無論是數據庫管理員,還是普通用戶,都需要經常對數據庫對象進行管理,如數據庫對象的創建、刪除、修改等。
Oracle 中的數據庫對象包括表、索引、視圖、存儲程序、序列等,這些數據庫對象以一種邏輯關系組織在一起,這就是模式( schema )。
模式是一個用戶所擁有的所有數據庫對象的集合。
每個數據庫對象都屬於某個用戶,一個用戶所擁有的數據庫對象就組成了一個模式,模式的名稱與用戶名相同。
當創建用戶時,就同時產生了一個模式,在默認的情況下,用戶在自己的模式中有所有的權限。
將站在數據庫管理員的角度,重新考慮這些數據庫對象在Oracle 中所涉及的特性,如存儲結構、數據的組織方式等。
表的管理
表的管理涉及表的結構、表的創建、修改與刪除等操作,以及臨時表、分區表和索引組織表三種特殊類型的表。
表的結構
在數據庫中,表是最基本的數據庫對象,用來存儲系統或用戶的數據。
表中的數據是按照行和列的格式存放的。
表中的各行數據一般以寫入的先後順序存放,而一行中的各列一般按照定義表時指定的順序存放的。
在邏輯結構上,一個表位於某個表空間。
當創建一個表時,將同時創建一個表段,用於存放表中的數據。
在物理結構上,表中的數據都存放在數據塊中,因而在數據塊中存放的是一行行的數據。
圖為數據塊中一行數據的結構。
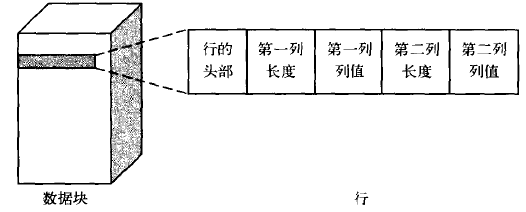
其中行的頭部記錄了該行中列的個數、行間的全連接、加鎖信息等。
列長度記錄-個列實際占用的字節數,而列值則記錄了該列實際存放的數據。
表中的每一行數據都有一個行號,用於標識該行數據的物理位置。
根據這個行號,可以直接定位該行數據。
行號可以通過偽列ROWID獲得。
例如,以下查詢得到表DEPT中的數據及每行的行號。
SELECT rowid, emp.* FROM scott.emp;
行號是由數據庫服務器自動生成的字符串,包含18個字符。
行號的組成如圖所示。

其中前六個字符表示數據庫對象的編號,用來指定該行數據屬於哪個數據庫對象。
在數據庫中每個數據庫對象都有一個唯一的編號。
從第七個到第九個共三個字符表示數據文件的相對編號,用來指定該行數據存儲在哪個數據文件中。
在數據庫中每個數據文件中有兩個編號,一個是絕對編號,它是數據文件在整個數據庫范圍內的編號,另一個是相對編號,它是數據文件在一個表空間范圍內的編號。
從第十到第十五共六個字符表示數據塊的編號,用來指定該行數據位於哪個數據塊中。
最後三個字符表示行號,用來指定該行數據在數據塊中位於第幾行。
為了使用戶對行號的進行解析, Oracle提供了一個DBMS_ROWID程序包,利用這個程序包中的函數可以對行號進行分析。
DBMS_ROWID 中各個函數的用法如表所示。

例如,以下查詢將得到dept表中每行數據所在的文件編號、數據庫對象的編號、數據塊編號和在數據塊中的行號:
SELECT DBMS_ROWID.ROWID_RELATIVE_FNO(rowid) AS 相對文件號,
DBMS_ROWID.ROWID_OBJECT(rowid) AS 對象編號,
DBMS_ROWID.ROWID_BLOCK_NUMBER(rowid) AS 數據塊編號,
DBMS_ROWID.ROWID_ROW_NUMBER(rowid) AS 行號
FROM scott.dept;
表的創建
在創建表時,可以同時為表指定一些重要的屬性,如存儲參數、所屬表空間等。
這些屬性都通過CREATE TABLE命令的子句指定。
1.PCTFREE和PCTUSED子句
這兩個參數的作用是用來控制數據塊的空間使用情況。
為了減少數據塊間的遷移,在創建表時可以通過PCTFREE和PCTUSED子句指定數據塊空間的使用情況。
考慮以下創建表的語句:
CREATE TABLE Tl(
name varchar2 ( 10) )
PCTFREE 20
PCTUSED 40;
在表Tl 中,每個數據塊都有20o/o的保留空間。
當可用空間使用完後,新的數據將被寫入另外一個數據塊。
當從表中刪除數據時,數據塊中已用空間不斷減少,當減少到40%時,可再次向該數據塊中插入數據。
在使用PCTFREE和PCTUSED子句時,可以參考以下原則:
• PCTFREE和PCTFUSED的值必須小於或等於100% 。
·如果在一個表上很少執行UPDATE操作,可以將PCTFREE設置得盡量小。
• PCTFREE與PCTUSED之和越接近100o/o ,數據塊的空間利用率越高。
2.TABLESPACE子句
TABLESPACE子句用來指定將表創建在哪個表空間上。
如果不指定TABLESPACE子句,用戶將在自己的默認表空間上創建表。
為了能夠在指定的表空間上創建表,當前用戶必須在該表空間上有足夠的空間配額或在數據庫中具有UNLIMITED TABLESPACE權限。
3.INITRANS和MAXTRANS子句
數據庫中的數據存儲在數據塊中,用戶的事務最終要修改數據塊中的數據。
