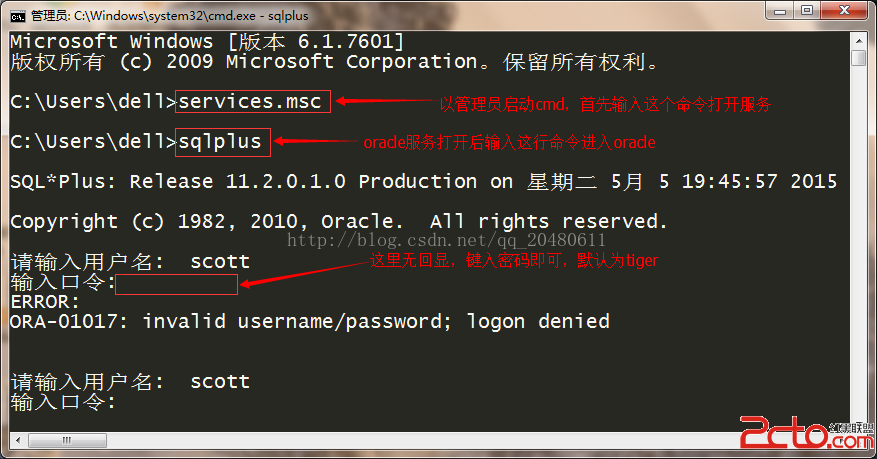
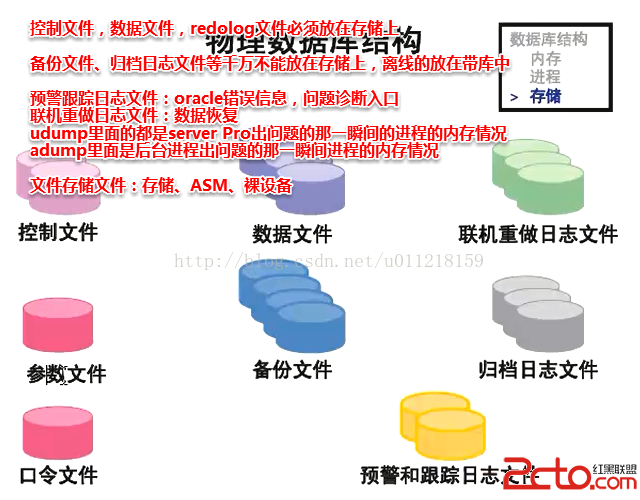
數據以堆的形式管理,增加數據時會使用段中找到的第一個能放下數據的自由空間,我們見到的絕大部分的表都是堆表。堆表是數據庫的默認表類型。
最簡單的情況是
create table test (c1 varchar2(10),c2 varchar2(24),c3 number(9,3)) ;然後使用tom kyte的方法,盡可能簡單的創建表,調用dbms_metadata.get_ddl函數,查看詳細定義,然後再根據這個詳細版本,定制自己想要的版本。
set long 5000
select dbms_metadata.get_ddl('TABLE','TEST') from dual;
CREATE TABLE "SCOTT"."TEST"
( "C1" VARCHAR2(10),
"C2" VARCHAR2(24),
"C3" NUMBER(9,3)
) SEGMENT CREATION DEFERRED
PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255
NOCOMPRESS LOGGING
TABLESPACE "USERS"11g以後的版本,段會延遲到插入數據才創建,如果想立即創建段使用segment creation immediate,默認為defereed
可以使用數據字典表dba_segments或者all_segments確認
create table test
(c1 varchar2(10),c2 varchar2(24),c3 number(9,3))
segment creation immediate ;如果不指定表空間,則使用表所在用戶的默認表空間。
指定表存儲在users表空間裡:
create table test (c1 varchar2(10),c2 varchar2(24),c3 number(9,3)) tablespace users;PCTUSED如果使用ASSM(自動段空間管理)的話,會被忽略,絕大部分情況是這樣的,oracle也推薦這樣。
PCTFREE用於在數據庫塊裡預留空間用於更新,單到達設置比例後不會有新行插入該塊,以免產生行遷移.
