數據庫管理系統一次通常只能運行在一台服務器上。在不采用高級解決方案的前提下(比如Oracle公司的Real Application Clusters)數據庫則只能在服務器之間手工遷移。由於難以在數據庫級別上平衡服務器負載,所以這一局限性導致大量計算機資源被白白浪費了。
從SAN到DAN
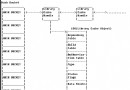
雖然SAN (存儲區域網)和動態應用服務器在Web和應用服務器負載均衡領域取得了巨大的成功,但是,數據庫層卻仍然是系統性能的瓶頸。利用SAN能夠很方便地在服務器之間搬移磁盤,從而令IT管理職員可以根據需要對磁盤存儲動態地重新部署,如圖A所示。

當前的靈活體系
SAN技術實現了多計算機之間的單線程數據共享,但問題也隨之而來:在處理能力需求發生改變的情況下該如何智能地重新部署數據庫呢。這就是DAN(數據庫區域網:Database Area Network)技術的用武之地了。
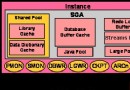
DAN架構用到了數據庫交換機,其下的SAN則實現了數據庫在不影響可用性的情況下在服務器之間的搬移。圖B所示就是兩種架構。

SAN 和DAN架構
數據庫服務器負載均衡是一個復雜而又問題叢生的技術話題。許多公司年復一年耗費了大量的資金重新部署數據庫服務器資源。更糟糕的是,由於資源分配的不足和不合理,最終用戶不得不容忍漫長的服務響應時間,直到數據庫管理員(DBA)通過手工操作的方式把數據庫再度分配到更大的服務器上,研究人員利用DAN技術就可以在處理要求超出服務器處理能力的時候動態分配數據庫。
DAN技術的工作原理
DAN技術的內部機制可謂相當簡單。在SAN環境下,數據庫的重新部署涉及到以下的步驟:
關閉數據庫,采用軟件方法立即重定向交易。
把數據文件重定向到使用SAN的目標服務器。
在新服務器上重新啟動數據庫。
用Oracle的Transparent Application Failover (TAF)之類的內建產品進行處理不會在重新部署期間丟失任何交易,最終用戶也不會察覺到數據庫已經變更了服務器。
數據庫管理系統一次通常只能運行在一台服務器上。在不采用高級解決方案的前提下(比如Oracle公司的Real Application Clusters)數據庫則只能在服務器之間手工遷移。由於難以在數據庫級別上平衡服務器負載,所以這一局限性導致大量計算機資源被白白浪費了。
從SAN到DAN
雖然SAN (存儲區域網)和動態應用服務器在Web和應用服務器負載均衡領域取得了巨大的成功,但是,數據庫層卻仍然是系統性能的瓶頸。利用SAN能夠很方便地在服務器之間搬移磁盤,從而令IT管理職員可以根據需要對磁盤存儲動態地重新部署,如圖A所示。
當前的靈活體系
SAN技術實現了多計算機之間的單線程數據共享,但問題也隨之而來:在處理能力需求發生改變的情況下該如何智能地重新部署數據庫呢。這就是DAN(數據庫區域網:Database Area Network)技術的用武之地了。
DAN架構用到了數據庫交換機,其下的SAN則實現了數據庫在不影響可用性的情況下在服務器之間的搬移。圖B所示就是兩種架構。
SAN 和DAN架構
數據庫服務器負載均衡是一個復雜而又問題叢生的技術話題。許多公司年復一年耗費了大量的資金重新部署數據庫服務器資源。更糟糕的是,由於資源分配的不足和不合理,最終用戶不得不容忍漫長的服務響應時間,直到數據庫管理員(DBA)通過手工操作的方式把數據庫再度分配到更大的服務器上,研究人員利用DAN技術就可以在處理要求超出服務器處理能力的時候動態分配數據庫。
DAN技術的工作原理
DAN技術的內部機制可謂相當簡單。在SAN環境下,數據庫的重新部署涉及到以下的步驟:
關閉數據庫,采用軟件方法立即重定向交易。
把數據文件重定向到使用SAN的目標服務器。
在新服務器上重新啟動數據庫。
用Oracle的Transparent Application Failover (TAF)之類的內建產品進行處理不會在重新部署期間丟失任何交易,最終用戶也不會察覺到數據庫已經變更了服務器。
DAN的優點
這種類型的負載均衡對IT管理人員來說具有不一般的影響。由於在硬件上投入了巨資,IT管理人員的工作就是實現昂貴的服務器資源利用率的最大化,同時維持最終用戶可以接受的響應時間。根據處理要求采用DAN重新部署數據庫就可以鞏固和強化對服務器的IT管理,從而為企業在硬件和軟件許可證費用方面節約大量資金創造了條件。
同時,采用DAN之後DBA維護的工作量也會大大降低。由於服務器資源的整合,DBA直接管理的服務器數量顯著減少,幾乎不再擔心服務器的處理能力擴充問題。
DAN還實現了數據庫行為的“黑盒”化。這就是說,由於數據庫獨立於操作之外而令操作系統架構失去了以往的重要性。比如說,Oracle數據庫就可以無縫地重新部署在AIX、Linux、Solaris或者HP/UX等系統之上,原因就在於以上這些平台都支持Oracle數據庫系統。因為DAN隱藏了操作系統的內部結構,所以DAN盡可根據服務器的處理能力重新部署數據庫。
隨著DAN技術日益走向成熟,DAN最終可以根據先驗的歷史測量數據來預測數據庫遭遇處理壓力而必須重新部署到更大型服務器的時間,從而滿足日益增長的處理要求。所有理智的數據庫專業人士都知道,數據庫服務器有規律地表現出一些眾所周知的處理壓力“信號”。出現這些信號是因為最終用戶處理能力要求的周期性,而且我們可以每周、日、小時為度量單元描繪出服務器受到的處理壓力,從而觀察這些“信號”的出現情況。
如果CPU和內存使用情況的歷史測量可用,那麼DAN就應當能預測數據庫搬移到更強大服務器的時間。DAN可以預測迫近的處理高峰,在需要最大處理能力的時候重新部署數據庫。
下面我們就看看DAN技術是如何完成以上任務的。假設我們擁有兩個數據庫,其CPU利用情況如圖C所示。

配置示例
在圖C中,系統A於周二達到了100%的使用率,而系統B則在周三到周五都達到了峰值負載。在沒有用到DAN技術的情況下,IT管人員只能被迫把這些數據庫放到兩台價值4萬美元的服務器上。而采用DAN技術後,IT管理人員就可以重新部署數據庫並用更便宜的、價值1萬美元的Linux服務器取代第2台服務器。DAN則在處理要求發生變動的情況下重新部署數據庫。而系統則節約了3萬美元。
DAN技術向何處去?
任何采用SAN的數據庫都可以在幾分鐘的系統關機時間內方便地從一台服務器移到另一台服務器。而在采用DAN技術的場合下,負責數據庫重新部署的管理人員可以在不丟失即時交易的情況下提供無縫的數據庫重新部署,智能代理則直接負責數據庫的重新部署。如果DAN真能滿足以往SAN定位的市場要求,那麼大型數據庫應用商會如何利用DAN技術實施動態數據庫負載均衡呢?我們對這種新技術的未來發展趨勢拭目以待。