原創 2016-07-05 熊軍 Oracle
編輯手記:在理解Oracle技術細節時,我們不僅應該讀懂概念,還要能夠通過測試驗證細節,理解那些『功夫在詩外』的部分,例如全表掃描和單塊讀。
開發人員在進行新系統上線前的數據校驗測試時,發現一條手工執行的 SQL 執行了超過1小時還沒有返回結果。SQL 很簡單:
下面是這條 SQL 的真實的執行計劃:
很顯然,在這個表上建 billing_nbr 和 start_date 的復合索引,這條 SQL 就能很快執行完(實際上最後也建了索引)。但是這裡我們要探討的是,為什麼這麼一條簡單的 SQL 語句,執行了超過1小時還沒有結果。 MOBILE_CALL_1204_OLD 這張表的大小約為 12GB ,以系統的 IO 能力,正常情況下不會執行這麼長的時間。簡單地看了一下,系統的 CPU 以及 IO 壓力都不高。假設單進程全表掃描表,每秒掃描 50MB 大小(這實際上是一個很保守的掃描速度了),那麼只需要245秒就可以完成掃描。
下面來診斷一下 SQL 為什麼會這麼不正常地慢。看看會話的等待(以下會用到 Oracle 大牛Tanel Poder的腳本):
明明是全表掃描的 SQL ,為什麼99%以上的等待時間是 db file sequential read ,即單塊讀?!多執行幾次 waitprof 腳本,得到的結果是一致的(注意這裡的數據,特別是平均等待時間並不一定是准確的值,這裡重點關注的是等待時間的分布)。
那麼 SQL 執行計劃為全表掃描(或索引快速全掃描)的時候,在運行時會有哪些情況實際上是單塊讀?我目前能想到的有:
1. db_file_multiblock_read_count 參數設置為1
2. 表或索引的大部分塊在 buffer cache 中,少量不連續的塊在磁盤上。
3. 一些特殊的塊,比如段頭
4. 行鏈接的塊
5. LOB 列的索引塊和 cache 的 LOB 塊(雖然10046事件看不到 lob 索引和 cache 的 lob 的讀等待,但客觀上是存在的。)
那麼在這條 SQL 語句產生的大量單塊讀,又是屬於什麼情況呢?我們來看看單塊讀更細節的情況:
多次執行同樣的 SQL ,發現絕大部分的單塊讀發生在3、353-355這四個文件上,我們來看看這4個文件是什麼:
原來是 UNDO 表空間。那麼另一個疑問就會來了,為什麼在 UNDO 上產生了如此之多的單塊讀?首先要肯定的是,這條簡單的查詢語句,是進行的一致性讀。那麼在進行一致性讀的過程中,會有兩個動作會涉及到讀 UNDO 塊,延遲塊清除和構建 CR 塊。下面我們用另一個腳本來查看會話當時的狀況:
上面的結果是5秒左右的會話采樣數據。再一次提醒,涉及到時間,特別要精確到毫秒的,不一定很精確,我們主要是看數據之間的對比。從上面的數據來看,會話請求了382次 IO 請求,單塊讀和多塊讀一共耗時4219.17ms(4.17s+49.17ms),平均每次 IO 耗時 11ms。這個單次 IO 速度對這套系統的要求來說相對較慢,但也不是慢得很離譜。data blocks consistent reads - undo records applied 這個統計值表示進行一致性讀時,回滾的 UNDO 記錄條數。
比這個統計值可以很明顯地看出,這條 SQL 在執行時,為了得到一致性讀,產生了大量的 UNDO 記錄回滾。那麼很顯然,在這條 SQL 語句開始執行的時候,表上有很大的事務還沒有提交。當然還有另一種可能是 SQL 在執行之後有新的很大的事務(不過這種可能性較小一些,因為那樣的話這條 SQL 可能比較快就執行完了)。
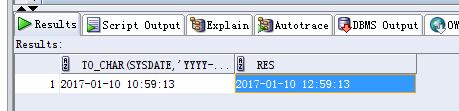
詢問發測試的人員,稱沒有什麼大事務運行過,耳聽為虛,眼見為實:
這張表目前沒有事務,但是曾經 update 了超過1.6億條記錄。最後一次 DML 的時間正是這條執行很慢的 SQL 開始運行之後的時間(這裡不能說明最後一次事務量很大,也不能說明最後一次修改對 SQL 造成了很大影響,但是這裡證明了這張表最近的確是修改過,並不是像測試人員說的那樣沒有修改過)。
實際上對於這張表要做的操作,我之前是類似的表上是有看過的。這張表的總行數有上億條,而這張表由於進行數據的人工處理,需要 update 掉絕大部分的行, update 時使用並行處理。那麼這個問題到,從時間順序上來講,應該如下:
在表上有很大的事務,但是還沒有提交。
問題 SQL 開始執行查詢。
事務提交。
在檢查 SQL 性能問題時,表上已經沒有事務。
由於 update 量很大,那麼 UNDO 占用的空間也很大,但是可能由於其他活動的影響,很多 UNDO 塊已經刷出內存,這樣在問題 SQL 執行時,大量的塊需要將塊回滾到之前的狀態(雖然事務開始於查詢 SQL ,但是是在查詢 SQL 開始之後才提交的,一致性讀的 SCN 比較是根據 SQL 開始的 SCN 與事務提交 SCN 比較的,而不是跟事務的開始 SCN 比較),這樣需要訪問到大量的 UNDO 塊,但是 UNDO 塊很多已經不在內存中,就不得不從磁盤讀入。
