當你運用SQL語言,向數據庫發布一條查詢語句時,ORACLE將伴隨產生一個“執行計劃”,也就是該語句將通過何種數據搜索方案執行,是通過全表掃描、還是通過索引搜尋等其它方式。搜索方案的選用與ORACLE的優化器息息相關。
SQL語句的執行步驟
一條SQL語句的處理過程要經過以下幾個步驟。
1 語法分析 分析語句的語法是否符合規范,衡量語句中各表達式的意義。
2 語義分析 檢查語句中涉及的所有數據庫對象是否存在,且用戶有相應的權限。
3 視圖轉換 將涉及視圖的查詢語句轉換為相應的對基表查詢語句。
4 表達式轉換 將復雜的SQL表達式轉換為較簡單的等效連接表達式。
5 選擇優化器 不同的優化器一般產生不同的“執行計劃”
6 選擇連接方式 ORACLE有三種連接方式,對多表連接ORACLE可選擇適當的連接方式。
7 選擇連接順序 對多表連接ORACLE選擇哪一對表先連接,選擇這兩表中哪個表做為源數據表。
8 選擇數據的搜索路徑 根據以上條件選擇合適的數據搜索路徑,如是選用全表搜索還是利用索引或是其他的方式。
9 運行“執行計劃”
ORACLE的優化器
ORACLE有兩種優化器:基於規則的優化器(RBO, Rule Based Optimizer),和基於代價的優化器(CBO, Cost Based Optimizer)。
RBO自ORACLE 6版以來被采用,有著一套嚴格的使用規則,只要你按照它去寫SQL語句,無論數據表中的內容怎樣,也不會影響到你的“執行計劃”,也就是說對數據不“敏感”,ORACLE公司已經不再發展這種技術了。
CBO自ORACLE 7版被引入,ORACLE自7版以來采用的許多新技術都是基於CBO的,如星型連接排列查詢,哈希連接查詢,和並行查詢等。CBO計算各種可能“執行計劃”的“代價”,即cost,從中選用cost最低的方案,作為實際運行方案。各“執行計劃”的cost的計算根據,依賴於數據表中數據的統計分布,ORACLE數據庫本身對該統計分布並不清楚,須要分析表和相關的索引,才能搜集到CBO所需的數據。
一般而言,CBO所選擇的“執行計劃”都不會比RBO的“執行計劃”差,而且相對而言,CBO對程序員的要求沒有RBO那麼苛刻,節省了程序員為了從多個可能的“執行計劃”中選擇一個最優的方案而花費的調試時間,但在某些場合下也會存在問題。
較典型的問題有:有時,表明明建有索引,但查詢過程顯然沒有用到相關的索引,導致查詢過程耗時漫長,占用資源巨大,問題到底出在哪兒呢?按照以下順序查找,基本上能發現原因所在。
查找原因的步驟
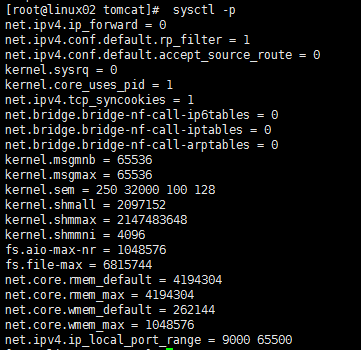
首先,我們要確定數據庫運行在何種優化模式下,相應的參數是:optimizer_mode。可在svrmgrl中運行“show parameter optimizer_mode"來查看。ORACLE V7以來缺省的設置應是"choose",即如果對已分析的表查詢的話選擇CBO,否則選擇RBO。如果該參數設為“rule”,則不論表是否分析過,一概選用RBO,除非在語句中用hint強制。
其次,檢查被索引的列或組合索引的首列是否出現在PL/SQL語句的WHERE子句中,這是“執行計劃”能用到相關索引的必要條件。
第三,看采用了哪種類型的連接方式。ORACLE的共有Sort Merge Join(SMJ)、Hash Join(HJ)和Nested Loop Join(NL)。在兩張表連接,且內表的目標列上建有索引時,只有Nested Loop才能有效地利用到該索引。SMJ即使相關列上建有索引,最多只能因索引的存在,避免數據排序過程。HJ由於須做HASH運算,索引的存在對數據查詢速度幾乎沒有影響。
第四,看連接順序是否允許使用相關索引。假設表emp的deptno列上有索引,表dept的列deptno上無索引,WHERE語句有emp.deptno=dept.deptno條件。在做NL連接時,emp做為外表,先被訪問,由於連接機制原因,外表的數據訪問方式是全表掃描,emp.deptno上的索引顯然是用不上,最多在其上做索引全掃描或索引快速全掃描。
第五,是否用到系統數據字典表或視圖。由於系統數據字典表都未被分析過,可能導致極差的“執行計劃”。但是不要擅自對數據字典表做分析,否則可能導致死鎖,或系統性能下降。