對於表簇索引而言,必須使用表簇。
由於簇索引與索引表簇關聯緊密,無法單獨拿出來總結,因此一並進行總結。
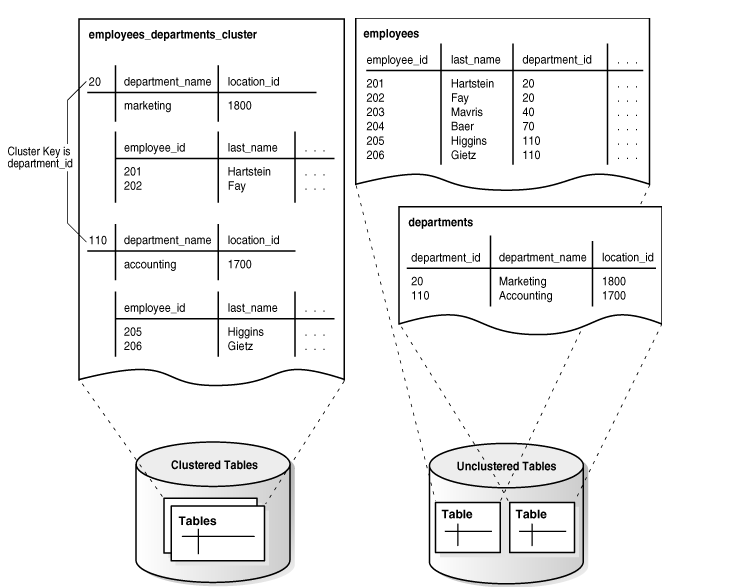
對於存在大量DML操作的表,不適合建立表簇。
對於需要經常進行全表掃描的表,不適合建立表簇。(不再像非簇表那樣,一個數據塊中僅包含一張表中的數據,還包含了與簇鍵相關的其他表數據行的數據,這意味著掃描簇中單獨的一張表,需要掃描更多的數據塊)
對於需要頻繁進行TRUNCATE操作的表,不適合建立表簇。(簇表中無法針對單獨的被簇表進行truncate操作)
此外,對於哈希表簇,不用也不能創建索引
--創建一個表簇
Yumiko@Sunny >create cluster clu_info_employee (deptno number) size 1024; Cluster created. Yumiko@Sunny >select * from tab where TNAME like '%CLU%'; TNAME TABTYPE CLUSTERID ------------------------------ ------- ---------- CLU_INFO_EMPLOYEE CLUSTER
--通過查詢user_clusters視圖(或者dba_clusters視圖),可以看到創建的表簇為index cluster,且SIZE設置為1024 Yumiko@Sunny >select cluster_name, tablespace_name, cluster_type, key_size from user_clusters; CLUSTER_NAME TABLESPACE_NAME CLUST KEY_SIZE ------------------------------ ------------------------------ ----- ---------- CLU_INFO_EMPLOYEE USERS INDEX 1024
--通過user_objects視圖(或者dba_objects視圖),同樣可以查閱cluster的信息。
--需要注意,同一個cluster下的對象,其DATA_OBJECT_ID的值一致。 Yumiko@Sunny >select OBJECT_ID,OBJECT_NAME,DATA_OBJECT_ID,OBJECT_TYPE from user_objects where OBJECT_NAME like '%CLU%'; OBJECT_ID OBJECT_NAME DATA_OBJECT_ID OBJECT_TYPE ---------- ------------------------- -------------- ------------------- 52626 CLU_INFO_EMPLOYEE 52626 CLUSTER
--通過user_clu_columns視圖可以看到,此時未顯示剛剛創建的cluster信息,表明該簇目前為空簇。 Yumiko@Sunny >select * from USER_CLU_COLUMNS; no rows selected
--此處應該注意到,通過dba_segments視圖查看,雖然當前是空簇,但已出現剛剛創建的cluster,證明此時已占用了空間。 Yumiko@Sunny >select SEGMENT_NAME,SEGMENT_TYPE, extents, HEADER_FILE, HEADER_BLOCK, BYTES, BLOCKS from dba_segments where owner='SCOTT' and segment_name like '%CLU%'; SEGMENT_NAME SEGMENT_TYPE EXTENTS HEADER_FILE HEADER_BLOCK BYTES BLOCKS ---------------------------------------------------------------------------------------- CLU_INFO_EMPLOYEE CLUSTER 1 4 395 65536 8
--創建簇表 Yumiko@Sunny >create table clu_info_dept(DEPTNO number,DNAME VARCHAR2(14),LOC VARCHAR2(13)) cluster CLU_INFO_EMPLOYEE(deptno); Table created. Yumiko@Sunny >create table clu_info_emp(DEPTNO number,ENAME VARCHAR2(10),JOB VARCHAR2(9)) cluster CLU_INFO_EMPLOYEE(deptno); Table created.