create table test (c1 varchar2(10),c2 varchar2(24),c3 number(9,3)) pctfree 20;initrans控制數據庫塊頭為事務預留的事務插槽個數,如果對該表進行插入和更新的事務非常多,建議將該值設置的稍微大一點。
create table test (c1 varchar2(10),c2 varchar2(24),c3 number(9,3)) initrans 10;使用什麼緩存池來緩存該表的塊
一般使用默認設置即可, 即default
對於訪問非常頻繁的表可以使用 keep池,(一般在其他優化手段測試後才使用這種方法),須首先設置db_keep_cache_size參數。
create table test (c1 varchar2(10),c2 varchar2(24),c3 number(9,3)) storage (buffer_pool keep);無論設置成那個在普通DML語句時都要產生日志文件,只有直接路徑DML才有區別。絕大部分情況使用logging(默認)。只有在大量加載數據的情況下使用nologging來加快數據的加載
create table test (c1 varchar2(10),c2 varchar2(24),c3 number(9,3)) nologging storage (buffer_pool keep);
在直接路徑加載或者傳統路徑加載啟用或者禁用壓縮。有nocompress(禁用壓縮),
compress對直接路徑插入有效
compress for oltp對直接路徑和一般路徑插入都有效
壓縮的效果一般都比較好,如果cpu資源允許的情況下,可以使用壓縮提高對數據庫緩沖區緩存的使用效率,可以放更加多的數據了,對於全表掃描較多的應用程序來說是一個很好的優化。但是相應的會增加cpu的使用,使用前應該進行相應的測試。測試會不會對數據插入,修改造成影響。非常適合一次寫入多次修改類型數據。
使用 select blocks,avg_row_length,num_rows,compression,compress_for from user_tables where table_name='xxxxx'
檢查壓縮前和壓縮後效果差異
可以在表創建時使用約束或者在表創建後增加、修改或者刪除約束
約束分為行內約束和行外約束,行內約束指的是在定義列時候一起定義該列相關的約束。行外約束指的是單獨一行定義約束。
create table test
(
c1 varchar2(10) primary key,
c2 varchar2(24) not null,
c3 number(9,3) constraint c3_check check(c3>100),
constarint c2_check check (c2 in ('China',
'Japan','USA'))
)
;其中primary key 、not null、 c3_check為行內約束,c2_check為行外約束
enable 表示啟用
disable 表示不啟用
validate 表示當前表中所有數據都被驗證了
novalidate 表示當前表中的數據沒有被驗證。
一般情況只需設置enable validate(默認)
其它組合用於對大數據進行ETL時使用節省時間
還有一個表示約束是延遲起效還是立即起效。延遲起效表示在commit完成時進行檢查約束是否正確,立即起效表示對該語句處理時進行判斷是否滿足約束
默認情況是立即起效
延遲起效的語法為
deferred initially immediate|deferred 只有這樣設置了的約束才能在事務控制時使用約束控制延遲。
表示該列可不可以為空
表示該列的值在表內必須唯一,但是可以為null
create table test
(
c1 varchar2(10),
c2 varchar2(24),
c3 number(9,3),
constraint pk_test primary key (c1,c2),
constraint uk_test unique (c3)
)
;這些鍵表示的值在全表唯一且不為空(主鍵的所有列都不能為null),可以由單列作為主鍵或者多列組合作為主鍵
create table test
(
c1 varchar2(10),
c2 varchar2(24),
c3 number(9,3),
constraint pk_test primary key (c1,c2)
)
;用於表示父子表,使用引用約束的表為子表,被引用約束的表為父表
create table parent
(
c1 varchar2(10),
c2 varchar2(24),
c3 number(9,3),
constraint pk_test primary key (c1,c2)
)
;
create table child
(
c1 varchar2(10),
c2 varchar2(24),
c3 number(9,3),
c4 number(9,3),
constraint fk_child foreign key (c1,c2) references parent(c1,c2)
)
;
//父表刪除一行,子表和其關聯的行被刪除
create table child1
(
c1 varchar2(10),
c2 varchar2(24),
c3 number(9,3),
c4 number(9,3),
constraint fk_child foreign key (c1,c2) references parent(c1,c2) on delete cascade
)
;
//父表刪除一行,子表和其關聯的行被刪除
create table child2
(
c1 varchar2(10),
c2 varchar2(24),
c3 number(9,3),
c4 number(9,3),
constraint fk_child foreign key (c1,c2) references parent(c1,c2) on delete set null
)
;引用約束還有一個和性能關系很大的條件,如果不對子表的引用列加上索引,當父表更新或者刪除時會鎖定整個子表。
用於檢查某些條件,大於,小於,在一個集合裡面等等
create table test
