------
TRANS_ID NUMBER
TRANS_DATE DATE
TXN_TYPE VARCHAR2(1)
ACC_NO NUMBER
TX_AMT NUMBER(12,2)
STATUS partition by range (trans_date)
(
partition y03q1 values less than (to_date('04/01/2003','mm/dd/yyyy')),
partition y03q2 values less than (to_date('07/01/2003','mm/dd/yyyy')),
partition y03q3 values less than (to_date('10/01/2003','mm/dd/yyyy')),
partition y03q4 values less than (to_date('01/01/2004','mm/dd/yyyy')),
partition y04q1 values less than (to_date('04/01/2004','mm/dd/yyyy')),
partition y04q2 values less than (to_date('07/01/2004','mm/dd/yyyy')),
partition y04q3 values less than (to_date('10/01/2004','mm/dd/yyyy')),
partition y04q4 values less than (to_date('01/01/2005','mm/dd/yyyy')),
partition y05q1 values less than (to_date('04/01/2005','mm/dd/yyyy')),
partition y05q2 values less than (to_date('07/01/2005','mm/dd/yyyy'))
)
在某個時刻,您決定將分區 Y03Q2 移動到另一個表空間 (TRANSY03Q2),該表空間可能位於一個不同類型的磁盤(一個慢一點、便宜一點的磁盤)上。為此,請首先確認您可以聯機重新定義該表:
begin
dbms_redefinition.can_redef_table(
uname => 'ARUP',
tname => 'TRANS',
options_flag => dbms_redefinition.cons_use_rowid,
part_name => 'Y03Q2');
end;
/
此處沒有輸出,因此您確認可以聯機重新定義該表。接下來,創建一個臨時表保存該分區的數據:
create table trans_temp
(
trans_id number,
trans_date date,
txn_type varchar2(1),
acc_no number,
tx_amt number(12,2),
status varchar2(1)
)
tablespace transy03q2
/
請注意,由於表 TRANS 進行了范圍分區,因此您已經將該表定義為未分區表。該表在所需的表空間 TRANSY03Q2 中創建。如果表 TRANS 包含一些本地索引,則表示您已經對表 TRANS_TEMP 創建了這些索引(當然是創建為未分區索引)。
現在,您就可以啟動重新定義過程:
begin
dbms_redefinition.start_redef_table(
uname => 'ARUP',
orig_table => 'TRANS',
int_table => 'TRANS_TEMP',
col_mapping => NULL,
options_flag => dbms_redefinition.cons_use_rowid,
part_name => 'Y03Q2');
end;
/
該調用有幾個注意事項。第一,將參數 col_mapping 設置為 NULL;在單個分區重新定義中,該參數沒有意義。第二,一個新參數 part_name 指定了要重新定義的分區。第三,注意其中沒有 COPY_TABLE_DEPENDENTS 參數,該參數也沒有意義,原因是表本身無法更改;只移動分區。
如果該表很大,此操作可能持續很長時間;因此請在操作過程中對它進行同步。begin
dbms_redefinition.sync_interim_table(
uname => 'ARUP',
orig_table => 'TRANS',
int_table => 'TRANS_TEMP',
part_name => 'Y03Q2');
end;
/
最後,使用以下代碼完成該過程begin
dbms_redefinition.finish_redef_table(
uname => 'ARUP',
orig_table => 'TRANS',
int_table => 'TRANS_TEMP',
part_name => 'Y03Q2');
end;
此時,分區 Y03Q2 位於表空間 TRANSY03Q2 中。如果該表存在任何全局索引,則它們將被標記為 UNUSABLE 並且必須被重新構建。
單個分區重新定義對於跨表空間移動分區(一個常見的信息生命周期管理任務)很有用。但顯而易見,其中存在幾個限制。例如,您無法在重新定義過程中更改分區方法(即從范圍更改為散列)或更改表的結構。
逐塊地刪除表
您注意到過刪除一個分區的表需要多長時間嗎?這是因為每個分區都是一個必須刪除的段。在 Oracle 數據庫 10g 第 2 版中,當您刪除分區的表時,分區將逐個被刪除。由於每個分區是單獨刪除的,因此所需的資源要比刪除整個表少。
要演示這個新行為,您可以使用 10046 跟蹤跟蹤該會話。alter session set events '10046 trace name context forever, level 12';
然後,刪除該表。如果查看跟蹤文件,則將看到分區表刪除的代碼:delete from tabpart$ where bo# = :1
delete from partobj$ where obj#=:1
delete from partcol$ where obj#=:1
delete from subpartcol$ where obj#=:1
請注意,分區是按順序刪除的。該方法最大限度地降低了刪除過程中的資源使用率並增強了性能。