我們知道,Oracle作為一種大型數據庫,廣泛應用於金融、郵電、電力、民航等
數據吞吐量巨大,計算機網絡廣泛普及的重要部門。對於系統管理員來講,如何
保證網絡穩定運行,如何提高數據庫性能,使其更加安全高效,就顯得尤為重要
。作為影響數據庫性能的一大因素--數據庫碎片,應當引起dba的足夠重視,及時
發現並整理碎片乃是dba一項基本維護內容。
---- 1、碎片是如何產生的
---- 當生成一個數據庫時,它會分成稱為表空間(tablespace)的多個邏輯段(
segment),如系統(system)表空間,臨時(temporary)表空間等。一個表空間
可以包含多個數據范圍(extent)和一個或多個自由范圍塊,即自由空間(free
space)。
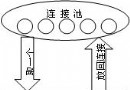
---- 表空間、段、范圍、自由空間的邏輯關系如下:
---- 當表空間中生成一個段時,將從表空間有效自由空間中為這個段的初始范圍
分配空間。在這些初始范圍充滿數據時,段會請求增加另一個范圍。這樣的擴展
過程會一直繼續下去,直到達到最大的范圍值,或者在表空間中已經沒有自由空
間用於下一個范圍。最理想的狀態就是一個段的數據可被存在單一的一個范圍中
。這樣,所有的數據存儲時靠近段內其它數據,並且尋找數據可少用一些指針。
但是一個段包含多個范圍的情況是大量存在的,沒有任何措施可以保證這些范圍
是相鄰存儲的,如圖〈1〉。當要滿足一個空間要求時,數據庫不再合並相鄰的自
由范圍(除非別無選擇), 而是尋找表空間中最大的自由范圍來使用。這樣將逐
漸形成越來越多的離散的、分隔的、較小的自由空間,即碎片。例如:
---- 2、碎片對系統的影響
---- 隨著時間推移,基於數據庫的應用系統的廣泛使用,產生的碎片會越來越多
,將對數據庫有以下兩點主要影響:
---- (1)導致系統性能減弱
---- 如上所述,當要滿足一個空間要求時,數據庫將首先查找當前最大的自由范
圍,而"最大"自由范圍逐漸變小,要找到一個足夠大的自由范圍已變得越來越困
難,從而導致表空間中的速度障礙,使數據庫的空間分配愈發遠離理想狀態;
---- (2)浪費大量的表空間
---- 盡管有一部分自由范圍(如表空間的pctincrease為非0)將會被smon(系統
監控)後台進程周期性地合並,但始終有一部分自由范圍無法得以自動合並,浪
費了大量的表空間。
---- 3、自由范圍的碎片計算
---- 由於自由空間碎片是由幾部分組成,如范圍數量、最大范圍尺寸等,我們可
用fsfi--free space fragmentation index(自由空間碎片索引)值來直觀體現
:
fsfi=100*sqrt(max(extent)/sum(extents))*1/sqrt(sqrt(count(extents)))
---- 可以看出,fsfi的最大可能值為100(一個理想的單文件表空間)。隨著范
圍的增加,fsfi值緩慢下降,而隨著最大范圍尺寸的減少,fsfi值會迅速下降。
---- 下面的腳本可以用來計算fsfi值:
rem fsfi value compute
rem fsfi.sql
column fsfi format 999,99
select tablespace_name,sqrt(max(blocks)/sum(blocks))*
(100/sqrt(sqrt(count(blocks)))) fsfi
from dba_free_space
group by tablespace_name order by 1;
spool fsfi.rep;
/
spool off;
---- 比如,在某數據庫運行腳本fsfi.sql,得到以下fsfi值:
tablespace_name fsfi
------------------------------ -------
rbs 74.06
system 100.00
temp 22.82
tools 75.79
users 100.00
user_tools 100.00
ydcx_data 47.34
ydcx_idx 57.19
ydjf_data 33.80
ydjf_idx 75.55
---- 統計出了數據庫的fsfi值,就可以把它作為一個可比參數。在一個有著足夠
有效自由空間,且fsfi值超過30的表空間中,很少會遇見有效自由空間的問題。
當一個空間將要接近可比參數時,就需要做碎片整理了。
---- 4、自由范圍的碎片整理
---- (1)表空間的pctincrease值為非0
---- 可以將表空間的缺省存儲參數pctincrease改為非0。一般將其設為1,如:
alter tablespace temp
default storage(pctincrease 1);
---- 這樣smon便會將自由范圍自動合並。也可以手工合並自由范圍:
alter tablespace temp coalesce;
---- 5、段的碎片整理
---- 我們知道,段由范圍組成。在有些情況下,有必要對段的碎片進行整理。要
查看段的有關信息,可查看數據字典dba_segments,范圍的信息可查看數據字典
dba_extents。如果段的碎片過多, 將其數據壓縮到一個范圍的最簡單方法便是
用正確的存儲參數將這個段重建,然後將舊表中的數據插入到新表,同時刪除舊
表。這個過程可以用import/export(輸入/輸出)工具來完成。
---- export()命令有一個(壓縮)標志,這個標志在讀表時會引發export確定
該表所分配的物理空間量,它會向輸出轉儲文件寫入一個新的初始化存儲參數--
等於全部所分配空間。若這個表關閉, 則使用import()工具重新生成。這樣,
它的數據會放入一個新的、較大的初始段中。例如:
exp user/passWord file=exp.dmp compress=y grants=y indexes=y
tables=(table1,table2);
---- 若輸出成功,則從庫中刪除已輸出的表,然後從輸出轉儲文件中輸入表:
imp user/passWord file=exp.dmp commit=y buffer=64000 full=y
---- 這種方法可用於整個數據庫。
---- 以上簡單分析了Oracle數據庫碎片的產生、計算方法及整理,僅供參考。數
據庫的性能優化是一項技術含量高,同時又需要有足夠耐心、認真細致的工作。
對數據庫碎片的一點探討,
---- 如果能起到拋磚引玉,對大家有所啟發的話,便是作者最大的心願。
另外, 應該定期shutdown database, 從而清理momery碎片.