Atitit.數據庫分區的設計 attilax 總結
1. 分區就是分門別類的文件夾 (what)1
2. 分區的好處(y)1
3. 分區原則(要不要分區,何時分區)how2
4. 主要的分表類型有range,list,hash,key等2
5. 水平分區(Horizontal Partitioning) 垂直分區(Vertical Partitioning)3
6. 分區的操作4
7. 分區理論 並行數據庫的體系結構4
8. 參考7
分區的原理
分區的基本原理就是通過訪問一個表或者索引的較小片斷,而不是訪問整個表和索引,以提高數據庫的性能。如果將一個表的不同分區放置在不同的磁盤上,磁盤整體的吞吐量就會成倍上升。
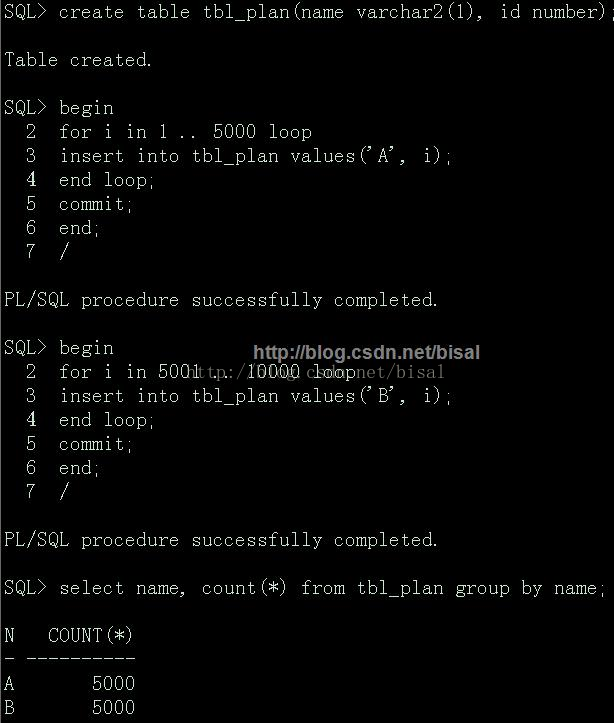
在一個表的數據超過過2000萬條或占用2G空間時,建議建立分區表
分區使得數據管理操作如數據裝載、索引建立和重建、備份和恢復等在分區級別上完成,這比在表級完成操作要明顯的節省時間;
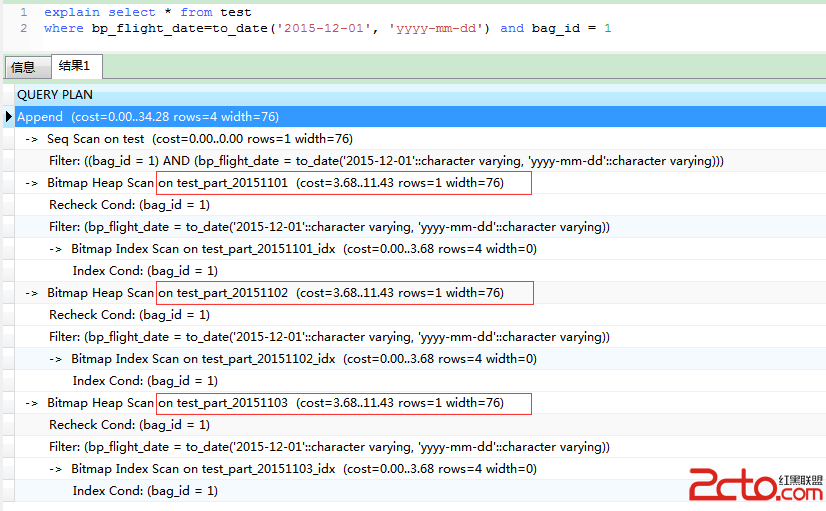
分區可以提高性能,在很多情況下,查詢可以通過掃描某個分區來完成,而不是去掃描整個表;
根據查詢條件自動將掃描范圍縮小到一個或幾個表(索引)分區上。這種方式其實是分區掃描替代了全表掃描。
如果連接查詢的兩張表都在連接列上進行分區,則 會優化連接操作,將一個大的連接分成各個對應分區間的連接,而且這些分區連接操作還可以並行執行。
並行DML:采用並行執行,可以使操作並行在各個分區上同時執行,從而提供執行效率。
考慮對表是否需要分區時,可以從以下幾個方面判斷。不過這也只是經驗之談。僅供參考。
1表的大小。對於大表進行分區,有益於大表操作的性能和大表的數據維護。通常,當表大小超過1.5G,對於OLTP系統表記錄超過1000萬,都應該考慮分區。
2數據的訪問特性。基於表的大部分查詢應用,只訪問表中的少量數據。對於這樣的表進行分區,可以排除無關數據查詢的特性。
3數據維護。某些表的數據維護,經常按時間段刪除成批的數據,例如按月刪除歷史數據,對有這樣需要的表進行分區。以滿足維護需要,因為delete大量數據,對系統開銷很大,有時甚至是不可接受的。
4只讀數據。如果一個表中大部分數據都只是只讀數據,通過對表進行分區,可將只讀數據存儲在只讀表空間中,對於數據庫的備份是十分有益的。
5並行數據操作。對於經常執行並行操作的表,應考慮分區。
6表的可用性。對表的某字段或者某段數據可用性要求很高時,應考慮分區。
具體使用的分區方式我們後面再說,可以先說一點,一定要通過某個屬性列來分割,譬如這裡使用的列就是年份
Range分區是用的最多的方式
這可能是Oracle中最常用的分區機制。適用於數值型或日期型。如果某些記錄暫無法預測范圍,可以創建maxvalue分區,所有不在指定范圍內的記錄都會被存儲到maxvalue所在分區中,並且支持指定多列做為依賴列
LIST分區:類似於按RANGE分區,區別在於LIST分區是基於列值匹配一個離散值集合中的某個值來進行選擇。
列表分區:指定一個離散值集,來確定應當存儲在一起的數據。例如,可以指定STATUS列值在(’A’,’M’,’Z’ )中的行放在分區1中,STATUS值在( ‘D’,P’,’Q’ )中的行放在分區2中,依此類推。列表分區和范圍分區的不同主要是列表分區按照預先給定的一系列離散值進行分區,新數據插入表中時,根據分區鍵值找到對應分區。列表分區的分區列只有一個,當然其單個分區對應值可以使多個。在分區時必須確定分區列可能存在的值,一旦插入的列值不在分區范圍內,則插入/更新就會失敗,因此通常建議使用list分區時,要創建一個default分區,存儲那些不在指定范圍內的記錄,類似range分區中的maxvalue分區。語法是:partition by list()。例如:
KEY分區:類似於按HASH分區,區別在於KEY分區只支持計算一列或多列,且MySQL 服務器提供其自身的哈希函數。
復合分區:是范圍分區和散列分區或列表分區混合使用的一種分區方法。復合分區在分區上用的是范圍分區,在每個分區上又可以使用列表分區或散列分區的方法分成多個子分區。語法是:partition by range() subpartition by hash()
作者:: 老哇的爪子 Attilax 艾龍, EMAIL:[email protected]
轉載請注明來源: http://www.cnblogs.com/attilax/
分區主要有兩種形式://這裡一定要注意行和列的概念(row是行,column是列)
水平分區(Horizontal Partitioning)
這種形式分區是對表的行進行分區,通過這樣的方式不同分組裡面的物理列分割的數據集得以組合,從而進行個體分割(單分區)或集體分割(1個或多個分區)。所有在表中定義的列在每個數據集中都能找到,所以表的特性依然得以保持。
舉個簡單例子:一個包含十年發票記錄的表可以被分區為十個不同的分區,每個分區包含的是其中一年的記錄。(朋奕注:這裡具體使用的分區方式我們後面再說,可以先說一點,一定要通過某個屬性列來分割,譬如這裡使用的列就是年份)
垂直分區(Vertical Partitioning)
這種分區方式一般來說是通過對表的垂直劃分來減少目標表的寬度,使某些特定的列被劃分到特定的分區,每個分區都包含了其中的列所對應的行。
舉個簡單例子:一個包含了大text和BLOB列的表,這些text和BLOB列又不經常被訪問,這時候就要把這些不經常使用的text和BLOB了劃分到另一個分區,在保證它們數據相關性的同時還能提高訪問速度。
在數據庫供應商開始在他們的數據庫引擎中建立分區(主要是水平分區)時,DBA和建模者必須設計好表的物理分區結構,不要保存冗余的數據(不同表中同時都包含父表中的數據)或相互聯結成一個邏輯父對象(通常是視圖)。這種做法會使水平分區的大部分功能失效,有時候也會對垂直分區產生影響。
.1、並行數據庫的體系結構
並行機的出現,催生了並行數據庫的出現,不對,應該是關系運算本來就是高度可並行的。對數據庫系統性能的度量主要有兩 種方式:(1)吞吐量(Throughput),在給定的時間段裡所能完成的任務數量;(2)響應時間(Response time),單個任務從提交到完成所需要的時間。對於處理大量小事務的系統,通過並行地處理許多事務可以提高它的吞吐量。對於處理大事務的系統,通過並行 的執行事務的子任務,可以縮短系統晌應時間。
並行機有三種基本的體系結構,相應的,並行數據庫的體系結構也可以大概分為三類:
l 共享內存(share memeory):所有處理器共享一個公共的存儲器;
l 共享磁盤(share disk):所有處理器共享公共的磁盤;這種結構有時又叫做集群(cluster);
l 無共享(share nothing):所有處理器既不共享內存,也不共享磁盤。
如圖所示:

1.1.1、 共享內存
該 結構包括多個處理器、一個全局共享的內存(主存儲器)和多個磁盤存儲,各個處理器通過高速通訊網絡(Interconnection Network)與共享內存連接,並均可直接訪問系統中的一個、多個或全部的磁盤存儲,在系統中,所有的內存和磁盤存儲均由多個處理器共享。
這種結構的優點在於,處理器之間的通信效率極高,訪問內存的速度要比消息通信機制要快很多。這種結構的缺點在於,處理器的規模不能超過32個或者64個,因為總線或互邊網絡是由所有的處理器共享,它會變成瓶頸。當處理器數量到達某一個點時,再增加處理器已經沒有什麼好處。
共享內存結構通常在每個處理器上有很大的高速緩存,從而減少對內存的訪問。但是,這些高速緩存必須保持一致,也就是緩存一致性(cache-coherency)的問題。
1.1.2、 共享磁盤