Oracle允許多個並發的事務同時修改一個數據塊中的數據。
每當用戶的事務開始作用於一個數據塊時,數據庫服務器將在該數據塊的頭部為該事務分配一個事務項,以記錄事務的相關信息。
事務結束時,對應的事務項將被刪除。
INITRANS和MAXTRANS參數用於控制一個數據塊上的並發事務數量,其中INITRANS 用於指定初始的事務數量。
MAXTRANS 用於指定最大的並發事務數量。
當創建一個表時,數據庫服務器按照INITRANS的值為每個數據塊分配一定的事務項,這些事務項將一直保留到該表被刪除。
當一個事務訪問數據塊時,將占用其中的一個事務項,事務結束時,將釋放事務項。
當這些預先創建的事務項全部被占用後,如果又有新的並發事務發生,數據庫服務器將在數據塊的可用空間中為事務創建一個新的事務項。
在任一時刻,數據塊中的事務項不會超過MAXTRANS 參數值。
例如,在利用以下語句創建表時,指定初始的事務項為10 ,最大的並發事務數量為2000
CREATE TABLE T2(
name varchar2 ( 10) )
INITRANS 10
MAXTRANS 200;
INITRANS和MAXTRANS參數的值可以根據用戶對表的訪問情況進行設置。
如果參數值過大,事務項將占用更多的數據塊空間,那麼數據可以利用的空間將喊少。
如果參數設置過小,有些事務將因為無法分配到事務項而等待,從而降低了數據庫的性能。
一般情況下,如果多個用戶同時訪問表的情況很少發生,可以為這兩個參數設置較小的參數值,反之要為這兩個參數指定較大的參數值。
4.CACHE子句
CACHE子句用於指定將表中的數據放在數據庫高速緩存中,並保留一段時間。
如果在創建表時指定了CACHE字句,那麼在用戶第一次訪問表中的數據時,這個表將整個被讀到數據庫高速緩存中,並保留較長的一段時間,這樣用戶以後再訪問該表時,可直接訪問數據庫高速緩存中的數據,從而提高訪問的效率。
在默認情況下創建表時使用NOCACHE子句。
對於一些較小的、用戶訪問頻繁的表,在創建時可以考慮使用CACHE子句,以提高訪問效率。
CREATE TABLE T3(
name varchar2 ( 10) )
CACHE;
5.RAPALLEL子句
在一般情況下,通過INSERT命令向表中寫人數據時,一次寫入一行數據,這樣的寫操作是串行進行的。
如果在創建表時指定了PARALLEL子句,那麼在向表中以批量方式寫入大量數據時就是以並發方式進行的,這樣可以大大提高處理的速度。
例如,利用以下語句創建表時,將實現並發操作。
CREATE TABLE T4(
name varchar2 ( 10) )
PARALLEL;
如果不希望在表上以並發方式寫入數據,在創建表時需要指定NOPARALLEL 。
6.LOGGING子句
在默認情況下,用戶在表上執行DDL和DML命令時,服務器進程都會產生重做日志。
如果不希望產生重做日志,在創建表時需要指定NOLOGGING子句。
使用NO LOGGING子句有以下好處:
·由於不寫重做日志,因而節約了重做日志文件的存儲空間。
.減少了處理時間。
·在以並行方式向表中寫入大量數據時提高了效率。
當然在使用NOLOGGING子句時也有不好的一面。
因為沒有重做日志,當表被破壞時,將無法進行恢復,所以在表創建後應該及時對其進行備份。
CREATE TABLE T5(
name varchar2 ( 10) )
NOLOGGING;
7.COMPRESS子句
如果在創建表時使用了COMPRESS子句,那麼一個數據塊中兩行完全相同的數據將被壓縮為一行,並存儲在數據塊的開始,在數據塊中本應存儲這兩行數據的地方只存儲該行數據的引用。
使用表的壓縮功能可以減少表所占用的存儲空間和數據庫高速續存空間,並且可以提高查詢速度。
表的壓縮功能一般用在向表中批量插入數據的情況(例如基於查詢創建表)。
一個表中可以包含壓縮的和未壓縮的數據,所有DML操作均可應用於這些壓縮的數據。
例如,下面的語句用於創建表T6,這個表具有壓縮功能,支持並發的數據寫入,對DDL和DML命令不產生重做日志。
CREATE TABLE T6(
name varchar2 ( 10) )
COMPRESS PARALLEL NOLOGGING;
臨時表是一種特殊類型的表,表中的數據並不永久保存,而是一些臨時數據。
這些臨時數據只在當前事務或當前會話中有效,當事務或會話結束時,這些臨時數據將被全部刪除。
創建臨時表的命令是CREATE GLOBAL TEMPORARY TABLE 。
在創建臨時表時還需要通過ON COMMIT子句指定臨時數據的有效范圍。
如果指定了ON COMMIT DELETE ROWS 子句,那麼臨時表是事務級的,當事務提交或回滾時,臨時表中的數據即被刪除。
如果指定了ONCOMMIT PRESERVE ROWS子句,那麼臨時表是會話級的,表中的數據將一直保留,直到當前會話結束時才被刪除。
