【鎖】Oracle死鎖(DeadLock)的分類及其模擬
各位技術愛好者,看完本文後,你可以掌握如下的技能,也可以學到一些其它你所不知道的知識,~O(∩_∩)O~:
① 死鎖的概念及其trace文件
② 死鎖的分類
③ 行級死鎖的模擬
④ ITL的概念、ITL結構
⑤ ITL引發的死鎖處理
⑥ ITL死鎖的模擬
Tips:
① 本文在itpub(http://blog.itpub.net/26736162)、博客園(http://www.cnblogs.com/lhrbest)和微信公眾號(xiaomaimiaolhr)上有同步更新。
② 文章中用到的所有代碼、相關軟件、相關資料及本文的pdf版本都請前往小麥苗的雲盤下載,小麥苗的雲盤地址見:http://blog.itpub.net/26736162/viewspace-1624453/。
③ 若網頁文章代碼格式有錯亂,請嘗試以下辦法:①去博客園地址閱讀,②下載pdf格式的文檔來閱讀。
④ 在本篇BLOG中,代碼輸出部分一般放在一行一列的表格中。其中,需要特別關注的地方我都用灰色背景和粉紅色字體來表示,比如在下邊的例子中,thread 1的最大歸檔日志號為33,thread 2的最大歸檔日志號為43是需要特別關注的地方;而命令一般使用黃色背景和紅色字體標注;對代碼或代碼輸出部分的注釋一般采用藍色字體表示。
List of Archived Logs in backup set 11
Thrd Seq Low SCN Low Time Next SCN Next Time
---- ------- ---------- ------------------- ---------- ---------
1 32 1621589 2015-05-29 11:09:52 1625242 2015-05-29 11:15:48
1 33 1625242 2015-05-29 11:15:48 1625293 2015-05-29 11:15:58
2 42 1613951 2015-05-29 10:41:18 1625245 2015-05-29 11:15:49
2 43 1625245 2015-05-29 11:15:49 1625253 2015-05-29 11:15:53
[ZHLHRDB1:root]:/>lsvg -o
T_XLHRD_APP1_vg
rootvg
[ZHLHRDB1:root]:/>
00:27:22 SQL> alter tablespace idxtbs read write;
====》2097152*512/1024/1024/1024=1G
本文如有錯誤或不完善的地方請大家多多指正,ITPUB留言或QQ皆可,您的批評指正是我寫作的最大動力。
寫了近大半年的書了,碰到了各種困難,不過幸運的是基本上都一一克服了。前段時間工作上碰到了一個很奇怪的死鎖問題,由業務發出來的SQL來看是不太可能產生死鎖的,不過的的確確實實在在的產生了,那作者是碰到了哪一類的死鎖呢?ITL死鎖!!有關當時的案例可以參考:http://blog.itpub.net/26736162/viewspace-2124771/和http://blog.itpub.net/26736162/viewspace-2124735/。於是,作者就把死鎖可能出現的情況都分類總結了一下,分享給大家,歡迎大家指出錯誤。本文內容也將寫入作者的新書中,歡迎大家提前訂閱。
所謂死鎖,是指兩個或兩個以上的進程在執行過程中,因爭奪資源而造成的一種互相等待的現象,若無外力作用,它們都將無法推進下去。此時稱系統處於死鎖狀態或系統產生了死鎖,這些永遠在互相等待的進程稱為死鎖進程。Oracle對於“死鎖”是要做處理的,而不是不聞不問。
[ZFLHRDB1:oracle]:/oracle>oerr ora 60
00060, 00000, "deadlock detected while waiting for resource"
// *Cause: Transactions deadlocked one another while waiting for resources.
// *Action: Look at the trace file to see the transactions and resources
// involved. Retry if necessary.
Cause: Your session and another session are waiting for are source locked by the other. This condition is known AS a deadlock. To resolve the deadlock, one or more statements were rolled back for the other session to continue work.
Action Either: l. Enter arollback statement and re—execute all statements since the last commit or 2. Wait until the lock is released, possibly a few minutes, and then re—execute the rolled back statements.
Oracle中產生死鎖的時候會在alert告警日志文件中記錄死鎖的相關信息,無論單機還是RAC環境都有Deadlock這個關鍵詞,而且當發生死鎖時都會生成一個trace文件,這個文件名在alert文件中都有記載。由於在RAC環境中,是由LMD(Lock Manager Daemon)進程統一管理各個節點之間的鎖資源的,所以,RAC環境中trace文件是由LMD進程來生成的。
在RAC環境中,告警日志的形式如下所示:
Mon Jun 20 10:10:56 2016
Global Enqueue Services Deadlock detected. More info in file
/u01/app/oracle/diag/rdbms/raclhr/raclhr2/trace/raclhr2_lmd0_19923170.trc.
在單機環境中,告警日志的形式如下所示:
Mon Jun 20 12:10:56 2016
ORA-00060: Deadlock detected. More info in file /u01/app/oracle/diag/rdbms/dlhr/dlhr/trace/dlhr_ora_16973880.trc.
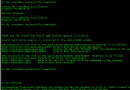
通常來講,對於單機環境,當有死鎖發生後,在trace文件中會看到如下的日志信息:
圖2-1 單機環境下的死鎖
當看到trace文件時,需要確認一下產生鎖的類型,是兩行還是一行,是TX還是TM,如果只有一行那麼說明是同一個SESSION,可能是自治事務引起的死鎖。
對於RAC環境,當有死鎖發生後,在trace文件中會看到如下的日志信息:
圖2-2 RAC環境下的死鎖
死鎖的監測時間是由隱含參數_lm_dd_interval來控制的,在Oracle 11g中,隱含參數_lm_dd_interval的值默認為10,而在Oracle 10g中該參數默認為60,單位為秒。
SYS@oraLHRDB2> SELECT A.INDX,
2 A.KSPPINM NAME,
3 A.KSPPDESC,
4 B.KSPPSTVL
5 FROM X$KSPPI A,
6 X$KSPPCV B
7 WHERE A.INDX = B.INDX
8 AND LOWER(A.KSPPINM) LIKE LOWER('%&PARAMETER%');
ENTER VALUE FOR PARAMETER: _lm_dd_interval
OLD 8: AND LOWER(A.KSPPINM) LIKE LOWER('%&PARAMETER%')
NEW 8: AND LOWER(A.KSPPINM) LIKE LOWER('%_LM_DD_INTERVAL%')
INDX NAME KSPPDESC KSPPSTVL
---------- ------------------ ------------------------------ --------------------
578 _lm_dd_interval dd time interval in seconds 10
可以看到該隱含參數的值為10。
有人的地方就有江湖,有資源阻塞的地方就可能有死鎖。Oralce中最常見的死鎖分為:行級死鎖(Row-Level Deadlock)和塊級死鎖(Block-Level Deadlock),其中,行級死鎖分為①主鍵、唯一索引的死鎖(會話交叉插入相同的主鍵值),②外鍵未加索引,③表上的位圖索引遭到並發更新,④常見事務引發的死鎖(例如,兩個表之間不同順序相互更新操作引起的死鎖;同一張表刪除和更新之間引起的死鎖),⑤自治事務引發的死鎖。塊級死鎖主要指的是ITL(Interested Transaction List)死鎖。
死鎖分類圖如下所示:
圖2-3 死鎖的分類圖
行級鎖的發生如下圖所示,在A時間,TRANSACRION1和TRANSCTION2分別鎖住了它們要UPDATE的一行數據,沒有任何問題。但每個TRANSACTION都沒有終止。接下來在B時間,它們又試圖UPDATE當前正被對方TRANSACTION鎖住的行,因此雙方都無法獲得資源,此時就出現了死鎖。之所以稱之為死鎖,是因為無論每個TRANSACTION等待多久,這種鎖都不會被釋放。
行級鎖的死鎖一般是由於應用邏輯設計的問題造成的,其解決方法是通過分析trace文件定位出造成死鎖的SQL語句、被互相鎖住資源的對象及其記錄等信息,提供給應用開發人員進行分析,並修改特定或一系列表的更新(UPDATE)順序。
以下模擬各種行級死鎖的產生過程,版本都是11.2.0.4。
主鍵的死鎖其本質是唯一索引引起的死鎖,這個很容易模擬出來的,新建一張表,設置主鍵(或創建唯一索引)後插入一個值,然後不要COMMIT,另一個會話插入另一個值,也不要COMMIT,然後再把這兩個插入的值互相交換一下,在兩個會話中分別插入,死鎖就會產生。
會話1,sid為156:
SYS@lhrdb> set sqlprompt "_user'@'_connect_identifier S1> "
SYS@lhrdb S1> DROP TABLE T_DEADLOCK_PRIMARY_LHR;
Table dropped.
