Oracle使用正則表達式離不開這4個函數:
1。regexp_like
2。regexp_substr
3。regexp_instr
4。regexp_replace
看函數名稱大概就能猜到有什麼用了。
regexp_like 只能用於條件表達式,和 like 類似,但是使用的正則表達式進行匹配,語法很簡單:
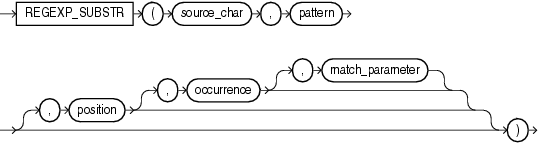
regexp_substr 函數,和 substr 類似,用於拾取合符正則表達式描述的字符子串,語法如下:
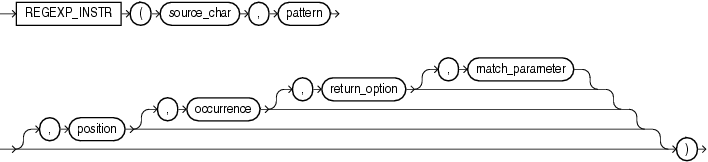
regexp_instr函數,和 instr 類似,用於標定符合正則表達式的字符子串的開始位置,語法如下:
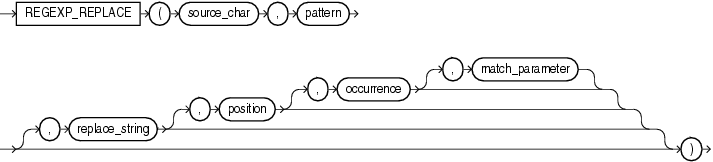
regexp_replace 函數,和 replace 類似,用於替換符合正則表達式的字符串,語法如下:
這裡解析一下幾個參數的含義:
1。source_char,輸入的字符串,可以是列名或者字符串常量、變量。
2。pattern,正則表達式。
3。match_parameter,匹配選項。
取值范圍: i:大小寫不敏感; c:大小寫敏感;n:點號 . 不匹配換行符號;m:多行模式;x:擴展模式,忽略正則表達式中的空白字符。
4。position,標識從第幾個字符開始正則表達式匹配。
5。occurrence,標識第幾個匹配組。
6。replace_string,替換的字符串。
'' 轉義符。
字符簇:
[[:alpha:]] 任何字母。
[[:digit:]] 任何數字。
[[:alnum:]] 任何字母和數字。
[[:space:]] 任何白字符。
[[:upper:]] 任何大寫字母。
[[:lower:]] 任何小寫字母。
[[unct:]] 任何標點符號。
[[:xdigit:]] 任何16進制的數字,相當於[0-9a-fA-F]。
各種操作符的運算優先級
轉義符
(), (?, (?=), [] 圓括號和方括號
*, +, ?, {n}, {n,}, {n,m} 限定符
^, $, anymetacharacter 位置和順序
| “或”操作
--測試數據
create table test(mc varchar2(60));
insert into test values('112233445566778899');
insert into test values('22113344 5566778899');
insert into test values('33112244 5566778899');
insert into test values('44112233 5566 778899');
insert into test values('5511 2233 4466778899');
insert into test values('661122334455778899');
insert into test values('771122334455668899');
insert into test values('881122334455667799');
insert into test values('991122334455667788');
insert into test values('aabbccddee');
insert into test values('bbaaaccddee');
insert into test values('ccabbddee');
insert into test values('ddaabbccee');
insert into test values('eeaabbccdd');
insert into test values('ab123');
insert into test values('123xy');
insert into test values('007ab');
insert into test values('abcxy');
insert into test values('The final test is is is how to find duplicate words.');
commit;
一、REGEXP_LIKE
select * from test where regexp_like(mc,'^a{1,3}');
select * from test where regexp_like(mc,'a{1,3}');
select * from test where regexp_like(mc,'^a.*e$');
select * from test where regexp_like(mc,'^[[:lower:]]|[[:digit:]]');
select * from test where regexp_like(mc,'^[[:lower:]]');
Select mc FROM test Where REGEXP_LIKE(mc,'[^[:digit:]]');
Select mc FROM test Where REGEXP_LIKE(mc,'^[^[:digit:]]');
二、REGEXP_INSTR
Select REGEXP_INSTR(mc,'[[:digit:]]$') from test;
Select REGEXP_INSTR(mc,'[[:digit:]]+$') from test;
Select REGEXP_INSTR('The price is $400.','$[[:digit:]]+') FROM DUAL;
Select REGEXP_INSTR('onetwothree','[^[[:lower:]]]') FROM DUAL;
Select REGEXP_INSTR(',,,,,','[^,]*') FROM DUAL;
Select REGEXP_INSTR(',,,,,','[^,]') FROM DUAL;
三、REGEXP_SUBSTR
SELECT REGEXP_SUBSTR(mc,'[a-z]+') FROM test;
SELECT REGEXP_SUBSTR(mc,'[0-9]+') FROM test;
SELECT REGEXP_SUBSTR('aababcde','^a.*b') FROM DUAL;
四、REGEXP_REPLACE
Select REGEXP_REPLACE('Joe Smith','( ){2,}', ',') AS RX_REPLACE FROM dual;
Select REGEXP_REPLACE('aa bb cc','(.*) (.*) (.*)', '3, 2, 1') FROM dual;
注:更多精彩文章請關注三聯編程教程欄目。