如果你有兩個數據來源,如平面文件或表數據,並且要將他們合並在一起,你將怎麼做?如果他們有一個共同的屬性,如客戶ID,那麼該解決方案應該是很明顯:合並相關的屬性,在這個例子中,只需合並客戶ID就夠了。如果沒有任何共同之處該怎麼辦呢?唯一的要求就是,將數據源1中的記錄和數據源2中的記錄進行匹配 。並且,那個記錄去和另一個記錄匹配並沒有關系,那麼問題是,一個數據源中的每一個紀錄如何獲得從其他數據源記錄的標記。
上述問題可以被描述為向一個數據庫中加入了不同的或看似無關的數據。在先前的文章的文章中,涉及如何使用ROWNUM在無關的數據之間創造聯系。該合並方法的本質是利用甲骨文提供虛擬數據列來建立聯系。下面的查詢可以用來作為CREATE TABLE AS SELECT聲明的一部分或作為基於滿足加入條件既定目標表的插入。
SELECT * FROM
(SELECT , ROWNUM AS rownum_a
FROM TABLE_A
) ALIAS_A,
(SELECT , ROWNUM AS rownum_b
FROM TABLE_B
) ALIAS_B
WHERE ALIAS_A.rownum_a = ALIAS_B.rownum_b;
假設要合並的記錄的數目過大(如數以百萬計),這種方法潛在的缺點是什麼?那麼,當一行作為一個記錄時又如何了?我們沒有真正的控制權決定的查詢所返回結果行的順序,直到我們執行查詢之前,甲骨文是不知道記錄的行號的。換言之, ROWNUM是在這樣的事實上創建的。如果你要從兩個地方選擇數百萬行,你將支付甲骨文公司為每個記錄分配行號(只針對你的查詢,而不是永遠)的時間。
讓我們監測將兩個有100萬行的表合並到一起的一個會話。在這第一個例子中,這個數據源已經記錄可100萬個記錄。表A范圍從1到1000000及表B范圍從1000001至2000000 (即在第一個表中再加入100萬行) 。如果加入後能夠完美的保持行的順序,那麼有序對將像下面表格這個樣子:
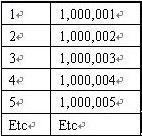
當我們查看數據時(通過Toad)發現Oracle數據庫並不執行一個完美的排序,並且相差甚遠。
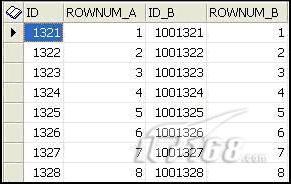
該ROWNUM_A和B值一個一個都匹配,因為這是我們匹配/合並的。注意:記錄1321 (和1001321 )是如何同ROWNUM 1標記在一起的 。所以我們可以推斷是,甲骨文以同樣的方式填補表格之間的空白區塊。這應該說服你一次甚至永遠(如果你至今還不知知道), ROWNUM虛擬數據列已沒有意義或與個表中記錄的實際順序無關。