====>>>>> CREATE UNIQUE INDEX IDX_TEST_LHR ON T_DEADLOCK_PRIMARY_LHR(ID);
SYS@lhrdb S1> CREATE TABLE T_DEADLOCK_PRIMARY_LHR(ID NUMBER PRIMARY KEY);
Table created.
SYS@lhrdb S1> select userenv('sid') from dual;
USERENV('SID')
--------------
156
SYS@lhrdb S1> INSERT INTO T_DEADLOCK_PRIMARY_LHR VALUES(1);
1 row created.
SYS@lhrdb S1>
會話2,sid為156:
SYS@lhrdb> set sqlprompt "_user'@'_connect_identifier S2> "
SYS@lhrdb S2> select userenv('sid') from dual;
USERENV('SID')
--------------
191
SYS@lhrdb S2> INSERT INTO T_DEADLOCK_PRIMARY_LHR VALUES(2);
1 row created.
SYS@lhrdb S2> INSERT INTO T_DEADLOCK_PRIMARY_LHR VALUES(1);
====>>>>> 產生了阻塞
SELECT NVL(A.SQL_ID, A.PREV_SQL_ID) SQL_ID,
A.BLOCKING_SESSION,
A.SID,
A.SERIAL#,
A.LOGON_TIME,
A.EVENT
FROM GV$SESSION A
WHERE A.SID IN (156,191)
ORDER BY A.LOGON_TIME;
156阻塞了191會話,即會話1阻塞了會話2。
會話1再次插入數據:
SYS@lhrdb S1> INSERT INTO T_DEADLOCK_PRIMARY_LHR VALUES(2);
====>>>>> 產生了阻塞
此時,去會話2看的時候,已經報出了死鎖的錯誤:
此時的阻塞已經發生了變化:
告警日志:
Fri Sep 23 09:03:11 2016
ORA-00060: Deadlock detected. More info in file /oracle/app/oracle/diag/rdbms/lhrdb/lhrdb/trace/lhrdb_ora_25886852.trc.
其內容可以看到很經典的一段:
Deadlock graph:
---------Blocker(s)-------- ---------Waiter(s)---------
Resource Name process session holds waits process session holds waits
TX-0008000c-000008dc 38 191 X 29 156 S
TX-00030016-00000892 29 156 X 38 191 S
session 191: DID 0001-0026-00000115 session 156: DID 0001-001D-0000000D
session 156: DID 0001-001D-0000000D session 191: DID 0001-0026-00000115
Rows waited on:
Session 191: no row
Session 156: no row
這就是主鍵的死鎖,模擬完畢。
此時,若是會話2執行提交後,會話1就會報錯,違反唯一約束:
SYS@lhrdb S1> INSERT INTO T_DEADLOCK_PRIMARY_LHR VALUES(2);
INSERT INTO T_DEADLOCK_PRIMARY_LHR VALUES(2)
*
ERROR at line 1:
ORA-00001: unique constraint (SYS.SYS_C0011517) violated
會話1:
DROP TABLE T_DEADLOCK_PRIMARY_LHR;
CREATE TABLE T_DEADLOCK_PRIMARY_LHR(ID NUMBER PRIMARY KEY);
--CREATE UNIQUE INDEX IDX_TEST_LHR ON T_DEADLOCK_PRIMARY_LHR(ID);
select userenv('sid') from dual;
INSERT INTO T_DEADLOCK_PRIMARY_LHR VALUES(1);
會話2:
select userenv('sid') from dual;
INSERT INTO T_DEADLOCK_PRIMARY_LHR VALUES(2);
INSERT INTO T_DEADLOCK_PRIMARY_LHR VALUES(1);
會話1:---死鎖產生
INSERT INTO T_DEADLOCK_PRIMARY_LHR VALUES(2);
SELECT NVL(A.SQL_ID, A.PREV_SQL_ID) SQL_ID,
A.BLOCKING_SESSION,
A.SID,
A.SERIAL#,
A.LOGON_TIME,
A.EVENT
FROM GV$SESSION A
WHERE A.SID IN (156,191)
ORDER BY A.LOGON_TIME;
外鍵未加索引很容易導致死鎖。在以下兩種情況下,Oracle在修改父表後會對子表加一個全表鎖:
1. 如果更新了父表的主鍵,由於外鍵上沒有索引,所以子表會被鎖住。
2. 如果刪除了父表中的一行,由於外鍵上沒有索引,整個子表也會被鎖住。
總之,就是更新或者刪除父表的主鍵,都會導致對其子表加一個全表鎖。
如果父表存在刪除記錄或者更改外鍵列的情形,那麼就需要在子表上為外鍵列創建索引。
除了全表鎖外,在以下情況下,未加索引的外鍵也可能帶來問題:
1. 如果有ON DELETE CASCADE,而且沒有對子表加索引:例如,EMP是DEPT的子表,DELETE DEPTNO = 10應該CASCADE(級聯)至EMP[4]。如果EMP中的DEPTNO沒有索引,那麼刪除DEPT表中的每一行時都會對EMP做一個全表掃描。這個全表掃描可能是不必要的,而且如果從父表刪除多行,父表中每刪除一行就要掃描一次子表。
2. 從父表查詢子表:再次考慮EMP/DEPT例子。利用DEPTNO查詢EMP表是相當常見的。如果頻繁地運行以下查詢(例如,生成一個報告),你會發現沒有索引會使查詢速度變慢:
SELECT * FROM DEPT, EMP
WHERE EMP.DEPTNO = DEPT.DEPTNO
AND DEPT.DEPTNO = :X;
那麼,什麼時候不需要對外鍵加索引呢?答案是,一般來說,當滿足以下條件時不需要加索引:
1. 沒有從父表刪除行。
2. 沒有更新父表的惟一鍵/主鍵值。
3. 沒有從父表聯結子表。
如果滿足上述全部3個條件,那你完全可以跳過索引,不需要對外鍵加索引。不過個人還是強烈建議對子表添加索引,既然已經創建了外鍵,就不在乎再多一個索引吧,因為一個索引所增加的代價比如死鎖,與缺失這個索引所帶來的問題相比,是微不足道的。
子表上為外鍵列建立索引,可以:
1)提高針對外鍵列的查詢或改動性能
2)減小表級鎖粒度,降低死鎖發生的可能性
外鍵的死鎖可以這樣通俗的理解:有兩個表A和B:A是父表,B是子表。如果沒有在B表中的外鍵加上索引,那麼A表在更新或者刪除主鍵時,都會在表B上加一個全表鎖。這是為什麼呢?因為我們沒有給外鍵加索引,在更新或者刪除A表主鍵的時候,需要查看子表B中是否有對應的記錄,以判斷是否可以更新刪除。那如何查找呢?當然只能在子表B中一條一條找了,因為我們沒有加索引嗎。既然要在子表B中一條一條地找,那就得把整個子表B都鎖定了。由此就會導致以上一系列問題。
實驗過程:
會話1首先建立子表和父表
SYS@lhrdb S1> CREATE TABLE T_DEADLOCK_P_LHR (ID NUMBER PRIMARY KEY, NAME VARCHAR2(30)); --父表的主鍵
Table created.
SYS@lhrdb S1> INSERT INTO T_DEADLOCK_P_LHR VALUES (1, 'A');
1 row created.
SYS@lhrdb S1> INSERT INTO T_DEADLOCK_P_LHR VALUES (2, 'B');
1 row created.
SYS@lhrdb S1> CREATE TABLE T_DEADLOCK_F_LHR (FID NUMBER, FNAME VARCHAR2(30), FOREIGN KEY (FID) REFERENCES T_DEADLOCK_P_LHR); --子表的外鍵
Table created.
SYS@lhrdb S1> INSERT INTO T_DEADLOCK_F_LHR VALUES (1, 'C');
1 row created.
SYS@lhrdb S1> INSERT INTO T_DEADLOCK_F_LHR VALUES (2, 'D');
1 row created.
SYS@lhrdb S1>
SYS@lhrdb S1> COMMIT;
Commit complete.
會話1執行一個刪除操作,這時候在子表和父表上都加了一個Row-X(SX)鎖
SYS@lhrdb S1> delete from T_DEADLOCK_F_LHR where FID=1;
1 row deleted.
SYS@lhrdb S1> delete from T_DEADLOCK_P_LHR where id=1;
1 row deleted.