對於大事務,特別是更新或 DELETE 數千萬記錄的大事務,在生產系統上盡量避免單條 SQL 一次性做。這造成的影響特別大,比如:
v 事務可能意外中斷,回滾時間很長,事務恢復時過高的並行度可能引起負載增加。
v 表中大量的行長時間被鎖住。
v 如果事務意外中斷,長時間的回滾(恢復)過程中,可能嚴重影響 SQL 性能(因為查詢時需要回滾塊)。
v 事務還未提交時,影響 SQL 性能,比如本文中提到的情況。
v 消耗過多 UNDO 空間。
v 對於 DELETE 大事務,有些版本的 oracle 在空閒空間查找上會有問題,導致在 INSERT 數據時,查找空間導致過長的時間。
v 對於 RAC 數據庫,由於一致性讀的代價更大,所以大事務的危害更大。
那麼,現在我們可以知道,全表掃描過程還會產生單塊讀的情況有,讀 UNDO 塊。
對於這條 SQL ,要解決其速度慢的問題,有兩種方案:
① 在表上建個索引,如果類似的 SQL 還要多次執行,這是最佳方案。
② 取消 SQL ,重新執行。因為已經沒有事務在運行,重新執行只是會產生事務清除,但不會回滾 UNDO 記錄來構建一致性讀塊。
繼續回到問題,從統計數據來看:
l 每秒只構建了少量的一致性讀塊(CR block created,table scan blocks gotten這兩個值均為2);
l 每秒的 table scan rows gotten 值為98.4,通過 dump 數據塊可以發現塊上的行數基本上在49行左右,所以一致性讀塊數和行數是匹配的;
l session logical reads 每秒為97.6,由於每回滾一條 undo 記錄都要記錄一次邏輯讀,這個值跟每秒獲取的行數也是匹配的(誤差值很小),與 data blocks consistent reads - undo records applied 的值也是很接近的。
問題到這兒,產生了一個疑問,就是單塊讀較多(超過70),因此可以推測,平均每個 undo 塊只回滾了不到2條的 undo 記錄,同時同一數據塊上各行對應的 undo 記錄很分散,分散到了多個 undo 塊中,通常應該是聚集在同一個塊或相鄰塊中,這一點非常奇怪,不過現在已經沒有這個環境(undo 塊已經被其他事務重用),不能繼續深入地分析這個問題,就留著一個疑問,歡迎探討(一個可能的解釋是塊是由多個並發事務修改的,對於這個案例,不會是這種情況,因為在數據塊的 dump 中沒有過多 ITL,另外更不太可能是一個塊更新了多次,因為表實在很大,在短時間內不可能在表上發生很多次這樣的大事務)。
在最後,我特別要提到,在生產系統上,特別是 OLTP 類型的系統上,盡量避免大事務。
About Me
.........................................................................................................................................................................................................
● 本文來自於微信公眾號轉載文章,若有侵權,請聯系小麥苗及時刪除,非常感謝原創作者的無私奉獻
● 本文在ITpub(http://blog.itpub.net/26736162)、博客園(http://www.cnblogs.com/lhrbest)和個人微信公眾號(xiaomaimiaolhr)上有同步更新
● 小麥苗分享的其它資料:http://blog.itpub.net/26736162/viewspace-1624453/
● 原文地址:http://mp.weixin.qq.com/s?__biz=MjM5MDAxOTk2MQ==&mid=2650270898&idx=1&sn=31bd432b8f37a05efe568ab697f814b9&scene=23&srcid=0706s14rOG9uMJqKCDq9aSkt#rd
● QQ群: 230161599 微信群:私聊
● 聯系我請加QQ好友(642808185),注明添加緣由
● 【版權所有,文章允許轉載,但須以鏈接方式注明源地址,否則追究法律責任】
.........................................................................................................................................................................................................
長按下圖識別二維碼或微信客戶端掃描下邊的二維碼來關注小麥苗的微信公眾號:xiaomaimiaolhr,學習最實用的數據庫技術。