以下語句用於創建一個事務級的臨時表:
CREATE GLOBAL TEMPORARY TABLE T7(
name varchar2(10)
ON COMMIT DELETE ROWS;
表的修改
在數據庫服務器的運行過程中,如果發現表的設計不合理,可以對其進行修改。
一般來說,對表的修改涉及以下內容:
·表的結構的修改,如增加列、刪除列、修改某個列的定義。
·約束的修改,如添加約束、刪除約束、激活約束與禁止約束。
·修改表的物理屬性,如PCTFREE參數、PCTUSED參數。
·表的移動,如移動到一個新的數據段或表空間。
·表的存儲空間的手工分配和回收。
修改表的命令是ALTER TABLE ,普通用戶只能修改自己的表。
如果要修改其他用戶的表,必須具有ALTER ANY TABLE系統權限。
1.修改表的物理屬性
在創建表時可以指定PCTFREE 、PCTUSED 、INITRANS 、CACHE等參數,這些參數對於表中存儲空間的利用有直接的影響。
表在創建以後,用戶也可以對這些參數進行修改。
例如,下面的語句對表的參數進行了修改:
ALTER TABLE T6 NOLOGGING;
2.表的移動
表的移動意味著把表中的數據移動到一新的表段中,同時可以把表段移動到另外一個表空間中。
表的移動在以下場合非常有用:
·消除表中的存儲碎片。
·消除表中數據塊間的鏈接。
·把表移動到另外-個表空間中。
.修改表所使用的數據塊大小。
在對表進行移動時,表中的數據將被重新排列,這樣就可以消除表中的存儲碎片和數據塊的鏈接。
如果兩個表空間所使用的數據塊大小不同,那麼表在兩個表空間中移動時,也將使用不同大小的數據塊。
移動表所使用的命令是ALTER TABLE 。
在移動表時,先為表創建一個新的表段,然後把表中的數據移動到這個新段中,最後刪除原來的表段。
例如:
ALTER TABLE T2 MOVE;
又如, 下面的ALTER語句用於把表T2移動到表空間USERS中:
ALTER TABLE T2 MOVE TABLESPACE USERS;
需要注意的是,表被移動後,表的行號將發生變化,所以表上原來的索引將不可用。
在表移動後應該刪除原來的索引並重新創建。
存儲空間的手工分配和回收
表在創建後,隨著數據的增加, Oracle將按照存儲參數的設置不斷為表分配新的區。
這一過程是自動進行的,不需要用戶的干預。
在布些情況下,用戶希望為表分配一個指定大小的區,這時需要利用ALTER TABLE命令及其ALLOCATE EXTENTS子句為表手工分配一個區。
在手工為表分配區時,可以為其指定大小。
如果沒有指定大小,數據庫服務器將按照該表所在表空間的區大小,為表分配一個區。
例如,以下語句為表T2手工分配了一個512KB 的區:
ALTER TABLE T2 ALLOCATE EXTENT(SIZE 521K);
實際上,手工指定的區大小與該表所在表空間的區大小可能不一致。
假設表空間的區大小是64KB ,那麼上述命令的執行結果是為表T2分配了8個64KB 的區。
在表段的HWM以下,可能有一些尚未使用的數據塊。
為了節省磁盤空間,可以通過命令把這些存儲空間回收。
例如:
ALTER TABLE T2 DEALLOCATE UNUSED;
表的刪除
當一個表不需要時,可以將其刪除。
刪除表時,將產生以下結果:
·表的結構信息從數據字典中被刪除,表中的數據不可訪問。
·表上的所有索引和觸發器被一起刪除。
·所有建立在該表上的同義詞、視圖和存儲程序變為無效。
·所有分配給表的區被標記為空閒,可被分配給其的對數據庫對象。
一般情況下,普通用戶只能刪除自己的表。
若希望刪除其他用戶的表,則必須具有DROP ANY TABLE系統權限。
為了防止用戶對表進行誤刪除,在數據庫中提供了一個回收站。
當表被刪除時,表所占用的存儲空間並不是立即被釋放,而是被放進了回收站。
回收站實際上是一個數據字典表,用於記錄被刪除的表、索引等數據庫對象的信息。
當一個數據庫對象被刪除時,它所占用的存儲空間並不立即釋放,而是被重命名後放進了回收站。
如果後來用戶發現某個對象是被誤刪除的,可以從回收站中將其恢復。
當用戶刪除一個表空間時,表空間中的數據庫對象並不被放入回收站,而且回收站中原來屬於該表空間的數據庫對象也將被清除。
當一個用戶被刪除時,屬於這個用戶的數據庫對象也不被放入回收站,而且回收站中原來屬於該用戶的數據庫對象也將被清除。
用戶可以在回收站中查看屬於自己的、被刪除的數據庫對象,數據庫管理員可以查看所有被刪除的數據庫對象。
用戶可以通過以下的語句查看回收站中的內容:
SELECT * FROM RECYCLEBIN;
數據庫對象被刪除後,它將被重命名並放入回收站。
重命名的目的是為了防止被刪除對象的名稱相互沖突。
重命名的規則為:
BIN$id$ 版本
其中id是由oracle產生的包含26個字符的字符串,是被刪除數據庫對象的唯一標識。
版本是由數據庫服務器自動指定的版本號。