查詢會話1的鎖信息:
SELECT LK.SID,
DECODE(LK.TYPE,
'TX',
'Transaction',
'TM',
'DML',
'UL',
'PL/SQL User Lock',
LK.TYPE) LOCK_TYPE,
DECODE(LK.LMODE,
0,
'None',
1,
'Null',
2,
'Row-S (SS)',
3,
'Row-X (SX)',
4,
'Share',
5,
'S/Row-X (SSX)',
6,
'Exclusive',
TO_CHAR(LK.LMODE)) MODE_HELD,
DECODE(LK.REQUEST,
0,
'None',
1,
'Null',
2,
'Row-S (SS)',
3,
'Row-X (SX)',
4,
'Share',
5,
'S/Row-X (SSX)',
6,
'Exclusive',
TO_CHAR(LK.REQUEST)) MODE_REQUESTED,
OB.OBJECT_TYPE,
OB.OBJECT_NAME,
LK.BLOCK,
SE.LOCKWAIT
FROM V$LOCK LK, DBA_OBJECTS OB, V$SESSION SE
WHERE LK.TYPE IN ('TM', 'UL')
AND LK.SID = SE.SID
AND LK.ID1 = OB.OBJECT_ID(+)
AND SE.SID IN (156,191)
ORDER BY SID;
BLOCK為0表示沒有阻塞其它的鎖。
會話2:執行另一個刪除操作,發現這時候第二個刪除語句等待
SYS@lhrdb S2> delete from T_DEADLOCK_F_LHR where FID=2;
1 row deleted.
SYS@lhrdb S2> delete from T_DEADLOCK_P_LHR where id=2;
====>>>>> 產生了阻塞
BLOCK為1表示阻塞了其它的鎖。
會話1執行刪除語句,死鎖發生
SYS@lhrdb S1> delete from T_DEADLOCK_P_LHR where id=1;
====>>>>> 產生了阻塞,而會話2產生了死鎖
SYS@lhrdb S2> delete from T_DEADLOCK_P_LHR where id=2;
delete from T_DEADLOCK_P_LHR where id=2
*
ERROR at line 1:
ORA-00060: deadlock detected while waiting for resource
告警日志:
Fri Sep 23 10:31:10 2016
ORA-00060: Deadlock detected. More info in file /oracle/app/oracle/diag/rdbms/lhrdb/lhrdb/trace/lhrdb_ora_25886852.trc.
查看內容:
*** 2016-09-23 10:31:10.212
DEADLOCK DETECTED ( ORA-00060 )
[Transaction Deadlock]
The following deadlock is not an ORACLE error. It is a
deadlock due to user error in the design of an application
or from issuing incorrect ad-hoc SQL. The following
information may aid in determining the deadlock:
Deadlock graph:
---------Blocker(s)-------- ---------Waiter(s)---------
Resource Name process session holds waits process session holds waits
TM-00017731-00000000 38 191 SX SSX 29 156 SX SSX
TM-00017731-00000000 29 156 SX SSX 38 191 SX SSX
session 191: DID 0001-0026-00000115 session 156: DID 0001-001D-0000000D
session 156: DID 0001-001D-0000000D session 191: DID 0001-0026-00000115
Rows waited on:
Session 191: no row
Session 156: no row
回滾會話建立外鍵列上的索引:
SYS@lhrdb S1> rollback;
Rollback complete.
SYS@lhrdb S1> create index ind_p_f_fid on T_DEADLOCK_F_LHR(fid);
Index created.
重復上面的步驟會話1刪除子表記錄:
---會話1:
SYS@lhrdb S1> delete from T_DEADLOCK_F_LHR where FID=1;
1 row deleted.
SYS@lhrdb S1> delete from T_DEADLOCK_P_LHR where id=1;
1 row deleted.
SYS@lhrdb S1>
---會話2:
SYS@lhrdb S2> delete from T_DEADLOCK_F_LHR where FID=2;
1 row deleted.
SYS@lhrdb S2> delete from T_DEADLOCK_P_LHR where id=2;
1 row deleted.
所有的刪除操作都可以成功執行,也沒有阻塞的生成,重點就是在外鍵列上建立索引。
--主表
DROP TABLE T_DEADLOCK_P_LHR;
CREATE TABLE T_DEADLOCK_P_LHR (ID NUMBER PRIMARY KEY, NAME VARCHAR2(30)); --父表的主鍵
INSERT INTO T_DEADLOCK_P_LHR VALUES (1, 'A');
INSERT INTO T_DEADLOCK_P_LHR VALUES (2, 'B');
--子表
DROP TABLE T_DEADLOCK_F_LHR;
CREATE TABLE T_DEADLOCK_F_LHR (FID NUMBER, FNAME VARCHAR2(30), FOREIGN KEY (FID) REFERENCES T_DEADLOCK_P_LHR); --子表的外鍵
INSERT INTO T_DEADLOCK_F_LHR VALUES (1, 'C');
INSERT INTO T_DEADLOCK_F_LHR VALUES (2, 'D');
COMMIT;
---執行一個刪除操作,這時候在子表和父表上都加了一個Row-S(SX)鎖
delete from T_DEADLOCK_F_LHR where FID=1;
delete from T_DEADLOCK_P_LHR where id=1;
---會話2:執行另一個刪除操作,發現這時候第二個刪除語句等待
delete from T_DEADLOCK_F_LHR where FID=2;
delete from T_DEADLOCK_P_LHR where id=2;
---會話1:死鎖發生
delete from T_DEADLOCK_P_LHR where id=1;
---回滾會話建立外鍵列上的索引:
create index ind_p_f_fid on T_DEADLOCK_F_LHR(fid);
--重復上面的步驟會話1刪除子表記錄:
---會話1:
delete from T_DEADLOCK_F_LHR where FID=1;
delete from T_DEADLOCK_P_LHR where id=1;
---會話2:執行另一個刪除操作,發現這時候第二個刪除語句等待
delete from T_DEADLOCK_F_LHR where FID=2;
delete from T_DEADLOCK_P_LHR where id=2;
表上的位圖索引遭到並發更新也很容易產生死鎖。在有位圖索引存在的表上面,其實很容易就引發阻塞與死鎖。這個阻塞不是發生在表上面,而是發生在索引上。因為位圖索引鎖定的范圍遠遠比普通的b-tree索引鎖定的范圍大。
SYS@lhrdb S1> CREATE TABLE T_DEADLOCK_BITMAP_LHR (ID NUMBER , NAME VARCHAR2(10));
Table created.
SYS@lhrdb S1> INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (1,'A');
1 row created.
SYS@lhrdb S1> INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (1,'B');
1 row created.
SYS@lhrdb S1> INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (1,'C');
1 row created.
SYS@lhrdb S1> INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (2,'A');
1 row created.
SYS@lhrdb S1> INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (2,'B');
1 row created.
SYS@lhrdb S1> INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (2,'C');
1 row created.
SYS@lhrdb S1> COMMIT;
Commit complete.
--那麼在ID列上建bitmap index的話,所有ID=1的會放到一個位圖中,所有ID=2的是另外一個位圖,而在執行DML操作的時候,鎖定的將是整個位圖中的所有行,而不僅僅是DML涉及到的行。由於鎖定的粒度變粗,bitmap index更容易導致死鎖的發生。
會話1:此時所有ID=1的行都被鎖定
SYS@lhrdb S1> CREATE BITMAP INDEX IDX_DEADLOCK_BITMAP_LHR ON T_DEADLOCK_BITMAP_LHR(ID);
Index created.
SYS@lhrdb S1> UPDATE T_DEADLOCK_BITMAP_LHR SET ID=3 WHERE ID=1 AND NAME='A';
1 row updated.
會話2:此時所有ID=2的行都被鎖定
SYS@lhrdb S2> UPDATE T_DEADLOCK_BITMAP_LHR SET ID=4 WHERE ID=2 AND NAME='A';
1 row updated.
會話1:此時會話被阻塞
SYS@lhrdb S1> UPDATE T_DEADLOCK_BITMAP_LHR SET ID=4 WHERE ID=2 AND NAME='B';
====>>>>> 產生了阻塞
會話2:會話被阻塞
SYS@lhrdb S2> UPDATE T_DEADLOCK_BITMAP_LHR SET ID=3 WHERE ID=1 AND NAME='B';
====>>>>> 產生了阻塞
再回到SESSION 1,發現系統檢測到了死鎖的發生
SYS@lhrdb S1> UPDATE T_DEADLOCK_BITMAP_LHR SET ID=4 WHERE ID=2 AND NAME='B';
UPDATE T_DEADLOCK_BITMAP_LHR SET ID=4 WHERE ID=2 AND NAME='B'
*
ERROR at line 1:
ORA-00060: deadlock detected while waiting for resource
告警日志:
Fri Sep 23 11:20:21 2016
ORA-00060: Deadlock detected. More info in file /oracle/app/oracle/diag/rdbms/lhrdb/lhrdb/trace/lhrdb_ora_19726460.trc.