--查詢user_clu_columns視圖可以注意到,此時出現了簇及簇表的相應信息,說明此時,簇已不再是空簇。 Yumiko@Sunny >select * from USER_CLU_COLUMNS; CLUSTER_NAME CLU_COLUMN_NAME TABLE_NAME TAB_COLUMN_NAME ----------------------------------------------------------------------------------------- CLU_INFO_EMPLOYEE DEPTNO CLU_INFO_DEPT DEPTNO CLU_INFO_EMPLOYEE DEPTNO CLU_INFO_EMP DEPTNO Yumiko@Sunny >select * from tab where TNAME like '%CLU%'; TNAME TABTYPE CLUSTERID ------------------------------ ------- ---------- CLU_INFO_DEPT TABLE 1 CLU_INFO_EMP TABLE 2 CLU_INFO_EMPLOYEE CLUSTER
--同上面所說,查詢user_objects視圖可以看到簇的所有信息,此外可以注意到DATA_OBJECT_ID列是一致的,如前所說 Yumiko@Sunny >select OBJECT_ID,OBJECT_NAME,DATA_OBJECT_ID,OBJECT_TYPE from user_objects where OBJECT_NAME like '%CLU%'; OBJECT_ID OBJECT_NAME DATA_OBJECT_ID OBJECT_TYPE ---------- ------------------------- -------------- ------------------- 52627 CLU_INFO_DEPT 52626 TABLE 52628 CLU_INFO_EMP 52626 TABLE 52626 CLU_INFO_EMPLOYEE 52626 CLUSTER --查詢此時的dba_segments視圖,並未發現添加的兩張簇表 Yumiko@Sunny >select SEGMENT_NAME,SEGMENT_TYPE, extents, HEADER_FILE, HEADER_BLOCK, BYTES, BLOCKS from dba_segments where owner='SCOTT' and segment_name like '%CLU%'; SEGMENT_NAME SEGMENT_TYPE EXTENTS HEADER_FILE HEADER_BLOCK BYTES BLOCKS ------------------------------------------------------------------------------------ CLU_INFO_EMPLOYEE CLUSTER 1 4 395 65536 8
--查詢此時的dba_tables視圖,卻可以發現剛剛建立的表 Yumiko@Sunny >select TABLE_NAME,CLUSTER_NAME,STATUS from dba_tables where owner='SCOTT' and table_name like '%CLU%'; TABLE_NAME CLUSTER_NAME STATUS ------------------------------ ------------------------------ -------- CLU_INFO_EMP CLU_INFO_EMPLOYEE VALID CLU_INFO_DEPT CLU_INFO_EMPLOYEE VALID
--嘗試加載數據失敗,報錯明顯提示了未建立簇索引,也符合之前說過的創建順序 Yumiko@Sunny >insert into clu_info_dept select * from dept; insert into clu_info_dept select * from dept * ERROR at line 1: ORA-02032: clustered tables cannot be used before the cluster index is built
-- 創建簇索引,注意此時的關鍵字on cluster Yumiko@Sunny >create index CLU_INFO_index on cluster CLU_INFO_EMPLOYEE; Index created. --查詢此時的dba_segments視圖,同樣有索引的segments信息。 Yumiko@Sunny >select SEGMENT_NAME,SEGMENT_TYPE, extents, HEADER_FILE, HEADER_BLOCK, BYTES, BLOCKS from dba_segments where owner='SCOTT' and segment_name like '%CLU%'; SEGMENT_NAME SEGMENT_TYPE EXTENTS HEADER_FILE HEADER_BLOCK BYTES BLOCKS -------------------------------------------------------------------------------------- CLU_INFO_INDEX INDEX 1 4 403 65536 8 CLU_INFO_EMPLOYEE CLUSTER 1 4 395 65536 8 --加載數據 Yumiko@Sunny >insert into clu_info_dept select * from dept; 4 rows created.
--再次查詢dba_segments視圖,依然沒有cluster table的信息
Yumiko@Sunny >select SEGMENT_NAME,SEGMENT_TYPE, extents, HEADER_FILE, HEADER_BLOCK, BYTES, BLOCKS from dba_segments where owner='SCOTT' and segment_name like '%CLU%';
SEGMENT_NAME SEGMENT_TYPE EXTENTS HEADER_FILE HEADER_BLOCK BYTES BLOCKS -------------------------------------------------------------------------------------- CLU_INFO_INDEX INDEX 1 4 403 65536 8 CLU_INFO_EMPLOYEE CLUSTER 1 4 395 65536 8
此外,對於簇表本身的刪除,按照普通表方法即可。
下面引用oracle官方文檔的例子:
CREATE CLUSTER call_detail_cluster (
telephone_number NUMBER,
call_timestamp NUMBER SORT,
call_duration NUMBER SORT )
HASHKEYS 10000
HASH IS telephone_number
SIZE 256;
其中:
HASH IS參數:
HASHKEYS參數:
SIZE參數:
該參數越大,雖然單獨的數據塊可以容納的簇鍵會減少,甚至可能會由於單個簇鍵占用比實際需求更多的空間造成空間的浪費,但由於有更多的空間存儲更多的相關數據,只要設置合理,一
定程度上卻可以降低物理讀。