為了查看回收站的方便, Oracle數據庫提供了兩個數據字典視圖:
USER_RECYCLEBIN :包含當前用戶的被刪除的數據庫對象, RECYCLEBIN是它的同義詞。
DBA_RECYCLEBIN :包含所有被刪除的數據庫對象,僅數據庫管理員可以訪問。
例如,以下語句用於查詢SCOTT用戶被刪除的數據庫對象:
SELECT OBJECT_NAME, ORIGINAL_NAME FROM DBA_RECYCLEBIN WHERE OWNER='SCOTT';
用戶也可以通過執行SQL*Plus命令show recyclebin來查看回收站。
盡管表已經被放入回收站,用戶還是可以訪問表中的數據,只是表名必須使用它在回收站中的名稱。
例如:
SELECT * FROM "BIN$dyeDMxzWSkqrFCX6+dTO2A==$0";
當用戶確信一個數據庫對象不再需要時,可以執行PURGE命令將其從回收站中清除,該對象及其相關對象所占用的存儲空間將一起被釋放。
清除數據庫對象時,可以使用回收站中的名稱,也可以使用被刪除前的名稱。
例如,以下兩條語句的作用都是從回收站中清除表T2:
PURGE TABLE "BIN$dyeDMxzWSkqrFCX6+dTO2A==$0";
PURGE TABLE TEST;
如果希望在刪除表的同時釋放存儲空間,可以在DROP TABLE命令中使用PURGE子句,這個表就直接被刪除了,而不是被放到回收站中。
例如:
DROP TABLE TEST PURGE;
用戶還可以選擇清除回收站中原來屬於某個表空間的所有數據庫對象,或者清除某個用戶的原來屬於某個表空間的所有數據庫對象,還可以清除屬於自己的數據庫對象。
這三種操作對應的命令格式分別為:
PURGE TABLESPACE USERS;
PURGE TABLESPACE USERS USER SCOTT;
PURGE RECYCLEBIN;
對於第三種用法,數據庫管理員可用來清除回收站中的所有內容,只是要將RECYCLEBIN替換為DBA_RECYCLEBIN。
如果一個數據庫對象被刪除了,那麼在被從回收站中清除之前,可以通過執行FLASHBACK命令將其恢復,並可通過RENAME子句為其指定一個新的名稱。
例如:
FLASHBACK TABLE TEST TO BEFORE DROP RENAME TO TEST_BAK;
如果沒有通過RENAME子句為它指定名稱,·它將使用原來的名稱。
分區表的管理
隨著數據庫系統的運行,數據庫中存儲的數據越來越多。
在現代企業的數據庫中,許多表的存儲空間可達幾百個GB ,甚至幾個TB 。
對於這樣的大型表如果執行全表查詢或者DML操作時,效率是非常低的。
為了提高大型表的訪問效率, Oracle提供了一種分區技術,利用這種技術可以把表、索引等數據庫對象中的數據分割成小的單位,分別存放在一個個單獨的段中,用戶對表的訪問便轉化為對相對較小段的訪問。
分區的概念
分區是指將表、索引等數據庫對象劃分為較小的可管理片段的技術,每個片斷稱為一個分區或子分區。
每個分區存儲在一個單獨的段中,可分別進行管理。
這些分區具有相同的邏輯結構,比如,一個分區表中的所有分區與表有相同的列定義和約束定義。
一個表被分區後,對表的查詢操作可以局限於某個分區進行,而不是整個表,這樣可以大大提高查詢速度。
例如,通信公司將用戶通話信息記錄在一個表中,在這個表中一年產生40GB 的數據。
假設要對用戶的通話信息按照季度進行統計,那麼這樣的統計需要在全表范圍內進行。
如果對該表按季度進行分區,那麼每個分區的大小平均為10GB 左右,這樣在進行統計時,只需要在10GB范圍內進行。
當在表上進行並行DML操作時,可以在所有分區上同時進行,同樣可以大大減少處理時間。
盡管一個表的所有分區具有相同的結構,但是它們被單獨存儲在一個段中,這些段可以位於同一個表空間中,也可以位於不同的表空間中。
將這些分區放在不同的表空間上具有以下的好處:
·減少了所有數據都損壞的可能性。
·可以針對每個分區單獨進行備份和恢復。
·可以將同一個表中的數據分布在不同的磁盤上,從而均衡磁盤上的I/O操作。
·提高了表的可管理性、可利用性和訪問效率。
在創建分區表時,以表中某個列或多個列的組合為依據,創建多個分區。
表中的數據將按照分區列上數據的不同,分布在不同的分區中。
目前Oracle支持的分區方能有以下幾種:
·范圍分區
·列表分區
.散列分區
·范圍一散列分區
.范圍一列表分區
范圍分區
范圍分區的方法是按照某個列或幾個列的值的范圍來創建分區,當用戶向表中寫入數據時,數據庫服務器將按照這些列上的數據的大小,將數據寫入相應的分區。
在創建范圍分區時,首先要指定按照哪些列進行分區,然後要為每個分區指定數據范圍。
范圍分區的原則是: 數據應盡可能均勻地分布在各個分區中,如果做不到這一點,應該考慮使用其他類型的分區。