內容:
*** 2016-09-23 11:26:51.264
DEADLOCK DETECTED ( ORA-00060 )
[Transaction Deadlock]
The following deadlock is not an ORACLE error. It is a
deadlock due to user error in the design of an application
or from issuing incorrect ad-hoc SQL. The following
information may aid in determining the deadlock:
Deadlock graph:
---------Blocker(s)-------- ---------Waiter(s)---------
Resource Name process session holds waits process session holds waits
TX-0009000e-00000b0f 29 156 X 38 191 S
TX-00070001-00000b2c 38 191 X 29 156 S
session 156: DID 0001-001D-0000000D session 191: DID 0001-0026-00000115
session 191: DID 0001-0026-00000115 session 156: DID 0001-001D-0000000D
Rows waited on:
Session 156: obj - rowid = 00017734 - AAAXc0AAAAAAAAAAAA
(dictionary objn - 96052, file - 0, block - 0, slot - 0)
Session 191: obj - rowid = 00017734 - AAAXc0AAAAAAAAAAAA
(dictionary objn - 96052, file - 0, block - 0, slot - 0)
死鎖發生的根本原因是對於資源的排他鎖定順序不一致。上面的試驗中,session1對於bitmap index中的2個位圖是先鎖定ID=1的位圖,然後請求ID=2的位圖,而在此之前ID=2的位圖已經被session2鎖定。session2則先鎖定ID=2的位圖,然後請求ID=2的位圖,而此前ID=1的位圖已經被session1鎖定。於是,session1等待session2釋放ID=2的位圖上的鎖,session2等待session1釋放ID=1的位圖上的鎖,死鎖就發生了
而如果我們創建的是普通的B*Tree index,重復上面的試驗則不會出現任何的阻塞和死鎖,這是因為鎖定的只是DML操作涉及到的行,而不是所有ID相同的行。
CREATE TABLE T_DEADLOCK_BITMAP_LHR (ID NUMBER , NAME VARCHAR2(10));
INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (1,'A');
INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (1,'B');
INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (1,'C');
INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (2,'A');
INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (2,'B');
INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (2,'C');
COMMIT;
CREATE BITMAP INDEX IDX_DEADLOCK_BITMAP_LHR ON T_DEADLOCK_BITMAP_LHR(ID);
--會話1:此時所有ID=1的行都被鎖定
UPDATE T_DEADLOCK_BITMAP_LHR SET ID=3 WHERE ID=1 AND NAME='A';
--會話2:此時所有ID=2的行都被鎖定
UPDATE T_DEADLOCK_BITMAP_LHR SET ID=4 WHERE ID=2 AND NAME='A';
--會話1:此時會話被阻塞
UPDATE T_DEADLOCK_BITMAP_LHR SET ID=4 WHERE ID=2 AND NAME='B';
--會話2:會話被阻塞,再回到SESSION 1,發現系統檢測到了死鎖的發生
UPDATE T_DEADLOCK_BITMAP_LHR SET ID=3 WHERE ID=1 AND NAME='B';
--會話1:
UPDATE T_DEADLOCK_BITMAP_LHR SET ID=4 WHERE ID=2 AND NAME='B';
UPDATE T_DEADLOCK_BITMAP_LHR SET ID=4 WHERE ID=2 AND NAME='B'
*
ERROR at line 1:
ORA-00060: deadlock detected while waiting for resource
如果你有兩個會話,每個會話都持有另一個會話想要的資源,此時就會出現死鎖(deadlock)。例如,如果我的數據庫中有兩個表A和B,每個表中都只有一行,就可以很容易地展示什麼是死鎖。我要做的只是打開兩個會話(例如,兩個SQL*Plus會話)。在會話A中更新表A,並在會話B中更新表B。現在,如果我想在會話B中更新表A,就會阻塞。會話A已經鎖定了這一行。這不是死鎖;只是阻塞而已。因為會話A還有機會提交或回滾,這樣會話B就能繼續。如果我再回到會話A,試圖更新表B,這就會導致一個死鎖。要在這兩個會話中選擇一個作為“犧牲品”,讓它的語句回滾。
想要更新表B的會話A還阻塞著,Oracle不會回滾整個事務。只會回滾與死鎖有關的某條語句。會話B仍然鎖定著表B中的行,而會話A還在耐心地等待這一行可用。收到死鎖消息後,會話B必須決定將表B上未執行的工作提交還是回滾,或者繼續走另一條路,以後再提交。一旦這個會話執行提交或回滾,另一個阻塞的會話就會繼續,好像什麼也沒有發生過一樣。
1、創建兩個簡單的表A和B,每個表中僅僅包含一個字段id。
[ZFZHLHRDB2:oracle]:/oracle>ORACLE_SID=raclhr2
[ZFZHLHRDB2:oracle]:/oracle>sqlplus / as sysdba
SQL*Plus: Release 11.2.0.4.0 Production on Mon Jun 20 09:40:24 2016
Copyright (c) 1982, 2013, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
With the Partitioning, Real Application Clusters, Automatic Storage Management, OLAP,
Data Mining and Real Application Testing options
SYS@raclhr2> select * from v$version;
BANNER
--------------------------------------------------------------------------------
Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
PL/SQL Release 11.2.0.4.0 - Production
CORE 11.2.0.4.0 Production
TNS for IBM/AIX RISC System/6000: Version 11.2.0.4.0 - Production
NLSRTL Version 11.2.0.4.0 - Production
SYS@raclhr2> show parameter cluster
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
cluster_database boolean TRUE
cluster_database_instances integer 2
cluster_interconnects string
SYS@raclhr2> create table A (id int);
Table created.
SYS@raclhr2> create table B (id int);
Table created.
2、每張表中僅初始化一條數據
SYS@raclhr2> insert into A values (1);
1 row created.
SYS@raclhr2> insert into B values (2);
1 row created.
SYS@raclhr2> commit;
Commit complete.
3、在第一個會話session1中更新表A中的記錄“1”為“10000”,不提交;在第二個會話session2中更新表B中的記錄“2”為“20000”,不提交
session1的情況:
SYS@raclhr2> insert into A values (1);
1 row created.
SYS@raclhr2> insert into B values (2);
1 row created.
SYS@raclhr2> commit;
Commit complete.
SYS@raclhr2> SELECT a.SID,
2 b.SERIAL# ,
3 c.SPID
4 FROM v$mystat a,
5 v$session b ,
6 v$process c
7 WHERE a.SID = b.SID
8 and b.PADDR=c.ADDR
9 AND rownum = 1;
SID SERIAL# SPID
---------- ---------- ------------------------
133 3 20906088
SYS@raclhr2> update A set id = 10000 where id = 1;
1 row updated.
session2的情況:
SYS@raclhr2> SELECT a.SID,
2 b.SERIAL# ,
3 c.SPID
4 FROM v$mystat a,
5 v$session b ,
6 v$process c
7 WHERE a.SID = b.SID
8 and b.PADDR=c.ADDR
9 AND rownum = 1;
SID SERIAL# SPID
---------- ---------- ------------------------
195 21 11010172
SYS@raclhr2> update B set id = 20000 where id = 2;
1 row updated.
SYS@raclhr2>
4、此時,沒有任何問題發生。OK,現在注意一下下面的現象,我們再回到會話session1中,更新表B的記錄,此時出現了會話阻塞,更新hang住不能繼續。
SYS@raclhr2> update B set id = 10000 where id = 2;
這裡出現了“鎖等待”(“阻塞”)的現象,原因很簡單,因為在session2中已經對這條數據執行過update操作沒有提交表示已經對該行加了行級鎖。
SYS@raclhr2> set line 9999
SYS@raclhr2> SELECT A.INST_ID,
2 A.SID,
3 A.SERIAL#,
4 A.SQL_ID,
5 A.BLOCKING_INSTANCE,
6 A.BLOCKING_SESSION,
7 A.EVENT
8 FROM gv$session a
9 WHERE a.USERNAME IS NOT NULL
10 and a.STATUS = 'ACTIVE'
11 and a.BLOCKING_SESSION IS NOT NULL ;
INST_ID SID SERIAL# SQL_ID BLOCKING_INSTANCE BLOCKING_SESSION EVENT
---------- ---------- ---------- ------------- ----------------- ---------------- ------------------------------
2 133 3 6k793mj0duubw 2 195 enq: TX - row lock contention
我們可以通過v$session視圖看到,實例2的195阻塞了實例2的133會話,即本實驗中的session2阻塞了session1。
6、接下來再執行一條SQL後死鎖就會產生了:在session2中,更新表A的記錄
SYS@raclhr2> update A set id = 10000 where id = 1;
這裡還是長時間的等待,但是這裡發生了死鎖,這個時候我們去第一個會話session1中看一下,原先一直在等待的SQL語句報了如下的錯誤:
SYS@raclhr2> update B set id = 10000 where id = 2;
update B set id = 10000 where id = 2
*
ERROR at line 1:
ORA-00060: deadlock detected while waiting for resource
若此時查詢v$session視圖可以看到實例2的133阻塞了實例2的195會話,即本實驗中的session1阻塞了session2,和剛剛的阻塞情況相反,說明oracle做了自動處理:
SYS@raclhr2> set line 9999
SYS@raclhr2> SELECT A.INST_ID,
2 A.SID,
3 A.SERIAL#,
4 A.SQL_ID,
5 A.BLOCKING_INSTANCE,
6 A.BLOCKING_SESSION,
7 A.EVENT
8 FROM gv$session a
9 WHERE a.USERNAME IS NOT NULL
10 and a.STATUS = 'ACTIVE'
11 and a.BLOCKING_SESSION IS NOT NULL ;
INST_ID SID SERIAL# SQL_ID BLOCKING_INSTANCE BLOCKING_SESSION EVENT
---------- ---------- ---------- ------------- ----------------- ---------------- ------------------------------
2 195 21 5q7t3877fdu3n 2 133 enq: TX - row lock contention
更進一步:查看一下alert警告日志文件發現有如下的記錄:
Mon Jun 20 10:10:56 2016
Global Enqueue Services Deadlock detected. More info in file
/u01/app/oracle/diag/rdbms/raclhr/raclhr2/trace/raclhr2_lmd0_19923170.trc.
