1 Oracle Text的體系架構
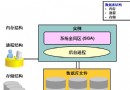
下圖是Oracle Text的體系架構。
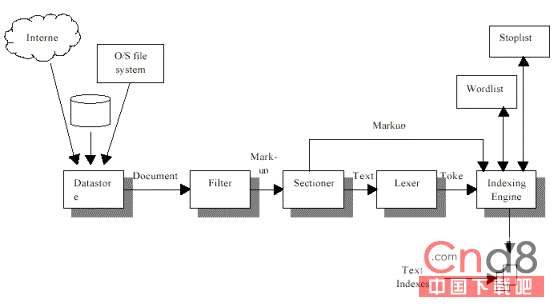
圖1 Oracle Text的體系架構
以上面的體系架構圖為基礎,Oracle Text 索引文檔時所使用的主要邏輯步驟如下:
(1)數據存儲邏輯搜索表的所有行,並讀取列中的數據。通常,這只是列數據,但有些數據存儲使用列數據作為文檔數據的指針。例如,URL_DATASTORE 將列數據作為 URL 使用。
(2)過濾器提取文檔數據並將其轉換為文本表示方式。存儲二進制文檔 (如 Word 或 Acrobat 文件) 時需要這樣做。過濾器的輸出不必是純文本格式 -- 它可以是 XML 或 HTML 之類的文本格式。
(3)分段器提取過濾器的輸出信息,並將其轉換為純文本。包括 XML 和 HTML 在內的不同文本格式有不同的分段器。轉換為純文本涉及檢測重要文檔段標記、移去不可見的信息和文本重新格式化。
(4)詞法分析器提取分段器中的純文本,並將其拆分為不連續的標記。既存在空白字符分隔語言使用的詞法分析器,也存在分段復雜的亞洲語言使用的專門詞法分析器。
(5)索引引擎提取詞法分析器中的所有標記、文檔段在分段器中的偏移量以及被稱為非索引字的低信息含量字列表,並構建反向索引。倒排索引存儲標記和含有這些標記的文檔。