例如,以下語句創建一個分區表call ,用來記錄用戶的電話通話信息,包括主叫、被叫、通話的年、月、日及時長,並且根據月進行分區。
CREATE TABLE call(
caller char(15),
callee char(15),
year number(4),
month number(2),
day number(2),
duration number(4))
PARTITION BY RANGE(month)
(PARTITION P1 VALUES LESS THAN (4) TABLESPACE USERS,
PARTITION P2 VALUES LESS THAN (7) TABLESPACE USERS,
PARTITION P3 VALUES LESS THAN (10) TABLESPACE USERS,
PARTITION P4 VALUES LESS THAN (13) TABLESPACE USERS
);
需要說明的是,在上述例子中創建的表可能不符合常規,這僅僅是為了說明分區表的創建方法,因為在一般的表中,年、月、日這樣的列是合在一起,通過一個列實現的。
在創建分區表時,首先通過“PARTITION BY RANGE”子句指定分區的類型為范圍分區,
然後在這個子句之後的小括號中指定一個或多個列,作為分區的依據。
表中的每個分區都可以通過“PARTITION”子句指定一個名稱,如果沒有指定,數據庫服務器將自動為其指定一個名稱。
每個分區都有一個范圍,通過“VALUE LESS THAN”子句可以為分區指定上界,而它的下界是前一個分區的上界。
對於最後一個分區,它的上界可以用“ MAXVALUE ”來代替。
當在分區表中執行DML操作時,實際上是在各個分區上透明地修改數據。
當執行SELECT命令時,可以指定查詢哪個分區上的數據,如果不指定,則查詢整個表中的數據。
例如:
SELECT * FROM call PARTITION(P1);
列表分區
范圍分區是按照某個列上的數據范圍進行分區的。
如果某個列上的數據無法通過劃分范圍的方法進行分區,並且該列上的數據是相對固定的值,可以考慮使用列表分區。
一般說來,對於數字型或者日期型的數據,適合采用范圍分區的方法。
而對於字符串型數據,則適合采用列表分區方法。
例如創建一個產品銷售記錄表sales ,記錄產品的銷售情況。
由於產品只在幾個固定的城市銷售,所以可以按照銷售城市對該表進行分區。
CREATE TABLE sales(
sales_id number(6),
year number ( 4) ,
month number ( 2),
day number ( 2) ,
salesman char(8),
city char(10))
PARTITION BY LIST(CITY)
(PARTITION P1 VALUES ( '北京','上海'),
PARTITION P2 VALUES ( '天津','廣州'),
PARTITION P3 VALUES ( '沈陽','武漢'),
PARTITION P4 VALUES ('西安','成郁')
);
在創建列表分區時,通過PARTITION BY LIST子句指定對表進行列表分區,然後通過PARTITION子句定義多個分區,在每個分區中分區列的取值通過VALUES子句指定
當用戶向表中插入數據時,只要分區列的數據與VALUES子句指定的數據之一相等,該行數據便被寫入對應的分區中。
散列分區
在很多情況下,用戶無法預測某個列上數據的變化范圍,因而無法事先創建固定數量的范圍分區或列表分區,使用戶的數據按照分區列上的數據分布在相應的分區中。
在這種情況下,可以創建散列分區。
當用戶向表中寫入數據時,數據庫服務器將根據一個散列函數對數據進行計算,把數據均勻地分布在各個分區中。
在散列分區中,用戶無法預測數據將被寫入哪個分區。
現在我們重新考慮產品銷售表的例子。
如果銷售城市不是相對固定的,而是遍布全國各地,這時很難對該表進行列表分區。
如果為該表進行散列分區,可以很好地解決這個問題。
CREATE TABLE sales_1(
sales_id number(6),
year number (4),
month number(2),
day number(2),
salesman char ( 8) ,
city char( 10) )
PARTITION BY HASH(city)
(PARTITION Pl,
PARTITION P2,
PARTITION P3,
PARTITION P4
);
復合分區
復合分區是指先對表進行范圍分區,然後對每個分區再進行散列分區或列表分區,產生若干子分區。
根據子分區的劃分方法不同,復合分區可分為范圍分區一散列分區和范圍分區一列表分區。
對表進行復合分區後,分區僅僅是邏輯上的概念,只有子分區才是物理上的對象。
每個子分區對應一個段,它們可分別位於不同的表空間中,但是同一個分區的所有子分區具有相同的存儲參數。