(c1 varchar2(10) primary key,
c2 varchar2(24),
c3 number(9,3),
constraint c2_c3_check check(c2 in ('China','USA') and c3>5.0)
enable validate) tablespace users pctfree 20 storage (buffer_pool keep);索引組織表是將數據存儲在索引結構裡。索引組織表中的數據按照主鍵存儲和排序。索引組織表首先是對於信息的獲取非常有利。其次由於是按索引進行存儲的,索引的前綴部分相同的鍵會存儲在一起。IOT表對於信息獲取,空間應用和OLAP相當有用。
IOT表有三個屬性很重要
compress N表示對索引的前N項提取公因子。在重復度很高的情況下壓縮性非常好。
可以對IOT表的主鍵使用
analyze index iot_pk validate structure;
然後查看index_stats表的opt_cmpr_count獲取最優N值。
表示行數據量超過塊大小的這個百分比時,剩余的列放到overflow裡去。
行中從第一列到該列為止都存儲在葉子塊裡,剩余的列放到overflow裡。
允許你創建另一個段,當數據行太長時溢出到這個段上來,以使IOT的葉子塊盡量容納更多的行。
分區鍵必須是主鍵的子集
create table line
(point_id varchar2(20),
line_id varchar2(20),
x number(10,3),
y number(10,3),
loc varchar2(20),
time date,
constraint pk_line primary key(line_id,point_id,time)
)
organization index
partition by range(time)
(partition p0 values less than (to_date('2016-1-1','yyyy-mm-dd'))
);使用including控制overflow
create table address
(
type varchar2(10),
location varchar2(200),
phone varchar2(20),
detail varchar2(800),
constraint pk_address primary key (type,location)
) organization index
including location overflow;
使用pctthreshold控制overflow
create table address
(
type varchar2(10),
location varchar2(200),
phone varchar2(20),
detail varchar2(800),
constraint pk_address primary key (type,location)
) organization index
pctthreshold 5 overflow;
使用including和pctthreshold的組合也是可以的,但是一般不是特別有用分區是將一個表或者索引分成多個更小,更可管理的部分。邏輯上將只有一個表或索引,對外部使用該表的人而言,就是一個表和普通表沒有任何分別,但是在物理上這一個表可以由多個分區組成,每個分區都是一個獨立的對象,可以單獨處理,或是作為一個更大的部分被處理。
指定存儲在一起的數據的區間,比如2016-3-1到2016-4-1的放在分區1,2016-4-1到2016-5-1的放在分區2,等等
常見使用方法有兩種,常規區間分區和間隔分區
但是不管是哪種分區方式,和普通表一樣,可以在表後面指定PCTFREE、INITRANS、存儲性質(基本上就是buffer_pool)、表空間等物理屬性。如果分區沒有覆寫這些屬性,則分區和表的這些性質保持一致
當然,每個分區後都可以指定PCTFREE、INITRANS、存儲性質(基本上就是buffer_pool)、表空間等物理屬性
語法結構為
partition by range (column_name)
(partition name1 values less than (value1),
partition name2 values less than (valuee2),
....
partition last_part values less than (maxvalue));最後一個小於maxvalue是為了讓所有情況都可以被表所包含。這裡的小於,指的是嚴格小於,等於不包含在內。
舉個例子
create table log
(
text varchar2(255),
rksj date
)
pctfree 20 storage(buffer_pool default)
partition by range(rksj)
(
partition part_2016_3 values less than (to_date('2016-3-1','yyyy-mm-dd')),
partition part_2016_4 values less than (to_date('2016-4-1','yyyy-mm-dd')) pctfree 10 storage(buffer_pool keep),
partition part_other values less than (maxvalue)
)
可以使用alter table修改分區的物理屬性
alter table log modify partition part_2016_3 storage(buffer_pool keep);間隔分區是從oracle 11gr1開始新增加的一個特性,以一個分區為起點,設置一個規則(間隔),讓oracle根據該規則知道以後該怎麼增加分區。這樣就不需要預先設置好所有的分區了,oracle在插入數據時知道自己去創建分區。間隔分區的鍵值應該是可以和number、interval進行相加的列。
對於任何合適的現有區間分區表,都可以使用alter table修改為間隔區間分區表。
語法
partition by range (column_name) interval (expr) store in (tablespace1,tablespace2,....)