若是單機環境,報警日志為:
ORA-00060: Deadlock detected. More info in file /oracle/app/oracle/diag/rdbms/dlhr/dlhr/trace/dlhr_ora_16973880.trc.
可以看到該文件是由lmd進程生成的,為rac的特有進程,完成CacheFusion的作用,再進一步:看看系統自動生成的trace文件中記錄了什麼:
user session for deadlock lock 0x70001001569c378
sid: 133 ser: 3 audsid: 4294967295 user: 0/SYS
flags: (0x41) USR/- flags_idl: (0x1) BSY/-/-/-/-/-
flags2: (0x40009) -/-/INC
pid: 60 O/S info: user: oracle, term: UNKNOWN, ospid: 20906088
image: oracle@ZFZHLHRDB2 (TNS V1-V3)
client details:
O/S info: user: oracle, term: pts/0, ospid: 16122014
machine: ZFZHLHRDB2 program: sqlplus@ZFZHLHRDB2 (TNS V1-V3)
application name: sqlplus@ZFZHLHRDB2 (TNS V1-V3), hash value=346557658
current SQL:
update B set id = 10000 where id = 2
DUMP LOCAL BLOCKER: initiate state dump for DEADLOCK
possible owner[60.20906088] on resource TX-00140013-0000072D
user session for deadlock lock 0x700010015138660
sid: 195 ser: 21 audsid: 4294967295 user: 0/SYS
flags: (0x41) USR/- flags_idl: (0x1) BSY/-/-/-/-/-
flags2: (0x40009) -/-/INC
pid: 46 O/S info: user: oracle, term: UNKNOWN, ospid: 11010172
image: oracle@ZFZHLHRDB2 (TNS V1-V3)
client details:
O/S info: user: oracle, term: pts/1, ospid: 16646154
machine: ZFZHLHRDB2 program: sqlplus@ZFZHLHRDB2 (TNS V1-V3)
application name: sqlplus@ZFZHLHRDB2 (TNS V1-V3), hash value=346557658
current SQL:
update A set id = 10000 where id = 1
DUMP LOCAL BLOCKER: initiate state dump for DEADLOCK
possible owner[46.11010172] on resource TX-000B0018-00000416
若是單機環境比較明顯:
[Transaction Deadlock]
The following deadlock is not an ORACLE error. It is a
deadlock due to user error in the design of an application
or from issuing incorrect ad-hoc SQL. The following
information may aid in determining the deadlock:
Deadlock graph:
---------Blocker(s)-------- ---------Waiter(s)---------
Resource Name process session holds waits process session holds waits
TX-000d0005-00000047 41 37 X 25 34 X
TX-0008000a-0000036b 25 34 X 41 37 X
session 37: DID 0001-0029-00000003session 34: DID 0001-0019-0000000D
session 34: DID 0001-0019-0000000Dsession 37: DID 0001-0029-00000003
Rows waited on:
Session 37: obj - rowid = 00015FE7 - AAAV/nAABAAAXeBAAA
(dictionary objn - 90087, file - 1, block - 96129, slot - 0)
Session 34: obj - rowid = 00015FE6 - AAAV/mAABAAAXZ5AAA
(dictionary objn - 90086, file - 1, block - 95865, slot - 0)
注意trace文件中的一行如下提示信息,說明一般情況下都是應用和人為的,和Oracle同學沒有關系:
The following deadlock is not an ORACLE error. It is a
deadlock due to user error in the design of an application
or from issuing incorrect ad-hoc SQL.
造成死鎖的原因就是多個線程或進程對同一個資源的爭搶或相互依賴。這裡列舉一個對同一個資源的爭搶造成死鎖的實例。
SYS@lhrdb S1> CREATE TABLE T_DEADLOCK_DU_LHR ( ID NUMBER, test VARCHAR(10) ) ;
Table created.
SYS@lhrdb S1> INSERT INTO T_DEADLOCK_DU_LHR VALUES(1,'test1');
1 row created.
SYS@lhrdb S1> INSERT INTO T_DEADLOCK_DU_LHR VALUES(2,'test2');
1 row created.
SYS@lhrdb S1> COMMIT;
Commit complete.
SYS@lhrdb S1> SELECT * FROM T_DEADLOCK_DU_LHR;
ID TEST
---------- ----------
1 test1
2 test2
會話1更新第一條記錄:
SYS@lhrdb S1> UPDATE T_DEADLOCK_DU_LHR T SET T.TEST=100 WHERE ID=1;
1 row updated.
會話2刪除第二條記錄:
SYS@lhrdb S2> DELETE FROM T_DEADLOCK_DU_LHR T WHERE ID=2;
1 row deleted.
接下來會話1更新第二條記錄,這是就產生了阻塞:
SYS@lhrdb S1> UPDATE T_DEADLOCK_DU_LHR T SET T.TEST=100 WHERE ID=2;
====>>>>> 產生了阻塞,會話2阻塞了會話1
會話2刪除第一條記錄:
SYS@lhrdb S2> DELETE FROM T_DEADLOCK_DU_LHR T WHERE ID=1;
====>>>>> 產生了阻塞,此時會話1產生死鎖
查看會話1:
SYS@lhrdb S1> UPDATE T_DEADLOCK_DU_LHR T SET T.TEST=100 WHERE ID=2;
UPDATE T_DEADLOCK_DU_LHR T SET T.TEST=100 WHERE ID=2
*
ERROR at line 1:
ORA-00060: deadlock detected while waiting for resource
SYS@lhrdb S1> SYS@lhrdb S1> SYS@lhrdb S1> SYS@lhrdb S1> SYS@lhrdb S1> SYS@lhrdb S1>
告警日志:
Fri Sep 23 15:10:55 2016
ORA-00060: Deadlock detected. More info in file /oracle/app/oracle/diag/rdbms/lhrdb/lhrdb/trace/lhrdb_ora_19726460.trc.
內容:
*** 2016-09-23 15:10:55.326
DEADLOCK DETECTED ( ORA-00060 )
[Transaction Deadlock]
The following deadlock is not an ORACLE error. It is a
deadlock due to user error in the design of an application
or from issuing incorrect ad-hoc SQL. The following
information may aid in determining the deadlock:
Deadlock graph:
---------Blocker(s)-------- ---------Waiter(s)---------
Resource Name process session holds waits process session holds waits
TX-00090008-00000b0c 29 156 X 38 191 X
TX-000a0007-00000d28 38 191 X 29 156 X
session 156: DID 0001-001D-0000000D session 191: DID 0001-0026-00000115
session 191: DID 0001-0026-00000115 session 156: DID 0001-001D-0000000D
Rows waited on:
Session 156: obj - rowid = 0001773F - AAAXc/AABAABc2RAAB
(dictionary objn - 96063, file - 1, block - 380305, slot - 1)
Session 191: obj - rowid = 0001773F - AAAXc/AABAABc2RAAA
(dictionary objn - 96063, file - 1, block - 380305, slot - 0)
一般來說構成死鎖至少需要兩個會話,而自治事務是一個會話可能引發死鎖。
自治事務死鎖情景:存儲過程INSERT表A,然後INSERT表B;其中INSERT表A觸發TRIGGER T,T也INSERT表B,T是自治事務(AT),AT試圖獲取對B的鎖,結果B已經被主事務所HOLD,這裡會報出來ORA-00060 – 等待資源時檢查到死鎖.