現在仍以產品銷售表為例來說明復合分區的用法。
如果銷售數據很多,並且銷售城市遍布全國各地,那麼我們可以考慮先按照銷售的月份對表進行范圍分區,使銷售數據按季度分布在四個范圍分區中,然後對每個分區再進行散列分區,劃分若干子分區,使一個季度的銷售數據再按照銷售城市的不同而均勻分布在各個子分區中。
以下是創建這個分區表的語句:
CREATE TABLE sales_2(
sales_id number(6),
year number (4),
month number(2),
day number(2),
salesman char ( 8) ,
city char( 10) )
PARTITION BY RANGE(month)
SUBPARTITION BY HASH(city)
(
PARTITION Pl VALUES LESS THAN (4)
(
SUBPARTITION P11,
SUBPARTITION P12,
SUBPARTITION P13
),
PARTITION P2 VALUES LESS THAN (7)
(
SUBPARTITION P21,
SUBPARTITION P22,
SUBPARTITION P23
),
PARTITION P3 VALUES LESS THAN (10)
(
SUBPARTITION P31,
SUBPARTITION P32,
SUBPARTITION P33
),
PARTITION P4 VALUES LESS THAN (13)
(
SUBPARTITION P41,
SUBPARTITION P42,
SUBPARTITION P43
)
);
在上述例子中,先按照月份對表進行范圍分區,定義了四個分區,然後對每個分區再按照城市進行散列分區,產生3 個子分區,這樣一共產生了12 個子分區。
定義子分區的子句是SUBPARTITION對於每個分區,可以為其指定存儲參數,該分區中的所有子分區都使用同樣的存儲參數。
對於每個子分區,我們可以用TABLESPACE子句為其指定所屬的表空間,使這些子分區分別位於不同的表空間中。
總之,創建分區表的目的是把數據的查詢或統計限制在一定范圍之內,以減少磁盤I/O。
在這些表上執行DML命令時,和普通表沒有什麼區別,只不過數據將按照分區的條件被寫入到不同的段中。
索引管理
索引的管理主要包括索引的創建、刪除、修改以及索引的重新組織等操作。
下面主要介紹幾種特殊的索引,如反向索引、位圖索引等,這些索引雖然並不常用,但是在特殊的場合能起到非常重要的作用。
索引概念
索引是一種數據庫對象,它建立在表的一個或多個列上,目的是為了提高該表上的查詢速度。
索引有兩種創建方式,一種方式是在表上指定主鍵約束或唯一性約束時自動創建,另一種方式是通過命令手工創建。
索引雖然可以提高表的查詢速度,但是如果在表上執行DML操作,索引中的數據可能需要重新排序,從而降低數據庫的性能。
因此,如果在表上主要執行DML操作,而不是查詢操作,那麼應該考慮減少甚至不創建索引。
如果要通過SQL*Loader或者import工具向表中插入大量的數據,那麼可以考慮在這個操作完成之後再創建索引。
索引的形式很多,按照數據的組織形式不同,可以把索引分為B *樹索引、反向索引、位圖索引、基於函數的索引和分區索引等多種形式。
其中B *樹索引是最常用的索引形式。
索引是一種數據庫對象,它雖然建立在某個表之上,但一般情況下它被單獨存放在一個索引段中,因此我們在創建索引時可以為索引段指定物理屬性和存儲參數等信息。
例如,下面的語句用於在表dept的dname 列上創建一個索引。
CREATE INDEX dept_idxl ON scott.dept(dname)
TABLESPACE users
PCTFREE 20
INITRANS 5 MAXTRANS 10
NOLOGGING
PARALLEL;
在CREATE INDEX命令中所使用的子句與創建表時使用的子句意義基本相同。
需要注意的是,在創建索引時不能使用PCTUSED和CACHE子句。
反向索引
B *樹索引是最經常用的索引形式。
在一個表中,索引列上的數據越隨機,就越能體現B *樹索引的優越性。
然而如果表中某個列上的數據已經有序,或者基本有序,那麼在這個列上建立B *樹索引就沒有什麼意義了。
在這種情況下,如果按照該列上相反順序的值建立索引,那麼可以降低索引的層次,從而達到創建索引的目的。
實際上該索引是一種特殊形式的B *樹索引,只不過是把索引列上的值按照相反的順序存儲在索引中,從而把該列上數據的有規律分布轉換為無規律的分布,然後按照轉換後的數據創建一個B *樹索引。
下圖表示反向索引的構成。
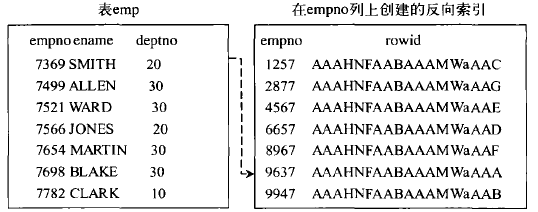
如果表中一個列上的值已經有序,或者基本有序,那麼在該列上建立索引時,應該選擇反向索引。
創建反向索引的方法與創建B *樹索引的方法類似,只是需要使用REVERSE關鍵字進行區別。