(partition name1 values less than (value1),
partition name2 values less than (valuee2),
....);一般間隔分區只需創建一個起始分區即可.
create table log
(
text varchar2(255),
rksj date
)
pctfree 20 storage(buffer_pool default)
partition by range(rksj) interval (numtoyminterval(1,'month'))
(
partition part_2016_3 values less than (to_date('2016-3-1','yyyy-mm-dd'))
)11g開始oracle增加了interval分區,和range分區最大的區別就是它會根據數據自動去創建分區。
但是它有以下缺點
1. 第一個分區不能刪除,因為它是參考,刪除會報ora-14758錯誤。
2. 分區沒有便於管理的名稱
3. 如果創建索引時指定了多個分區,則這些分區之間是不會應用interval繼續分區了。只有大於這其中的值才會開始分區
4. 不能執行分區的循環使用??
ora-14758錯誤解決方法
先將間隔分區表轉化為普通range分區表
alter table table_name set interval ();
刪除指定分區後再將間隔設置回來
alter table table_name set interval (numtodsinterval(1,’DAY’));
散列分區是在一個列或者多個列上引用散列函數,行會按散列值放到不同的分區上去。oracle建議分區數應該是2的一個冪次方(2,4,8,16,。。。)。
散列分區的目的是讓數據很好的分布在多個不同的設備上,或者將數據聚集到更可管理的塊上,所以散列鍵應該是唯一的列或者至少有足夠的相異值。以便數據能在多個分區上均勻的分布。
partition by hash (column1,column2,...)
(
partition part1 tablespace ts_name1,
partition part2,
.....
)其它物理屬性不能在這裡設置。
或者
partition by hash (column1,column2,...) partitions n store in (ts_name1,ts_name2,...);create table log
(
id number(10),
text varchar2(255),
rksj date
)
partition by hash(id)
(
partition part1 tablespace users ,
partition part2,
partition part3 tablespace ts_test,
partition part4
);
create table log
(
id number(10),
text varchar2(255),
rksj date
)
partition by hash(id) partitions 4
store in (users,ts_test);
根據離散的值決定數據該放在哪個分區裡。
partition by list(column1,...)
(
partition part1 values (value1,value2),
partition part2 values (value3,value4),
.....
partition part_default (default)
)如果設置了default分區,則不能再增加分區了,只能刪除default分區才能增加分區
create table data
(
rawdata raw(200),
status varchar2(1)
)
partition by list(status)
(
partition part_u values ('u') tablespace users storage(buffer_pool keep),
partition part_p values ('p')tablespace ts_test,
partition part_def values (default)
);引用分區是oracle 11gr1引入的新特性,要以某種方式
對子表進行分區,使得子表的分區和父表的保持一對一的關系。
create table orders
(
order# number(10) primary key,
order_date date,
data varchar2(100)
)
partition by range(order_date)
(
partition part_2015 values less than (to_date('2016-1-1','yyyy-mm-dd')),
partition part_2016 values less than (to_date('2017-1-1','yyyy-mm-dd'))
);
create table order_items
(
order# number(10),
item# number(10),
price number(5,2),
description varchar2(200),
constraint pk_order_items primary key(order#,item#),
constraint fk_order_items foreign key(order#) references orders(order#)
)
partition by reference (fk_order_items);
的range,list和hash分區,在這些分區的基礎上再進行分區。
每種分區都可以進行range,list和hash子分區。
例子
在區間分區的基礎上散列分區
create table log
(
id number(10),
text varchar2(200),
logtime date,
type varchar2(1)
)
partition by range(logtime)
subpartition by hash(id) subpartitions 10 store in (users,ts_test)
(partition part_2015 values less than (to_date('2016-1-1','yyyy-mm-dd')),
partition part_2016 values less than (to_date('2017-1-1','yyyy-mm-dd'))