解決方法:去掉了T中的PRAGMA AUTONOMOUS_TRANSACTION聲明,保持和存儲過程事務一致.
在主事務中如果更新了部分記錄,這時若自治事務更新同樣的記錄,就會造成死鎖,下面通過一個簡單的例子模擬了這個錯誤的產生:
SYS@lhrdb S1> CREATE TABLE T_DEADLOCK_AT2_LHR(ID NUMBER, NAME VARCHAR2(30));
Table created.
SYS@lhrdb S1> INSERT INTO T_DEADLOCK_AT2_LHR SELECT ROWNUM, TNAME FROM TAB WHERE ROWNUM<=4;
4 rows created.
SYS@lhrdb S1> COMMIT;
Commit complete.
SYS@lhrdb S1> CREATE OR REPLACE PROCEDURE PRO_TESTAT_LHR AS
2 PRAGMA AUTONOMOUS_TRANSACTION;
3 BEGIN
4 UPDATE T_DEADLOCK_AT2_LHR SET NAME = NAME WHERE ID = 1;
5 COMMIT;
6 END;
7 /
Procedure created.
SYS@lhrdb S1> UPDATE T_DEADLOCK_AT2_LHR SET NAME = NAME WHERE ID = 1;
1 row updated.
SYS@lhrdb S1> EXEC PRO_TESTAT_LHR;
BEGIN PRO_TESTAT_LHR; END;
*
ERROR at line 1:
ORA-00060: deadlock detected while waiting for resource
ORA-06512: at "SYS.PRO_TESTAT_LHR", line 4
ORA-06512: at line 1
SYS@lhrdb S1> SYS@lhrdb S1>
在使用自治事務的時候要避免當前事務鎖定的記錄和自治事務中鎖定的記錄相互沖突。
告警日志:
Fri Sep 23 14:03:10 2016
ORA-00060: Deadlock detected. More info in file /oracle/app/oracle/diag/rdbms/lhrdb/lhrdb/trace/lhrdb_ora_19726460.trc.
內容:
*** 2016-09-23 14:10:34.974
DEADLOCK DETECTED ( ORA-00060 )
[Transaction Deadlock]
The following deadlock is not an ORACLE error. It is a
deadlock due to user error in the design of an application
or from issuing incorrect ad-hoc SQL. The following
information may aid in determining the deadlock:
Deadlock graph:
---------Blocker(s)-------- ---------Waiter(s)---------
Resource Name process session holds waits process session holds waits
TX-000a0015-00000d25 38 191 X 38 191 X
session 191: DID 0001-0026-00000115 session 191: DID 0001-0026-00000115
Rows waited on:
Session 191: obj - rowid = 0001773A - AAAXc6AABAABc2BAAA
(dictionary objn - 96058, file - 1, block - 380289, slot - 0)
----- Information for the OTHER waiting sessions -----
----- End of information for the OTHER waiting sessions -----
Information for THIS session:
----- Current SQL Statement for this session (sql_id=3w3thujdh1y3a) -----
UPDATE T_DEADLOCK_AT2_LHR SET NAME = NAME WHERE ID = 1
----- PL/SQL Stack -----
----- PL/SQL Call Stack -----
object line object
handle number name
700010052c9cf40 4 procedure SYS.PRO_TESTAT_LHR
700010052cb7588 1 anonymous block
CREATE TABLE T_DEADLOCK_AT2_LHR(ID NUMBER, NAME VARCHAR2(30));
INSERT INTO T_DEADLOCK_AT2_LHR SELECT ROWNUM, TNAME FROM TAB WHERE ROWNUM<=4;
COMMIT;
CREATE OR REPLACE PROCEDURE PRO_TESTAT_LHR AS
PRAGMA AUTONOMOUS_TRANSACTION;
BEGIN
UPDATE T_DEADLOCK_AT2_LHR SET NAME = NAME WHERE ID = 1;
COMMIT;
END;
/
UPDATE T_DEADLOCK_AT2_LHR SET NAME = NAME WHERE ID = 1;
exec PRO_TESTAT_LHR;
ERROR AT LINE 1:
ORA-00060: DEADLOCK DETECTED WHILE WAITING FOR RESOURCE
ORA-06512: AT "SYS.PRO_TESTAT_LHR", LINE 4
ORA-06512: AT LINE 3
主事務和自治事務插入的是同一個主鍵值也會引起死鎖。
SYS@lhrdb S1> CREATE TABLE T_DEADLOCK_AT_LHR(X INT PRIMARY KEY,Y INT);
Table created.
SYS@lhrdb S1> CREATE OR REPLACE PROCEDURE PRO_AUTO_PROC_LHR(P_X INT,P_Y INT) AS
2 PRAGMA AUTONOMOUS_TRANSACTION;
3 BEGIN
4 INSERT INTO T_DEADLOCK_AT_LHR(X,Y) VALUES(P_X,P_Y);
5 COMMIT;
6 END;
7 /
Procedure created.
SYS@lhrdb S1> INSERT INTO T_DEADLOCK_AT_LHR(X,Y) VALUES(1,1);
1 row created.
SYS@lhrdb S1> EXEC PRO_AUTO_PROC_LHR(1,2);
BEGIN PRO_AUTO_PROC_LHR(1,2); END;
*
ERROR at line 1:
ORA-00060: deadlock detected while waiting for resource
ORA-06512: at "SYS.PRO_AUTO_PROC_LHR", line 4
ORA-06512: at line 1
告警日志:
Fri Sep 23 13:49:06 2016
ORA-00060: Deadlock detected. More info in file /oracle/app/oracle/diag/rdbms/lhrdb/lhrdb/trace/lhrdb_ora_19726460.trc.
內容:
*** 2016-09-23 13:49:06.546
DEADLOCK DETECTED ( ORA-00060 )
[Transaction Deadlock]
The following deadlock is not an ORACLE error. It is a
deadlock due to user error in the design of an application
or from issuing incorrect ad-hoc SQL. The following
information may aid in determining the deadlock:
Deadlock graph:
---------Blocker(s)-------- ---------Waiter(s)---------
Resource Name process session holds waits process session holds waits
TX-000a000b-00000d28 29 156 X 29 156 S
session 156: DID 0001-001D-0000000D session 156: DID 0001-001D-0000000D
Rows waited on:
Session 156: no row
----- Information for the OTHER waiting sessions -----
----- End of information for the OTHER waiting sessions -----
Information for THIS session:
----- Current SQL Statement for this session (sql_id=4fv0tmjrzv28u) -----
INSERT INTO T_DEADLOCK_AT_LHR(X,Y) VALUES(:B2 ,:B1 )
----- PL/SQL Stack -----
----- PL/SQL Call Stack -----
object line object
handle number name
70001005a9a0580 4 procedure SYS.PRO_AUTO_PROC_LHR
700010052d18b90 1 anonymous block
可以看到,等待的和持有鎖的是同一個會話,根據trace信息記錄的對象,發現問題是自治事務導致的。
CREATE TABLE T_DEADLOCK_AT_LHR(X INT PRIMARY KEY,Y INT);
CREATE OR REPLACE PROCEDURE PRO_AUTO_PROC_LHR(P_X INT,P_Y INT) AS
PRAGMA AUTONOMOUS_TRANSACTION;
BEGIN
INSERT INTO T_DEADLOCK_AT_LHR(X,Y) VALUES(P_X,P_Y);
COMMIT;
END;
/
INSERT INTO T_DEADLOCK_AT_LHR(X,Y) VALUES(1,1);
SQL> EXEC PRO_AUTO_PROC_LHR(1,2);
BEGIN AUTO_PROC(1,2); END;
*
ERROR AT LINE 1:
ORA-00060: DEADLOCK DETECTED WHILE WAITING FOR RESOURCE