例如,假設要在表emp的ename列上創建反向索引,可以執行下面的語句:
CREATE INDEX emp_idxl ON scott.emp(ename) REVERSE;
需要注意的是,反向索引並不像B *樹索引那樣可以直接起作用。
為了使用反向索引,首先要對表進行分析,收集統計它的數據。
例如,為了用反向索引emp_idxl ,應該執行以下語句對表emp進行分析:
ANALYZE TABLE scott.emp COMPUTE STATISTICS;
位圖索引
如果在一個表中某個列上的重復值很多,那麼在該列上創建B *樹索引或者反向索引都是不合適的。
例如,職工的性別只有“男”和“女”兩個值,如果在該列上創建B *樹索引,那麼在根據性別對該表進行查詢時,大約要對表中50%的數據進行掃描,這顯然失去了索引的意義。
如果一個表中某個列上的重復值很多,那麼適合在該列上創建位圖索引。
在位圖索引中,為索引列上每個不同的值分配一個位圖,這個不同的值稱為鍵值。
表中的每行數據在位圖中對應一個二進制位。
如果該行中索引列的值與鍵值相同,那麼對應二進制位1 ,否則對應二進制位0 。
例如,在表emp 中,員工分布在少數的幾個部門中,所有列deptno上的重復值很多。
當在該列上創建位圖索引時,每個不同的部門號將對應一個位圖。
位圖結構如圖所示。
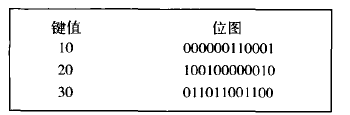
從圖中可以看出,表emp的deptno列上共有三個不同的值,所以對應三個位圖。
如果要在表emp的deptno列創建位圖索引,可以執行下面的語句:
CREATE BITMAP INDEX dept_idx2 ON scott.emp(deptno);
使用位圖索引有兩個好處,一是可以減少索引所占用的磁盤空間,表中的每行數據在位圖索引的每個位圖中只占用一個二進制位,而位圖的數量取決於表中索引列上不重復值的多少。
顯然不重復的值越少,重復值越多,那麼位圖的數量就越少,這樣可以大大節省索引所占用的磁盤空間。
二是可以加快查詢速度,如果要根據索引列對表進行查詢,比如要查詢部門10中的
員工,那麼首先在位圖索引中查找鍵值為10的位圖,然後在這個位圖中查找所有與二進制位1對應的行,從而在表中獲得滿足條件的數據。
如果一個表比較大,那麼創建位圖索引可能需要較長的時間。
為了加快創建索引的速度,可以通過初始化參數CREATE_BITMAP_AREA SIZE在SGA 中為其指定更大的內存空間。
在使用位圖索引時需要注意,位圖索引並不能直接起作用。
在SELECT語句中通過關鍵字INDEX_ COMBINE指定提示,可以使該語句使用指定的位圖索引。
例如:
SELECT /*+ index_combine(emp deptno) */ SUM(sal) FROM scott.emp WHERE DEPTNO=30;
基於函數的索引
基於函數的索引是將索引建立在某個函數或者某個表達式的基礎上。
在一些查詢中,需要對某個列的值進行某種運算,在這種情況下,可以創建基於函數的索引。
例如,考慮下面的查詢:
SELECT * FROM scott.emp WHERE LOWER(ename)='smith';
如果沒有在表emp的ename列上創建索引,那麼在執行這條語句時,需要把ename列的值轉換成小寫,然後與字符串“smith”進行比較。
為了加快查詢速度,可以在ename 列上創建一個索引,先對該列上的值進行相應的轉換,然後把轉換後的值存儲在索引中,這樣在執行查詢時就不需要再進行轉化了。
以下語句用來在表emp的ename列上創建基於函數lower的索引。
CREATE INDEX emp_indx2 ON emp(lower(ename));
索引所基於的函數可以是預定義函數,也可以是用戶自定義的函數。
無論是哪種情況,函數必須已經存在。
例如,為了計算員工的個人所得稅,在數據庫中先創建一個用來計算員工個人所得稅的函數,假設稅率為3% 。
CREATE OR REPLACE FUNCTION tax( sal IN scott.emp.sal%type, comm IN scott.emp.comm%type )
RETURN NUMBER
DETERMINISTIC
IS
BEGIN
RETURN( (sal + NVL(comm, 0))*0.03);
END;
利用上面的函數,可以很方便地計算員工應該繳納的個人所得稅。
假設經常要根據個人所得稅查詢員工的信息,可以在表emp上創建一個基於上述函數的索引:
CREATE INDEX index_tax ON emp(tax(sal, comm));
那樣以後在查詢語句中就可以引用這個索引了,例如:
SELECT ename,sal,comm FROM emp WHERE tax(sal,comm)>50;
基於函數的索引還有另外一種形式,那就是用一個表達式代替函數。
