DCD 起初是專為 客戶機沒有從會話中斷開聯接的情況下斷電的環境設計的.
DCD由服務端開始建立聯接. 這時候SQL*Net 從參數文件中讀取變量, 設置一個定時器定時產生信號. 這個時間間隔是sqlnet.ora文件中的SQLNET.EXPIRE_TIME提供的.
當定時器設定的時間到了之後, 服務器上的SQL*Net 發送一個探測包到客戶端.(如果是數據庫聯接, 目的端的服務器發送探測包到另一端). 探測包是由空的SQL*Net包組成, 不體現SQL*Net層任何數據, 但會在下一層的網絡協議中產生數據流量.
如果客戶端的聯接仍然是活動的, 探測包被丟棄. 計時裝置復位. 如果客戶端異常斷掉. 服務器將收到由發送探測包的調用發出的錯誤. SQL*Net 將會通知操作系統釋放聯接占用的資源.
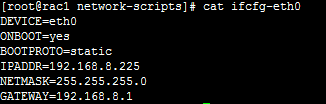
在Unix服務器上 sqlnet.ora 文件必須存在$TNS_ADMIN 或者 $ORACLE_HOME/network/admin目錄下. 而不是/etc 或者 /var/opt/Oracle
同時也應該注意, SQL*Net 2.1.x中 一個活動的孤兒進程(例如, 單獨的查詢進程) 在查詢完成之前不會被殺掉. SQL*Net 2.2中孤兒進程占用的資源將會被無條件釋放.
這只是服務器的特性, 客戶端將會支持任何SQL*Net V2 的發行版
協議棧的功能
雖然 死聯接檢測是在SQL*Net層的, 但要成功執行在很大程度上要依靠下層協議棧. 例如, 如果在sqlnet.ora文件中 設置SQLNET.EXPIRE_TIME=1, 但是一個孤兒進程很有可能在間隔到了之後被清除掉.
TCP/IP協議是一個面向聯接的協議, 同樣的, 這個協議在超時時執行重傳數據包的操作, 確保數據的安全和數據包的順序. 如果對探測包沒有及時回應, TCP/IP棧將在一段時間內重傳這個包. 當TCP/IP放棄重傳之後, SQL*Net 將會收到 探測失敗的通知.
TCP/IP超時的時間取決於 TCP/IP棧, 超時很多分鐘是很常見的, 這個涉及到很多客戶, 許多協議層的重傳會造成孤兒進程被殺掉之前要等很長時間.
最簡單的辦法檢測協議棧有這個延遲需要測試不同的DCD間隔.
測試協議棧
設置參數SQLNET.EXPIRE_TIME = 1 min, 注意清除孤兒進程需要的時間. 然後設置為 5min,
再次觀察這個時間. 如果服務器沒有釋放資源是由於TCP/IP超時造成的, 清除影子的時間需要增加到4min.
如果TCP/IP超時重傳是造成問題的所在, 操作系統的內核參數應該調整一下, 在Unix平台下, /usr/include/netinet/tcp_timer.h 中包含著配置參數.
減小重傳間隔可能會影響系統的其它部分, 因為實際上減小了聯接處理數據的窗口, 可能會在系統重負荷的情況下丟失聯接, 遠程慢的聯接會受到這個更改的影響。
系統參數會影響超時重傳的有 TCP_TTL, TCPTV_PERSMIN, TCPTV_MAX, 和 TCP_LINGERTIME等。
********************
為了防止對系統其他進程產生影響, 在調整系統參數時最好向相關的廠家咨詢
*******************
監控 死聯接檢測
檢測DCD是否打開和運行正常最好的方法就是 產生一個服務跟蹤文件, 查找 DCD探測包.
要產生一個服務跟蹤文件, 在sqlnet.ora文件中設置TRACE_LEVEL_SERVER=16,