ORA-06512: AT "BOCNET.AUTO_PROC", LINE 4
ORA-06512: AT LINE 1
塊級死鎖其實指的就是ITL死鎖。
ITL(Interested Transaction List)是Oracle數據塊內部的一個組成部分,用來記錄該塊所有發生的事務,有的時候也叫ITL槽位。如果一個事務一直沒有提交,那麼,這個事務將一直占用一個ITL槽位,ITL裡面記錄了事務信息、回滾段的入口和事務類型等等。如果這個事務已經提交,那麼,ITL槽位中還保存有這個事務提交時候的SCN號。ITL的個數受表的存儲參數INITRANS控制,在一個塊內部,默認分配了2個ITL的個數,如果這個塊內還有空閒空間,那麼Oracle是可以利用這些空閒空間再分配ITL。如果沒有了空閒空間,那麼,這個塊因為不能分配新的ITL,所以,就可能發生ITL等待。如果在並發量特別大的系統中,那麼最好分配足夠的ITL個數,或者設置足夠的PCTFREE,保證ITL能擴展,但是PCTFREE有可能是被行數據給消耗掉的,例如UPDATE,所以,也有可能導致塊內部的空間不夠而導致ITL等待,出現了ITL等待就可能導致ITL死鎖。
如果DUMP一個塊(命令:alter system dump datafile X block XXX;),那麼在DUMP文件中就可以看到ITL信息:
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0008.002.000009e9 0x00c0108b.04ac.24 --U- 3 fsc 0x0000.00752951
0x02 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
1) Itl: ITL事務槽編號,ITL事務槽號的流水編號
2) Xid:代表對應的事務id(transac[X]tion identified),在回滾段事務表中有一條記錄和這個事務對應。Xid由三列使用十六進制編碼的數字列表示,分別是:Undo Segment Number +Transaction Table Slot Number+ Wrap,即由undo段號+undo槽號+undo槽號的覆蓋次數三部分組成,即usn.slot.sqn,這裡0x0008.002.000009e9轉換為10進制為8.2.2537,從下邊的查詢出的結果是相對應的。
SYS@lhrdb> select xidusn,xidslot,xidsqn,ubafil,ubablk,ubasqn,ubarec from v$transaction;
XIDUSN XIDSLOT XIDSQN UBAFIL UBABLK UBASQN UBAREC
---------- ---------- ---------- ---------- ---------- ---------- ----------
8 2 2537 3 4235 1196 36
3) Uba:(Undo Block Address),該事務對應的回滾段地址,記錄了最近一次的該記錄的前鏡像(修改前的值)。Uba組成:Undo塊地址(undo文件號和數據塊號)+回滾序列號+回滾記錄號。多版本一致讀是Oracle保證讀操作不會被事務阻塞的重要特性。當Server Process需要查詢一個正在被事務修改,但是尚未提交的數據時,就根據ITL上的uba定位到對應Undo前鏡像數據位置。這裡的Uba為:0x00c0108b.04ac.24,其中00c0108b(16進制)=0000 0000 1100 0000 0001 0000 1000 1011(2進制,共32位,前10位代表文件號,後22位代表數據塊號)=文件號為3,塊號為4235:(10進制);04ac(16進制)=1196(10進制);24(16進制)=36(10進制)。這個結果和v$transaction查詢出來的結果一致。
SELECT UBAFIL 回滾段文件號,UBABLK 數據塊號,UBASQN 回滾序列號,UBAREC 回滾記錄號 FROM v$transaction ; --查看UBA
4) Flag:事務標志位,即當前事務槽的狀態信息。這個標志位就記錄了這個事務的操作狀態,各個標志的含義分別是:
標識
簡介
----
事務是活動的,未提交,或者在塊清除前提交事務
C---
transaction has been committed and locks cleaned out --事務已經提交,鎖已經被清除(提交)
-B--
this undo record contains the undo for this ITL entry
--U-
transaction committed (maybe long ago); SCN is an upper bound --事務已經提交,但是鎖還沒有清除(快速提交)
---T
transaction was still active at block cleanout SCN --塊清除的SCN被記錄時,該事務仍然是活動的,塊上如果有已經提交的事務,那麼在clean ount的時候,塊會被進行清除,但是這個塊裡面的事務不會被清除。
C-U-
塊被延遲清除,回滾段的信息已經改寫,SCN顯示為最小的SCN,需要由由回滾段重新生成,例如在提交以前,數據塊已經flush到數據文件上。
5) Lck:表示這個事務所影響的行數,鎖住了幾行數據,對應有幾個行鎖。我們看到01號事物槽Lck為3,因為該事物槽中的事物Flag為U,證明該事物已經提交,但是鎖還沒有清除。再比如對於下邊這個ITL:
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0006.020.00000271 0x00800205.0257.13 C--- 0 scn 0x0000.001732c4
0x02 0x0008.006.00000279 0x00800351.0278.15 ---- 1 fsc 0x0000.00000000
我們看到01號事物槽Lck為0,因為該事物槽中的事物Flag為C,證明該事物已經提交,鎖也被清楚掉了,該事物槽可以被重用了。02號事物槽Lck為1,是因為我對第一行做了一個更新,並且沒有提交,Flag為“----”說明該事物是活動的。
6) Scn/Fsc:Commit SCN或者快速提交(Fast Commit Fsc)的SCN。 Scn=SCN of commited TX; Fsc=Free space credit(bytes)每條記錄中的行級鎖對應Itl條目lb,對應於Itl列表中的序號,即那個事務在該記錄上產生的鎖。一個事物只有在提交之後才會在ITL事物槽中記錄SCN。
ITL的個數,受參數INITRANS控制,最大ITL個數受MAXTRANS控制(11g已廢棄MAXTRANS),在一個塊內部,默認分配了2個ITL的個數。ITL是block級的概念,一個ITL占用塊46B的空間,參數INITRANS意味著塊中除去block header外一部分存儲空間無法被記錄使用(46B*INITRANS),當塊中還有一定的FREE SPACE時,ORACLE可以使用FREE SPACE構建ITL供事務使用,如果這個塊內還有空閒空間,那麼Oracle是可以利用這些空閒空間並再分配ITL。如果沒有了空閒空間(free space),那麼,這個塊因為不能分配新的ITL,所以就可能發生ITL等待,即enq: TX - allocate ITL entry等待事件。注意:10g以後MAXTRANS參數被廢棄,默認最大支持255個並發。
如果在並發量特別大的系統中,最好分配足夠的ITL個數,其實它並浪費不了太多的空間,或者,設置足夠的PCTFREE,保證ITL能擴展,但是PCTFREE有可能是被行數據給消耗掉的,如UPDATE,所以,也有可能導致塊內部的空間不夠而導致ITL等待。
對於表(數據塊)來說,INITRANS這個參數的默認值是1。對於索引(索引塊)來說,這個參數默認值是2。
ITL等待表現出的等待事件為“TX - allocate ITL entry”,根據MOS(Troubleshooting waits for 'enq: TX - allocate ITL entry' (Doc ID 1472175.1)提供的解決辦法,需要修改一些參數,SQL如下,這裡假設用戶名為TLHR,表名為TLHRBOKBAL,表上的索引名為PK_TLHRBOKBAL:
ALTER TABLE TLHR.TLHRBOKBAL PCTFREE 20 INITRANS 16;
ALTER TABLE TLHR.TLHRBOKBAL MOVE NOLOGGING PARALLEL 12;
ALTER TABLE TLHR.TLHRBOKBAL LOGGING NOPARALLEL;
ALTER INDEX TLHR.PK_TLHRBOKBAL REBUILD PCTFREE 20 INITRANS 16 NOLOGGING PARALLEL 12;
ALTER INDEX TLHR.PK_TLHRBOKBAL LOGGING NOPARALLEL;
無MOS權限的朋友可以去http://blog.itpub.net/26736162/viewspace-2124531/閱讀。
由ITL不足引發的塊級死鎖的一個處理案例可以參考我的BLOG:http://blog.itpub.net/26736162/viewspace-2124771/、http://blog.itpub.net/26736162/viewspace-2124735/。
我們首先創建一張表T_ITL_LHR,這裡指定PCTFREE為0,INITRANS為1,就是為了觀察到ITL的真實等待情況,然後我們給這些塊內插入數據,把塊填滿,讓它不能有空間分配。
SYS@lhrdb21> SELECT * FROM V$VERSION;
BANNER
--------------------------------------------------------------------------------
Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
PL/SQL Release 11.2.0.4.0 - Production
CORE 11.2.0.4.0 Production
TNS for IBM/AIX RISC System/6000: Version 11.2.0.4.0 - Production
NLSRTL Version 11.2.0.4.0 - Production
SYS@lhrdb21> SHOW PARAMETER CLUSTER
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
cluster_database boolean TRUE
cluster_database_instances integer 2
cluster_interconnects string
SYS@lhrdb21> CREATE TABLE T_ITL_LHR(A INT) PCTFREE 0 INITRANS 1;
Table created.
SYS@lhrdb21> BEGIN
2 FOR I IN 1 .. 2000 LOOP
3 INSERT INTO T_ITL_LHR VALUES (I);
4 END LOOP;
5 END;
6 /
PL/SQL procedure successfully completed.
SYS@lhrdb21> COMMIT;
Commit complete.