例如,個人所得稅可以通過表達式sal + NVL(comm, 0))*0.03來計算,那麼可以基於這個表達式在表emp上創建一個索引:
CREATE INDEX indx_1 ON emp((sal + NVL(comm, 0))*0.03);
這個索引在以下形式的查詢中將起作用:
SELECT * FROM emp WHERE ((sal + NVL(comm, 0))*0.03 > 50;
需要注意的是,基於函數的索引並不是可以直接起作用的。
在創建基於函數的索引之後,應該對表進行分析。
例如:
ANALYZE TABLE emp COMPUTE STATISTICS;
分區索引
和表的分區一樣,也可以對索引進行分區。
分區後的索引對應若干個索引段。
分區索引是建立在分區表之上的。
在分區表上建立索引時,可以選擇是建立全局索引還是分區索引。
如果是全局索引,那麼索引中的數據將存儲在同一個索引段中。
如果建立分區索引,那麼索引中的數據將存儲在若干個索引段中,表中的每個分區將對應一個單獨的索引段。
例如,下面的語句將在分區表call上創建一個全局索引:
CREATE INDEX indx_sales ON sales(month) GLOBAL;
下面的語句將在分區表call上創建一個分區索引:
CREATE INDEX indx_sale ON sales(month) LOCAL;
索引的維護
索引的維護內容主要包含修改索引的物理屬性、手工分配和回收存儲空間、重建索引、合並索引等。
用戶必須是索引的屬主,或者具有ALTER ANY INDEX 系統權限。
例如,以下語句用於修改索引dept_idxl 的一些屬性:
ALTER INDEX dept_idxl
INITRANS 6 MAXTRANS 12
LOGGING
NOPARALLEL;
對於那些因施加主鍵約束或唯一性約束而產生的索引,則需要通過執行ALTER TABLE命令來修改它的存儲參數。
例如:
ALTER TABLE TEST
ENABLE PRIMARY KEY USING INDEX
PCTFREE 20
INITRANS 5 MAXTRANS 10;
當索引段的空間被使用完以後,它可以自動擴展。
用戶也可以手工為索引段分配一些空間,也可以手工回收那些沒有使用的存儲空間。
例如,下面的語句為索引dept_idxl 分配一個256K的區:
ALTER INDEX dept_idxl ALLOCATE EXTENT(SIZE 256K);
在為索引手工分配區時,如果沒有指定區的大小,則采用索引所在表空間的區大小。
實際上,手工指定的區大小與索引所在表空間的區大小可能不一致。
假設表空間的區大小是64KB,
那麼上述命令的執行結果是為索引分配了4個64KB 的區。
下面的語句用於回收索引dept_idx l 中未使用的存儲空間:
ALTER INDEX dept_idxl DEALLOCATE UNUSED;
重建索引是提高索引訪問效率的一種有放方法。
隨著用戶不斷地在表上執行DML操作,索引段中碎片將越來越多,重建索引可以把索引段中的數據移動到另一塊存儲區,並把它們以緊湊的方式重新排列,從而提高索引的訪問效率。
例如:
ALTER INDEX dept_idxl REBUILD;
對於在線創建的索引,可以對其進行在線重建。
在線重建的意思是在表上有用戶正在執行DML操作的時候,對索引進行重建。
例如:
ALTER INDEX dept_idxl REBUILD ONLINE;
合並索引可以使索引的存儲空間得到充分利用。
如果相鄰的數據塊中有空閒空間,可以將這些數據塊中的索引項合並在一個數據塊中。
例如:
ALTER INDEX dept_idxl COALESCE;
簇的管理
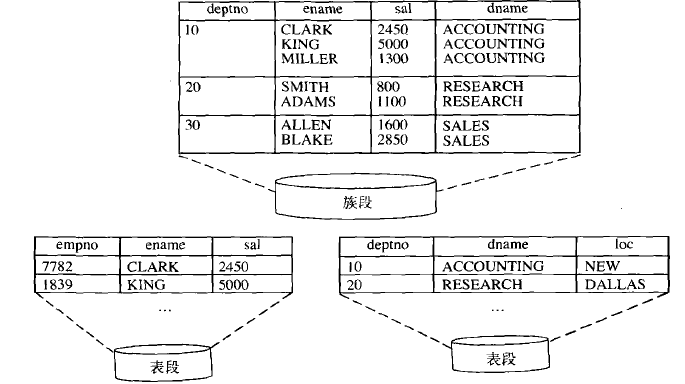
簇是一種數據庫對象,它由一組共享相同數據塊的表組成。
簇中的表根據簇鍵組合在一起,簇鍵相同的行存儲在相同的數據塊或相鄰的數據塊中。
簇鍵是一個列或多個列的組合,簇中的每個表都必須具有與簇鍵相同的列。
在常規的情況下,每個表對應一個單獨的表段,表中的數據存儲在表段中。
當多個表以簇的形式組織在一起後,單獨的表段將不存在,表中的數據都將存儲在一個簇段中。
把表組織為簇的主要目的,是在進行多表聯合查詢時,減少磁盤操作次數,提高查詢速度。
例如,假設要經常執行下面的查詢:
SELECT empno,ename,sal,dname
FROM emp,dept
WHERE emp.deptno=dept.deptno;
由於是在兩個表之間進行連接查詢,所以至少需要兩次磁盤讀操作。
如果把這兩個表以簇的形式組織在一起,磁盤操作的次數可以減少到一次。
由於表emp和dept都有deptno列,所以這個列在簇中就作為簇鍵。
兩個表中簇鍵相同的行將存儲在同一個數據塊或相鄰的多個數據塊中。
下圖表示簇與普通表的區別。