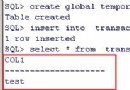
ORA-00604: error occurred at recursive SQL level 1
ORA-04031: unable to allocate 32 bytes of shared memory ("shared pool","select count(*) from sys.job...","sql area","tmp")
Mon Nov 2 11:43:00 2015
Errors in file /u01/app/oracle/admin/SCM2/bdump/scm2_cjq0_6571.trc:
ORA-00604: error occurred at recursive SQL level 1
ORA-04031: unable to allocate 32 bytes of shared memory ("shared pool","select job, nvl2(last_date, ...","sql area","tmp")
Mon Nov 2 11:43:00 2015
Errors in file /u01/app/oracle/admin/SCM2/bdump/scm2_cjq0_6571.trc:
ORA-00604: error occurred at recursive SQL level 1
ORA-04031: unable to allocate 32 bytes of shared memory ("shared pool","select count(*) from sys.job...","sql area","tmp")
Mon Nov 2 11:43:05 2015
Errors in file /u01/app/oracle/admin/SCM2/bdump/scm2_cjq0_6571.trc:
ORA-00604: error occurred at recursive SQL level 1
ORA-04031: unable to allocate 32 bytes of shared memory ("shared pool","select job, nvl2(last_date, ...","sql area","tmp")
Mon Nov 2 11:43:05 2015
Errors in file /u01/app/oracle/admin/SCM2/bdump/scm2_cjq0_6571.trc:
ORA-00604: error occurred at recursive SQL level 1
ORA-04031: unable to allocate 32 bytes of shared memory ("shared pool","select count(*) from sys.job...","sql area","tmp")
Mon Nov 2 11:43:08 2015
Errors in file /u01/app/oracle/admin/SCM2/bdump/scm2_reco_6569.trc:
ORA-04031: unable to allocate 32 bytes of shared memory ("shared pool","select host,userid,password,...","sql area","tmp")
Mon Nov 2 11:43:08 2015
RECO: terminating instance due to error 4031
Mon Nov 2 11:43:08 2015
Errors in file /u01/app/oracle/admin/SCM2/bdump/scm2_pmon_6555.trc:
ORA-04031: unable to allocate bytes of shared memory ("","","","")
Instance terminated by RECO, pid = 6569
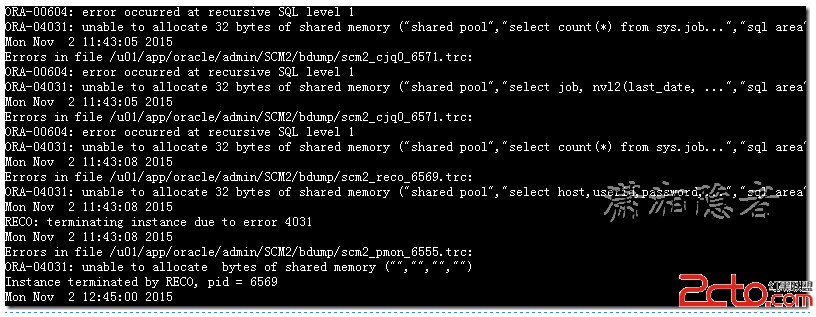 從告警日志我們可以看到ORA-00604與ORA-04031錯誤導致了這次宕機事故(RECO: terminating instance due to error 4031):
$ oerr ora 4031
04031, 00000, "unable to allocate %s bytes of shared memory (\"%s\",\"%s\",\"%s\",\"%s\")"
// *Cause: More shared memory is needed than was allocated in the shared
// pool.
// *Action: If the shared pool is out of memory, either use the
// dbms_shared_pool package to pin large packages,
// reduce your use of shared memory, or increase the amount of
// available shared memory by increasing the value of the
// INIT.ORA parameters "shared_pool_reserved_size" and
// "shared_pool_size".
// If the large pool is out of memory, increase the INIT.ORA
// parameter "large_pool_size".
一般出現ORA-04031錯誤可能由兩個原因引起:
1:內存中存在大量碎片,導致在分配內存的時候,沒有連續的內存可存放,此問題一般是需要在開發的角度上入手,比如增加綁定變量,減少硬解析來改善和避免;
2.內存容量不足,需要擴大內存。
這台機器分配的物理內存為8G,結果檢查發現SGA只分配了1168M,不到2G,瞬時碉堡了。此時真是很無語。ASH Report分析宕機前後的Buffer Cache和Shared Pool大小如下所示。
從告警日志我們可以看到ORA-00604與ORA-04031錯誤導致了這次宕機事故(RECO: terminating instance due to error 4031):
$ oerr ora 4031
04031, 00000, "unable to allocate %s bytes of shared memory (\"%s\",\"%s\",\"%s\",\"%s\")"
// *Cause: More shared memory is needed than was allocated in the shared
// pool.
// *Action: If the shared pool is out of memory, either use the
// dbms_shared_pool package to pin large packages,
// reduce your use of shared memory, or increase the amount of
// available shared memory by increasing the value of the
// INIT.ORA parameters "shared_pool_reserved_size" and
// "shared_pool_size".
// If the large pool is out of memory, increase the INIT.ORA
// parameter "large_pool_size".