);
區間分區上列表分區
create table log
(
id number(10),
text varchar2(200),
logtime date,
type varchar2(1)
)
partition by range(logtime)
subpartition by list(type)
subpartition template
(
subpartition part_a values ('A') tablespace users,
subpartition part_b values ('B') tablespace ts_test,
subpartition part_cd values ('C','D') tablespace users
)
(partition part_2015 values less than (to_date('2016-1-1','yyyy-mm-dd')),
partition part_2016 values less than (to_date('2017-1-1','yyyy-mm-dd'))
);
create table log
(
id number(10),
text varchar2(200),
logtime date,
type varchar2(1)
)
partition by hash(id)
subpartition by list(type)
subpartition template
(
subpartition part_a values ('A') tablespace users,
subpartition part_b values ('B') tablespace ts_test,
subpartition part_cd values ('C','D') tablespace users
)
partitions 8 store in (users,ts_test)
;聚簇表的理念是將數據按照我們想要的方式(聚簇)將多個表預聯結在一起,即放在同一個塊上。聚簇也可用於單個表,按某個列
將數據分組存儲。
create cluster emp_dept_cluster
(deptno number(2))
size 1024;
select dbms_metadata.get_ddl('CLUSTER','EMP_DEPT_CLUSTER') from dual;
DBMS_METADATA.GET_DDL('CLUSTER','EMP_DEPT_CLUSTER')
--------------------------------------------------------------------------------
CREATE CLUSTER "SCOTT"."EMP_DEPT_CLUSTER" (
"DEPTNO" NUMBER(2,0) )
SIZE 1024
PCTFREE 10 PCTUSED 40 INITRANS 2 MAXTRANS 255
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1
BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "USERS"
PARALLEL (DEGREE 1 INSTANCES 1)其中size是聚簇最重要的一個參數,意思是每個鍵值大概關聯多大的空間,這裡是1024B,對於大小為8KB的塊可以放下7個鍵。如果設置的太大會浪費空間,如果設置太小又會過度串鏈,違背了聚簇就是為了將相關數據放在一起的本意。
向聚簇中放數據之前,首先要為聚簇創建索引,然後就可以創建聚簇表了。聚簇索引的任務就是拿到一個鍵值,然後返回包含這個鍵值的塊地址。
create index idx_emp_dept_cluster on cluster emp_dept_cluster;
create table dept
(deptno number(2),
dname varchar2(20),
loc varchar2(20))
cluster emp_dept_cluster(deptno);
create table emp
(
empno number(10) primary key,
name varchar2(20),
mgr number(10),
sal number(8,2),
deptno number(2)
)
cluster emp_dept_cluster(deptno);
聚簇表沒有tablespace這些段屬性,因為這些屬性都在聚簇上定義。
主要用於讀,且通過索引來讀,另外會頻繁的把信息聯結起來使用。
基本和索引聚簇表一樣,就是將索引換成了散列函數。oracle獲取一列的值,通過散列函數得到一個值,然後通過這個值獲得數據所在的塊。使用散列的缺點是無法進行 掃描,只要是范圍掃描則必須執行全表掃描。
散列聚簇表的塊數是預先分配好的。由散列聚簇表的hashkeys和size加上塊的大小得到,即trunc(hashkeys*size/blocksize)
create cluster hash_cluster
(hash_key number(10)
)
hashkeys 10000
size 8192
tablespace users;
create table hash_table1
(
x number(10),name varchar2(10)
) cluster hash_cluster(x);
create table hash_table2
(
x number(10),loc varchar2(10)
) cluster hash_cluster(x);散列聚簇表還可以使用單表散列聚簇表
create cluster hash_cluster
(hash_key number(10)
)
hashkeys 10000
size 8192
single table
tablespace users;
用於保存事務或者會話期間的中間結果。臨時表中保存的數據只對當前會話可見,分為兩種情況,一種是事務一結束數據就被清空。一種是事務結束後依然存在。使用臨時表生成的redo數據要少。
create global temporary med
(name varchar2(10),
phone varchar2(20)
)
on commit delete rows;
create global temporary med
(name varchar2(10),
phone varchar2(20)
)
on commit preserve rows;