該結構由多個具有獨立內存(主存儲器)的處理器和多個磁盤存儲構成,各個處理器相互之間沒有任何直接的信息和數據的交換,多個處理器和磁盤存儲由高速通信網絡連接,每個處理器都可以讀寫全部的磁盤存儲。
共享磁盤與共享內存結構相比,有以下一些優點:(1)每個處理器都有自己的存儲器,存儲總線不再是瓶頸;(2)以一種較經濟的方式提供了容錯性(fault tolerence),如果一個處器發生故障,其它處理器可以代替工作。
該結構的主要問題不是在於可擴展性問題,雖然存儲總線不是瓶頸,但是,與磁盤之間的連接又成了瓶頸。
運行Rdb的DEC集群是共享磁盤的體系結構的早期商用化產品之一(DEC後來被Compaq公司收購,再後來,Oracle又從Compaq手中取得Rdb,發展成現在的Oracle RAC)。
1.1.3、 無共享
該結構由多個完全獨立的處理節點構成,每個處理節點具有自己獨立的處理器、獨立的內存(主存儲器)和獨立的磁盤存儲,多個處理節點在處理器級由高速通信網絡連接,系統中的各個處理器使用自己的內存獨立地處理自己的數據。
這 種結構中,每一個處理節點就是一個小型的數據庫系統,多個節點一起構成整個的分布式的並行數據庫系統。由於每個處理器使用自己的資源處理自己的數據,不存 在內存和磁盤的爭用,提高的整體性能。另外這種結構具有優良的可擴展性——只需增加額外的處理節點,就可以以接近線性的比例增加系統的處理能力。
這種結構中,由於數據是各個處理器私有的,因此系統中數據的分布就需要特殊的處理,以盡量保證系統中各個節點的負載基本平衡,但在目前的數據庫領域,這個數據分布問題已經有比較合理的解決方案。
由於數據是分布在各個處理節點上的,因此,使用這種結構的並行數據庫系統,在擴展時不可避免地會導致數據在整個系統范圍內的重分布(Re-Distribution)問題。
Shared-Nothing結構的典型代表是Teradata(並行數據庫的先驅),值得一提的是,MySQL NDB Cluster也使用了這種結構。
1.2、I/O並行(I/O Parallelism)
I/O並行的最簡單形式是通過對關系劃分,放置到多個磁盤上來縮減從磁盤讀取關系的時間。並行數據庫中數據劃分最通用的形式是水平劃分(horizontal portioning),一個關系中的元組被劃分到多個磁盤。
1.2.1、常用劃分技術
假定將數據劃分到n個磁盤D0,D1,…,Dn中。
(1) 輪轉法(round-bin)。對關系順序掃描,將第i個元組存儲到標號為Di%n的磁盤上;該方式保證了元組在多個磁盤上均勻分布。
(2) 散列劃分(hash partion)。選定一個值域為{0, 1, …,n-1}的散列函數,對關系中的元組基於劃分屬性進行散列。如果散列函數返回i,則將其存儲到第i個磁盤。
(3) 范圍劃分(range partion)。
由於將關系存儲到多個磁盤,讀寫時能同時進行,劃分(partion)能大大提高系統的讀寫性能。數據的存取可以分為以下幾類:
(1) 掃描整個關系;
(2) 點查詢(point query),如name = “hustcat”;
(3) 范圍查詢(range query),如 20 < age < 30。
不同的劃分技術,對這些存取類型的效率是不同的:
u 輪轉法適合順序掃描關系,對點查詢和范圍查詢的處理較復雜。
u 散列劃分特別適合點查詢,速度最快。
u 范圍劃分對點查詢、范圍查詢以及順序掃描都支持較好,所以適用性很廣。但是,這種方式存在一個問題——執行偏斜(execution skew),也就是說某些范圍的元組較多,使得大量的I/O出現在某幾個磁盤。
數據庫分區_百度百科.htm
Mysql數據庫分區 - xyliufeng的日志 - 網易博客.htm
理解MySQL——並行數據庫與分區(Partition) - YY哥 - 博客園.htm
創建,增加,刪除mysql表分區 - ndwx228的個人空間 - 開源中國社區.htm
數據庫學習之分區技術_Doraemonls_新浪博客.htm