一般出現ORA-04031錯誤可能由兩個原因引起:
1:內存中存在大量碎片,導致在分配內存的時候,沒有連續的內存可存放,此問題一般是需要在開發的角度上入手,比如增加綁定變量,減少硬解析來改善和避免;
2.內存容量不足,需要擴大內存。
這台機器分配的物理內存為8G,結果檢查發現SGA只分配了1168M,不到2G,瞬時碉堡了。此時真是很無語。ASH Report分析宕機前後的Buffer Cache和Shared Pool大小如下所示。
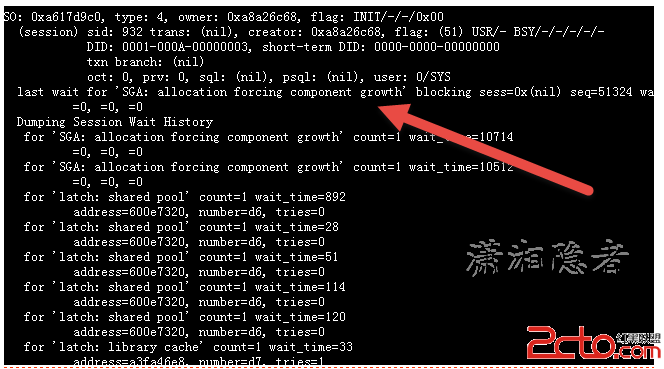
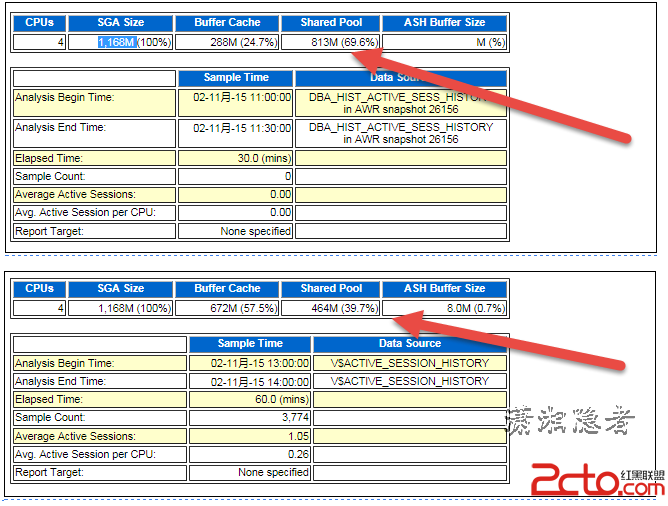 查看跟蹤文件,可以看到SGA: allocation forcing component growth等待事件,可以確認的是由於SGA無法增長導致,也就是SGA被撐爆了,結合ASH Report我們可以看到當時Shared Pool的大小已經接近SGA的69.6%大小。
查看跟蹤文件,可以看到SGA: allocation forcing component growth等待事件,可以確認的是由於SGA無法增長導致,也就是SGA被撐爆了,結合ASH Report我們可以看到當時Shared Pool的大小已經接近SGA的69.6%大小。
SO: 0xa617d9c0, type: 4, owner: 0xa8a26c68, flag: INIT/-/-/0x00
(session) sid: 932 trans: (nil), creator: 0xa8a26c68, flag: (51) USR/- BSY/-/-/-/-/-
DID: 0001-000A-00000003, short-term DID: 0000-0000-00000000
txn branch: (nil)
oct: 0, prv: 0, sql: (nil), psql: (nil), user: 0/SYS
last wait for 'SGA: allocation forcing component growth' blocking sess=0x(nil) seq=51324 wait_time=10714 seconds since wait started=0
=0, =0, =0
Dumping Session Wait History
for 'SGA: allocation forcing component growth' count=1 wait_time=10714
=0, =0, =0
for 'SGA: allocation forcing component growth' count=1 wait_time=10512
=0, =0, =0
for 'latch: shared pool' count=1 wait_time=892
address=600e7320, number=d6, tries=0
for 'latch: shared pool' count=1 wait_time=28
address=600e7320, number=d6, tries=0
for 'latch: shared pool' count=1 wait_time=51
address=600e7320, number=d6, tries=0
for 'latch: shared pool' count=1 wait_time=114
address=600e7320, number=d6, tries=0
for 'latch: shared pool' count=1 wait_time=120
address=600e7320, number=d6, tries=0
for 'latch: library cache' count=1 wait_time=33
address=a3fa46e8, number=d7, tries=1
SELECT start_time,
component,
oper_type,
oper_mode,
initial_size / 1024 / 1024 "INITIAL",
final_size / 1024 / 1024 "FINAL",
end_time
FROM v$sga_resize_ops
WHERE component IN ( 'DEFAULT buffer cache', 'shared pool' )
AND status = 'COMPLETE'
ORDER BY start_time,
component;
這個可以通過設置數據庫參數SHARED_POOL_SIZE,保證SHARED_POOL_SIZE大小不會由於內存緊張而低於這個大小,另外可以設置SGA resize的時間間隔 ALTER SYSTEM SET “_memory_broker_stat_interval”=n SCOPE=SPFILE; 問題雖然解決了,但是真正需要反思的是為什麼這個SGA_MAX_SIZE設置為1168M大小的事情!而且沒有在巡檢當中被發現。