我們檢查數據填充的情況:
SYS@lhrdb21> SELECT F, B, COUNT(*)
2 FROM (SELECT DBMS_ROWID.ROWID_RELATIVE_FNO(ROWID) F,
3 DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID) B
4 FROM T_ITL_LHR)
5 GROUP BY F, B
6 ORDER BY F,B;
F B COUNT(*)
---------- ---------- ----------
1 94953 734
1 94954 734
1 94955 532
可以發現,這2000條數據分布在3個塊內部,其中有2個塊(94953和94954)填滿了,一個塊(94955)是半滿的。因為有2個ITL槽位,我們需要拿2個滿的數據塊,4個進程來模擬ITL死鎖:
實驗步驟
會話
SID
要更新的塊號
要更新的行號
是否有阻塞
步驟一
1
19
94953
94953
1
N
2
79
2
N
3
78
94954
94954
1
N
4
139
2
N
會話1:
SYS@lhrdb21> SELECT USERENV('SID') FROM DUAL;
USERENV('SID')
--------------
19
SYS@lhrdb21> UPDATE T_ITL_LHR SET A=A
2 WHERE DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)=94953
3 AND DBMS_ROWID.ROWID_ROW_NUMBER(ROWID)=1;
1 row updated.
會話2:
SYS@lhrdb21> SELECT USERENV('SID') FROM DUAL;
USERENV('SID')
--------------
79
SYS@lhrdb21> UPDATE T_ITL_LHR SET A=A
2 WHERE DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)=94953
3 AND DBMS_ROWID.ROWID_ROW_NUMBER(ROWID)=2;
1 row updated.
會話3:
SYS@lhrdb21> SELECT USERENV('SID') FROM DUAL;
USERENV('SID')
--------------
78
SYS@lhrdb21> UPDATE T_ITL_LHR SET A=A
2 WHERE DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)=94954
3 AND DBMS_ROWID.ROWID_ROW_NUMBER(ROWID)=1;
1 row updated.
會話4:
SYS@lhrdb21> SELECT USERENV('SID') FROM DUAL;
USERENV('SID')
--------------
139
SYS@lhrdb21> UPDATE T_ITL_LHR SET A=A
2 WHERE DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)=94954
3 AND DBMS_ROWID.ROWID_ROW_NUMBER(ROWID)=2;
1 row updated.
這個時候系統不存在阻塞,
SELECT NVL(A.SQL_ID, A.PREV_SQL_ID) SQL_ID,
A.BLOCKING_SESSION,
A.SID,
A.SERIAL#,
A.LOGON_TIME,
A.EVENT
FROM GV$SESSION A
WHERE A.SID IN (19, 79,78,139)
ORDER BY A.LOGON_TIME;
以上4個進程把2個不同塊的4個ITL槽位給消耗光了,現在的情況,就是讓他們互相鎖住,達成死鎖條件,回到會話1,更新塊94954,注意,以上4個操作,包括以下的操作,更新的根本不是同一行數據,主要是為了防止出現的是行鎖等待。
實驗步驟
會話
SID
要更新的塊號
要更新的行號
是否有阻塞
步驟一
1
19
94953
94953
1
N
2
79
2
N
3
78
94954
94954
1
N
4
139
2
N
步驟二
1
19
94954
3
Y
3
78
94953
3
Y
會話1:
UPDATE T_ITL_LHR SET A=A
WHERE DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)=94954
AND DBMS_ROWID.ROWID_ROW_NUMBER(ROWID)=3;
會話1出現了等待。
會話3:
UPDATE T_ITL_LHR SET A=A
WHERE DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)=94953
AND DBMS_ROWID.ROWID_ROW_NUMBER(ROWID)=3;
會話3發現出現了等待。
我們查詢阻塞的具體情況:
SELECT NVL(A.SQL_ID, A.PREV_SQL_ID) SQL_ID,
A.BLOCKING_SESSION,
A.SID,
A.SERIAL#,
A.LOGON_TIME,
A.EVENT
FROM GV$SESSION A
WHERE A.SID IN (19, 79,78,139)
ORDER BY A.LOGON_TIME;
可以看到,會話1被會話4阻塞了,會話3被會話2阻塞了。
注意,如果是9i,在這裡就報死鎖了,但是在10g裡面,這個時候,死鎖是不會發生的,因為這裡的會話1還可以等待會話4釋放資源,會話3還可以等待會話2釋放資源,只要會話2與會話4釋放了資源,整個環境又活了,那麼我們需要把這兩個進程也塞住。
出現的是行鎖等待。
實驗步驟
會話
SID
要更新的塊號
要更新的行號
是否有阻塞
步驟一
1
19
94953
94953
1
N
2
79
2
N
3
78
94954
94954
1
N
4
139
2
N
步驟二
1
19
94954
3
Y
3
78
94953
3
Y
步驟三
2
79
94954
4
Y
4
139
94953
4
Y
會話2,注意,我們也不是更新的同一行數據:
UPDATE T_ITL_LHR SET A=A
WHERE DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)=94954
AND DBMS_ROWID.ROWID_ROW_NUMBER(ROWID)=4;
會話2出現了等待,具體阻塞情況:
我做了幾次實驗,會話2執行完SQL後,會話3到這裡就報出了死鎖,但有的時候並沒有產生死鎖,應該跟系統的阻塞順序有關,若沒有產生死鎖,我們可以繼續會話4的操作。
SYS@lhrdb21> UPDATE T_ITL_LHR SET A=A
2 WHERE DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)=94953
3 AND DBMS_ROWID.ROWID_ROW_NUMBER(ROWID)=3;
UPDATE T_ITL_LHR SET A=A
*
ERROR at line 1:
ORA-00060: deadlock detected while waiting for resource
會話4,注意,我們也不是更新的同一行數據:
UPDATE T_ITL_LHR SET A=A
WHERE DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)=94953
AND DBMS_ROWID.ROWID_ROW_NUMBER(ROWID)=4;
會話4發現出現了等待。
雖然,以上的每個更新語句,更新的都不是同一個數據行,但是,的確,所有的進程都被阻塞住了,那麼,死鎖的條件也達到了,等待一會(這個時間有個隱含參數來控制的:_lm_dd_interval),我們可以看到,會話2出現提示,死鎖:
SYS@lhrdb21> UPDATE T_ITL_LHR SET A=A
2 WHERE DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)=94954
3 AND DBMS_ROWID.ROWID_ROW_NUMBER(ROWID)=4;
UPDATE T_ITL_LHR SET A=A
*
ERROR at line 1:
ORA-00060: deadlock detected while waiting for resource
報出死鎖之後的阻塞情況:
我們可以在會話2上繼續執行步驟三中的SQL,依然會產生死鎖。生成死鎖後,在告警日志中有下邊的語句:
Fri Sep 09 17:56:55 2016
Global Enqueue Services Deadlock detected. More info in file
/oracle/app/oracle/diag/rdbms/lhrdb2/lhrdb21/trace/lhrdb21_lmd0_17039368.trc.
其中的內容有非常經典的一段Global Wait-For-Graph(WFG):
*** 2016-09-09 17:48:22.216
Submitting asynchronized dump request [1c]. summary=[ges process stack dump (kjdglblkrdm1)].
Global blockers dump end:-----------------------------------
Global Wait-For-Graph(WFG) at ddTS[0.395] :
BLOCKED 0x700010063d59b90 3 wq 2 cvtops x1001 TX 0x7000b.0xa67(ext 0x2,0x0)[1002-0029-00008387] inst 1
BLOCKER 0x700010063c6d268 3 wq 1 cvtops x28 TX 0x7000b.0xa67(ext 0x2,0x0)[1002-002D-00003742] inst 1
BLOCKED 0x700010063d5adc8 3 wq 2 cvtops x1 TX 0x30021.0x848(ext 0x2,0x0)[1002-002D-00003742] inst 1
BLOCKER 0x700010063d5a4b8 3 wq 1 cvtops x28 TX 0x30021.0x848(ext 0x2,0x0)[1002-0029-00008387] inst 1
該實驗過程可能有點復雜,小麥苗畫了個圖來說明整個實驗過程:
About Me
...............................................................................................................................
● 本文作者:小麥苗,只專注於數據庫的技術,更注重技術的運用
● 本文在itpub(http://blog.itpub.net/26736162)、博客園(http://www.cnblogs.com/lhrbest)和個人微信公眾號(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/viewspace-2127247/
● 本文博客園地址:http://www.cnblogs.com/lhrbest/p/6005702.html
● 本文pdf版及小麥苗雲盤地址:http://blog.itpub.net/26736162/viewspace-1624453/
● QQ群:230161599 微信群:私聊
● 聯系我請加QQ好友(642808185),注明添加緣由
● 於 2016-09-01 15:00 ~ 2016-10-20 19:00 在中行完成
● 文章內容來源於小麥苗的學習筆記,部分整理自網絡,若有侵權或不當之處還請諒解
● 【版權所有,文章允許轉載,但須以鏈接方式注明源地址,否則追究法律責任】
...............................................................................................................................
手機長按下圖識別二維碼或微信客戶端掃描下邊的二維碼來關注小麥苗的微信公眾號:xiaomaimiaolhr,免費學習最實用的數據庫技術。